import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
% matplotlib inline
df = pd. read_csv( 'data/2.lagou/lagou_recruitment.csv' )
df. head( )
Unnamed: 0 岗位名称 公司名称 城市 地点 薪资 基本要求 公司状况 岗位技能 公司福利 0 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 10k-20k 经验1-3年 / 本科 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 1 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 10k-20k 经验不限 / 本科 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好” 2 2 数据分析 51JOB 上海 [浦东新区] 8k-15k 8k-15k 经验1-3年 / 本科 移动互联网,企业服务 / 上市公司 / 2000人以上 SPSS 数据运营 数据库 “五险一金 周末双休 年终福利” 3 3 2521BK-数据分析师 陆金所 上海 [浦东新区] 13k-26k 13k-26k 经验1-3年 / 本科 金融 / B轮 / 2000人以上 大数据 金融 MySQL Oracle 算法 “五险一金,节日福利,带薪年假” 4 4 数据分析师 天天拍车 上海 [虹桥] 10k-15k 10k-15k 经验1-3年 / 大专 移动互联网,电商 / D轮及以上 / 2000人以上 数据分析 数据库 “五险一金,带薪年假,做五休二”
df. drop( columns= "Unnamed: 0" , inplace= True )
df. head( 2 )
岗位名称 公司名称 城市 地点 薪资 基本要求 公司状况 岗位技能 公司福利 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 10k-20k 经验1-3年 / 本科 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 10k-20k 经验不限 / 本科 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好”
pd. read_csv( 'data/2.lagou/lagou_recruitment.csv' , index_col= 0 ) . head( 2 )
岗位名称 公司名称 城市 地点 薪资 基本要求 公司状况 岗位技能 公司福利 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 10k-20k 经验1-3年 / 本科 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 10k-20k 经验不限 / 本科 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好”
df. shape
(1638, 9)
df. columns
Index(['岗位名称', '公司名称', '城市', '地点', '薪资', '基本要求', '公司状况', '岗位技能', '公司福利'], dtype='object')
df. info( )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1638 entries, 0 to 1637
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 岗位名称 1638 non-null object
1 公司名称 1638 non-null object
2 城市 1638 non-null object
3 地点 1638 non-null object
4 薪资 1638 non-null object
5 基本要求 1638 non-null object
6 公司状况 1638 non-null object
7 岗位技能 1637 non-null object
8 公司福利 1638 non-null object
dtypes: object(9)
memory usage: 115.3+ KB
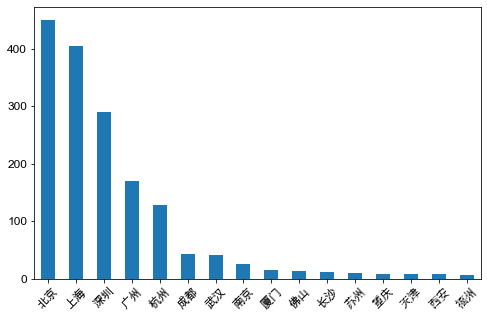
city_num = df. 城市. value_counts( )
city_num
北京 450
上海 405
深圳 291
广州 170
杭州 128
成都 43
武汉 42
南京 26
厦门 16
佛山 13
长沙 12
苏州 10
重庆 9
天津 8
西安 8
福州 7
Name: 城市, dtype: int64
plt. rcParams[ 'font.family' ] = [ 'simhei' ]
plt. rcParams[ 'font.family' ] = [ 'Arial Unicode MS' ]
city_num. plot( kind= 'bar'
, figsize= ( 8 , 5 )
, fontsize= 12
, rot= 45
) ;
from pyecharts. charts import Bar
from pyecharts import options as opts
list ( city_num. index)
['北京',
'上海',
'深圳',
'广州',
'杭州',
'成都',
'武汉',
'南京',
'厦门',
'佛山',
'长沙',
'苏州',
'重庆',
'天津',
'西安',
'福州']
b = Bar( )
b. add_xaxis( list ( city_num. index) )
b. add_yaxis( '工作数量' , list ( city_num) )
b. set_global_opts( title_opts= opts. TitleOpts( title= "数据分析工作地区分布" ) )
b. render( '数据分析工作地区分布_1.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\数据分析工作地区分布_1.html'
from pyecharts import options as opts
from pyecharts. charts import Geo
city_num. to_dict( ) . items( )
dict_items([('北京', 450), ('上海', 405), ('深圳', 291), ('广州', 170), ('杭州', 128), ('成都', 43), ('武汉', 42), ('南京', 26), ('厦门', 16), ('佛山', 13), ('长沙', 12), ('苏州', 10), ('重庆', 9), ('天津', 8), ('西安', 8), ('福州', 7)])
list ( zip ( city_num. index, city_num. values) )
[('北京', 450),
('上海', 405),
('深圳', 291),
('广州', 170),
('杭州', 128),
('成都', 43),
('武汉', 42),
('南京', 26),
('厦门', 16),
('佛山', 13),
('长沙', 12),
('苏州', 10),
('重庆', 9),
('天津', 8),
('西安', 8),
('福州', 7)]
c = Geo( )
c. add_schema( maptype= 'china' )
city_num_dict = city_num. to_dict( )
city_num_dict. items( )
c. add( '城市工作数量' , city_num_dict. items( ) )
c. set_series_opts( label_opts= opts. LabelOpts( is_show= False ) )
c. set_global_opts( visualmap_opts= opts. VisualMapOpts( )
, title_opts= opts. TitleOpts( title= "城市标记" ) )
c. render( '全国城市工作数量_1.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\全国城市工作数量_1.html'
df. shape
df. duplicated( ) . sum ( )
df[ df. duplicated( ) ]
df. drop_duplicates( inplace= True )
df. shape
(1609, 9)
df. head( 2 )
岗位名称 公司名称 城市 地点 薪资 基本要求 公司状况 岗位技能 公司福利 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 10k-20k 经验1-3年 / 本科 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 10k-20k 经验不限 / 本科 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好”
temp = df. 基本要求. str . split( '/' )
df[ '工作年限' ] = temp. map ( lambda x: x[ 0 ] )
df[ '学历要求' ] = temp. map ( lambda x: x[ 1 ] )
df. head( )
岗位名称 公司名称 城市 地点 薪资 基本要求 公司状况 岗位技能 公司福利 工作年限 学历要求 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 10k-20k 经验1-3年 / 本科 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 10k-20k 经验1-3年 本科 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 10k-20k 经验不限 / 本科 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好” 10k-20k 经验不限 本科 2 数据分析 51JOB 上海 [浦东新区] 8k-15k 8k-15k 经验1-3年 / 本科 移动互联网,企业服务 / 上市公司 / 2000人以上 SPSS 数据运营 数据库 “五险一金 周末双休 年终福利” 8k-15k 经验1-3年 本科 3 2521BK-数据分析师 陆金所 上海 [浦东新区] 13k-26k 13k-26k 经验1-3年 / 本科 金融 / B轮 / 2000人以上 大数据 金融 MySQL Oracle 算法 “五险一金,节日福利,带薪年假” 13k-26k 经验1-3年 本科 4 数据分析师 天天拍车 上海 [虹桥] 10k-15k 10k-15k 经验1-3年 / 大专 移动互联网,电商 / D轮及以上 / 2000人以上 数据分析 数据库 “五险一金,带薪年假,做五休二” 10k-15k 经验1-3年 大专
df. rename( columns= { '基本要求' : '公司要求' } , inplace= True )
df. head( 2 )
岗位名称 公司名称 城市 地点 薪资 公司要求 公司状况 岗位技能 公司福利 工作年限 学历要求 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 10k-20k 经验1-3年 / 本科 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 10k-20k 经验1-3年 本科 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 10k-20k 经验不限 / 本科 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好” 10k-20k 经验不限 本科
df[ '公司要求' ] . values[ 0 ] . split( ' ' ) [ 3 ]
'本科'
temp = df. 公司要求. str . split( ' ' )
temp[ : 5 ]
0 [10k-20k, 经验1-3年, /, 本科]
1 [10k-20k, 经验不限, /, 本科]
2 [8k-15k, 经验1-3年, /, 本科]
3 [13k-26k, 经验1-3年, /, 本科]
4 [10k-15k, 经验1-3年, /, 大专]
Name: 公司要求, dtype: object
df[ '工作年限' ] = temp. map ( lambda x : x[ 1 ] )
df[ '学历要求' ] = temp. apply ( lambda x : x[ - 1 ] )
df. pop( '公司要求' )
df. head( 2 )
岗位名称 公司名称 城市 地点 薪资 公司状况 岗位技能 公司福利 工作年限 学历要求 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 移动互联网 / D轮及以上 / 150-500人 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k 金融 / 上市公司 / 500-2000人 SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科
df. 公司状况
0 移动互联网 / D轮及以上 / 150-500人
1 金融 / 上市公司 / 500-2000人
2 移动互联网,企业服务 / 上市公司 / 2000人以上
3 金融 / B轮 / 2000人以上
4 移动互联网,电商 / D轮及以上 / 2000人以上
...
1633 数据服务,硬件 / A轮 / 15-50人
1634 移动互联网,消费生活 / 未融资 / 15-50人
1635 文娱丨内容 / 上市公司 / 500-2000人
1636 移动互联网 / 未融资 / 500-2000人
1637 移动互联网,金融 / 不需要融资 / 2000人以上
Name: 公司状况, Length: 1609, dtype: object
df[ [ '行业' , '融资' , '人数' ] ] = df. 公司状况. str . split( '/ ' , expand = True )
del df[ '公司状况' ]
df. head( )
岗位名称 公司名称 城市 地点 薪资 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 0 数据分析师 名片全能王 上海 [静安区] 10k-20k 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 1 数据分析师 奇虎360金融 上海 [张江] 10k-20k SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人 2 数据分析 51JOB 上海 [浦东新区] 8k-15k SPSS 数据运营 数据库 “五险一金 周末双休 年终福利” 经验1-3年 本科 移动互联网,企业服务 上市公司 2000人以上 3 2521BK-数据分析师 陆金所 上海 [浦东新区] 13k-26k 大数据 金融 MySQL Oracle 算法 “五险一金,节日福利,带薪年假” 经验1-3年 本科 金融 B轮 2000人以上 4 数据分析师 天天拍车 上海 [虹桥] 10k-15k 数据分析 数据库 “五险一金,带薪年假,做五休二” 经验1-3年 大专 移动互联网,电商 D轮及以上 2000人以上
import matplotlib
matplotlib. __version__
pd. __version__
'1.0.5'
df. 地点 = df. 地点. str . replace( '[' , '' ) . str . replace( ']' , '' )
df. head( 2 )
岗位名称 公司名称 城市 地点 薪资 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 0 数据分析师 名片全能王 上海 静安区 10k-20k 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 1 数据分析师 奇虎360金融 上海 张江 10k-20k SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人
df. 薪资. values
array(['10k-20k', '10k-20k', '8k-15k', ..., '6k-7k', '10k-15k', '4k-6k'],
dtype=object)
temp = df. 薪资. str . replace( 'k' , '000' ) . str . replace( 'K' , '000' )
df[ [ '最高薪资' , '最低薪资' ] ] = temp. str . split( '-' , expand = True )
df. info( )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1609 entries, 0 to 1637
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 岗位名称 1609 non-null object
1 公司名称 1609 non-null object
2 城市 1609 non-null object
3 地点 1609 non-null object
4 薪资 1609 non-null object
5 岗位技能 1608 non-null object
6 公司福利 1609 non-null object
7 工作年限 1609 non-null object
8 学历要求 1609 non-null object
9 行业 1609 non-null object
10 融资 1609 non-null object
11 人数 1609 non-null object
12 最高薪资 1609 non-null object
13 最低薪资 1609 non-null object
dtypes: object(14)
memory usage: 188.6+ KB
df. 最低薪资 = df. 最低薪资. astype( 'int64' )
df. 最高薪资 = df. 最高薪资. astype( 'int64' )
df. 平均薪资= ( df. 最高薪资+ df. 最低薪资) / 2
<ipython-input-385-af442a3562ba>:3: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access
df.平均薪资=(df.最高薪资+df.最低薪资)/2
df. 薪资. value_counts( )
temp = df. 薪资. str . replace( 'k' , '000' ) . str . replace( 'K' , '000' )
df[ '最低薪资' ] = temp. str . split( '-' ) . map ( lambda x: x[ 0 ] )
df[ '最高薪资' ] = temp. str . split( '-' ) . map ( lambda x: x[ 1 ] )
df. info( )
df. head( 2 )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1609 entries, 0 to 1637
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 岗位名称 1609 non-null object
1 公司名称 1609 non-null object
2 城市 1609 non-null object
3 地点 1609 non-null object
4 薪资 1609 non-null object
5 岗位技能 1608 non-null object
6 公司福利 1609 non-null object
7 工作年限 1609 non-null object
8 学历要求 1609 non-null object
9 行业 1609 non-null object
10 融资 1609 non-null object
11 人数 1609 non-null object
12 最高薪资 1609 non-null object
13 最低薪资 1609 non-null object
dtypes: object(14)
memory usage: 188.6+ KB
岗位名称 公司名称 城市 地点 薪资 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 0 数据分析师 名片全能王 上海 静安区 10k-20k 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 1 数据分析师 奇虎360金融 上海 张江 10k-20k SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人 20000 10000
df. 最低薪资 = df. 最低薪资. astype( 'int64' )
df. 最高薪资 = df. 最高薪资. astype( 'int64' )
df. info( )
df. head( 2 )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1609 entries, 0 to 1637
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 岗位名称 1609 non-null object
1 公司名称 1609 non-null object
2 城市 1609 non-null object
3 地点 1609 non-null object
4 薪资 1609 non-null object
5 岗位技能 1608 non-null object
6 公司福利 1609 non-null object
7 工作年限 1609 non-null object
8 学历要求 1609 non-null object
9 行业 1609 non-null object
10 融资 1609 non-null object
11 人数 1609 non-null object
12 最高薪资 1609 non-null int64
13 最低薪资 1609 non-null int64
dtypes: int64(2), object(12)
memory usage: 188.6+ KB
岗位名称 公司名称 城市 地点 薪资 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 0 数据分析师 名片全能王 上海 静安区 10k-20k 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 1 数据分析师 奇虎360金融 上海 张江 10k-20k SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人 20000 10000
df[ '平均薪资' ] = ( df. 最低薪资 + df. 最高薪资) / 2
df. pop( '薪资' )
df. head( 2 )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 0 数据分析师 名片全能王 上海 静安区 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 15000.0 1 数据分析师 奇虎360金融 上海 张江 SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人 20000 10000 15000.0
df. describe( )
最高薪资 最低薪资 平均薪资 count 1609.000000 1609.000000 1609.000000 mean 24277.812306 14047.855811 19162.834058 std 12365.415226 7020.373474 9572.235760 min 1000.000000 1000.000000 1000.000000 25% 15000.000000 10000.000000 12500.000000 50% 25000.000000 15000.000000 20000.000000 75% 30000.000000 18000.000000 24000.000000 max 100000.000000 60000.000000 75000.000000
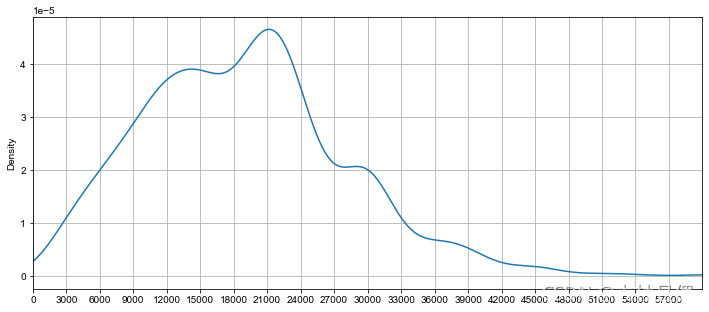
df. 平均薪资. plot( kind= 'density' , grid= True , figsize= ( 12 , 5 )
, xlim= ( 0 , 60000 )
, xticks= np. arange( 0 , 60000 , 3000 )
) ;
city_salary = df. groupby( by= '城市' ) . mean( )
df. groupby( '城市' ) . mean( )
最高薪资 最低薪资 平均薪资 城市 上海 25545.679012 14676.543210 20111.111111 佛山 25076.923077 14000.000000 19538.461538 北京 27649.411765 15957.647059 21803.529412 南京 17653.846154 10615.384615 14134.615385 厦门 22062.500000 12437.500000 17250.000000 天津 12750.000000 8250.000000 10500.000000 广州 19841.176471 11670.588235 15755.882353 成都 15000.000000 8837.209302 11918.604651 杭州 22906.250000 13656.250000 18281.250000 武汉 17476.190476 10190.476190 13833.333333 深圳 25756.097561 14714.285714 20235.191638 福州 15000.000000 8428.571429 11714.285714 苏州 18400.000000 10700.000000 14550.000000 西安 11500.000000 7375.000000 9437.500000 重庆 13888.888889 7888.888889 10888.888889 长沙 12000.000000 7916.666667 9958.333333
city_salary[ : 5 ]
最高薪资 最低薪资 平均薪资 城市 上海 25545.679012 14676.543210 20111.111111 佛山 25076.923077 14000.000000 19538.461538 北京 27649.411765 15957.647059 21803.529412 南京 17653.846154 10615.384615 14134.615385 厦门 22062.500000 12437.500000 17250.000000
city_salary. sort_values( '平均薪资' , ascending= False )
最高薪资 最低薪资 平均薪资 城市 北京 27649.411765 15957.647059 21803.529412 深圳 25756.097561 14714.285714 20235.191638 上海 25545.679012 14676.543210 20111.111111 佛山 25076.923077 14000.000000 19538.461538 杭州 22906.250000 13656.250000 18281.250000 厦门 22062.500000 12437.500000 17250.000000 广州 19841.176471 11670.588235 15755.882353 苏州 18400.000000 10700.000000 14550.000000 南京 17653.846154 10615.384615 14134.615385 武汉 17476.190476 10190.476190 13833.333333 成都 15000.000000 8837.209302 11918.604651 福州 15000.000000 8428.571429 11714.285714 重庆 13888.888889 7888.888889 10888.888889 天津 12750.000000 8250.000000 10500.000000 长沙 12000.000000 7916.666667 9958.333333 西安 11500.000000 7375.000000 9437.500000
city_list = city_salary. sort_values( '平均薪资' , ascending= False ) . index
city_list
Index(['北京', '深圳', '上海', '佛山', '杭州', '厦门', '广州', '苏州', '南京', '武汉', '成都', '福州',
'重庆', '天津', '长沙', '西安'],
dtype='object', name='城市')
df. groupby( by= '城市' ) [ '平均薪资' ] . agg( [ 'max' , 'min' , 'median' , 'mean' ] )
max min median mean 城市 上海 75000.0 1500.0 20000.0 20111.111111 佛山 37500.0 10500.0 17500.0 19538.461538 北京 65000.0 3000.0 22000.0 21803.529412 南京 45000.0 2500.0 12500.0 14134.615385 厦门 31500.0 7000.0 15000.0 17250.000000 天津 17500.0 6000.0 9750.0 10500.000000 广州 40000.0 2500.0 15000.0 15755.882353 成都 30000.0 2500.0 11500.0 11918.604651 杭州 70000.0 3000.0 17000.0 18281.250000 武汉 30000.0 2500.0 12500.0 13833.333333 深圳 65000.0 1000.0 20000.0 20235.191638 福州 20000.0 7000.0 11500.0 11714.285714 苏州 30000.0 7500.0 11750.0 14550.000000 西安 17500.0 4000.0 8000.0 9437.500000 重庆 22500.0 5000.0 8000.0 10888.888889 长沙 14000.0 5000.0 10750.0 9958.333333
from pyecharts. charts import Boxplot
df[ df. 城市 == "北京" ] [ '平均薪资' ]
418 14000.0
419 18000.0
420 14000.0
421 10500.0
422 20000.0
...
863 30000.0
864 20000.0
865 30000.0
866 45000.0
867 9000.0
Name: 平均薪资, Length: 425, dtype: float64
beijing = df[ df. 城市 == "北京" ] [ '平均薪资' ]
shanghai = df[ df. 城市 == "上海" ] [ '平均薪资' ]
guangzhou = df[ df. 城市 == "广州" ] [ '平均薪资' ]
shenzhen = df[ df. 城市 == "深圳" ] [ '平均薪资' ]
box = Boxplot( )
box. add_xaxis( [ '北京' , '上海' , '广州' , '深圳' ] )
box. add_yaxis( "平均薪资" , box. prepare_data( [ beijing, shanghai, guangzhou, shenzhen] ) )
box. set_global_opts( title_opts= opts. TitleOpts( title= "四大城市平均薪资分布" ) )
box. render( '四大城市平均薪资箱线图.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\四大城市平均薪资箱线图.html'
temp_list = [ ]
for i in city_list:
temp_list. append( df[ df. 城市 == i] [ '平均薪资' ] )
box = Boxplot( )
box. add_xaxis( list ( city_list) )
box. add_yaxis( "平均薪资" , box. prepare_data( temp_list) )
box. set_global_opts( title_opts= opts. TitleOpts( title= "所有城市平均薪资分布" ) )
box. render( '所有城市平均薪资箱线图.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\所有城市平均薪资箱线图.html'
beijing[ : 2 ]
418 14000.0
419 18000.0
Name: 平均薪资, dtype: float64
box. prepare_data( [ beijing, shanghai, guangzhou, shenzhen] )
[[3000.0, 16000.0, 22000.0, 26500.0, 65000.0],
[1500.0, 14000.0, 20000.0, 25000.0, 75000.0],
[2500.0, 9500.0, 15000.0, 20000.0, 40000.0],
[1000.0, 12500.0, 20000.0, 24000.0, 65000.0]]
city_salary = df. groupby( by= '城市' ) . mean( )
city_list = city_salary. sort_values( '平均薪资' , ascending= False ) . index
temp = [ ]
for i in city_list:
print ( i)
temp. append( df[ df. 城市 == i] [ '平均薪资' ] )
北京
深圳
上海
佛山
杭州
厦门
广州
苏州
南京
武汉
成都
福州
重庆
天津
长沙
西安
len ( temp)
16
temp[ : 3 ]
[418 14000.0
419 18000.0
420 14000.0
421 10500.0
422 20000.0
...
863 30000.0
864 20000.0
865 30000.0
866 45000.0
867 9000.0
Name: 平均薪资, Length: 425, dtype: float64,
1301 15000.0
1302 12000.0
1303 12000.0
1304 16500.0
1305 22500.0
...
1587 37500.0
1588 47500.0
1589 22500.0
1590 40000.0
1591 25000.0
Name: 平均薪资, Length: 287, dtype: float64,
0 15000.0
1 15000.0
2 11500.0
3 19500.0
4 12500.0
...
400 20000.0
401 22500.0
402 30000.0
403 10500.0
404 25000.0
Name: 平均薪资, Length: 405, dtype: float64]
box. prepare_data( temp)
[[3000.0, 16000.0, 22000.0, 26500.0, 65000.0],
[1000.0, 12500.0, 20000.0, 24000.0, 65000.0],
[1500.0, 14000.0, 20000.0, 25000.0, 75000.0],
[10500.0, 11500.0, 17500.0, 25750.0, 37500.0],
[3000.0, 11500.0, 17000.0, 24625.0, 70000.0],
[7000.0, 11625.0, 15000.0, 21875.0, 31500.0],
[2500.0, 9500.0, 15000.0, 20000.0, 40000.0],
[7500.0, 9125.0, 11750.0, 18500.0, 30000.0],
[2500.0, 9750.0, 12500.0, 17875.0, 45000.0],
[2500.0, 9000.0, 12500.0, 16750.0, 30000.0],
[2500.0, 8500.0, 11500.0, 15000.0, 30000.0],
[7000.0, 8000.0, 11500.0, 15000.0, 20000.0],
[5000.0, 5750.0, 8000.0, 17750.0, 22500.0],
[6000.0, 8500.0, 9750.0, 12250.0, 17500.0],
[5000.0, 6875.0, 10750.0, 12500.0, 14000.0],
[4000.0, 5875.0, 8000.0, 12875.0, 17500.0]]
np. array( box. prepare_data( temp) ) . shape
(16, 5)
box = Boxplot( )
box. add_xaxis( list ( city_list) )
box. add_yaxis( "平均薪资" , box. prepare_data( temp) )
box. set_global_opts( title_opts= opts. TitleOpts( title= "所有城市平均薪资分布" ) )
box. render( '所有城市平均薪资箱线图.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\所有城市平均薪资箱线图.html'
df. head( 2 )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 0 数据分析师 名片全能王 上海 静安区 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 15000.0 1 数据分析师 奇虎360金融 上海 张江 SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人 20000 10000 15000.0
work_list = df. 工作年限. value_counts( ) . index[ : - 1 ]
temp_list = [ ]
for i in work_list:
temp_list. append( df[ df. 工作年限 == i] [ '平均薪资' ] )
box = Boxplot( )
box. add_xaxis( list ( work_list) )
box. add_yaxis( "平均薪资" , box. prepare_data( temp_list ) )
box. set_global_opts( title_opts= opts. TitleOpts( title= "所有城市平均薪资分布" ) )
box. render( '所有城市平均薪资箱线图.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\所有城市平均薪资箱线图.html'
df. 工作年限. value_counts( )
经验3-5年 673
经验1-3年 432
经验5-10年 221
经验不限 178
经验应届毕业生 75
经验1年以下 28
经验10年以上 2
Name: 工作年限, dtype: int64
temp = df. 工作年限. value_counts( ) . index
temp
Index(['经验3-5年', '经验1-3年', '经验5-10年', '经验不限', '经验应届毕业生', '经验1年以下', '经验10年以上'], dtype='object')
df[ df. 工作年限 == temp[ 0 ] ] [ '平均薪资' ]
empty = [ ]
for i in temp:
print ( i)
empty. append( df[ df. 工作年限 == i] [ '平均薪资' ] )
empty[ 1 ]
经验3-5年
经验1-3年
经验5-10年
经验不限
经验应届毕业生
经验1年以下
经验10年以上
0 15000.0
2 11500.0
3 19500.0
4 12500.0
6 10000.0
...
1626 11500.0
1628 9000.0
1629 10000.0
1635 6500.0
1636 12500.0
Name: 平均薪资, Length: 432, dtype: float64
box = Boxplot( )
box. add_xaxis( list ( temp) )
box. add_yaxis( "平均薪资" , box. prepare_data( empty) )
box. reversal_axis( )
box. set_global_opts( title_opts= opts. TitleOpts( title= "工作年限平均薪资分布" ) )
box. render( '工作年限平均薪资箱线图.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\工作年限平均薪资箱线图.html'
df[ df[ '工作年限' ] == '经验10年以上' ]
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 1241 商业数据分析总监 网易 杭州 长河 电商 移动互联网 SQLServer Hive 数据分析 算法 “跨境电商,薪酬有竞争力” 经验10年以上 本科 电商 上市公司 2000人以上 80000 60000 70000.0 1414 4721FP-智慧法律-资深数据分析专家 平安智慧城 深圳 南山区 数据分析 “五险一金,绩效奖金,高温补贴,定期体检” 经验10年以上 本科 移动互联网 不需要融资 2000人以上 30000 15000 22500.0
max_salary = df. groupby( by= '城市' ) [ '平均薪资' ] . min ( )
df_res = pd. DataFrame( )
for i, j in max_salary. to_dict( ) . items( ) :
temp_series = df[ ( df[ "城市" ] == i) & ( df[ "平均薪资" ] == j) ]
df_res = pd. concat( [ df_res, temp_series] , axis= 0 )
max_salary. sort_values( ascending= False , inplace= True )
max_salary
城市
佛山 10500.0
苏州 7500.0
福州 7000.0
厦门 7000.0
天津 6000.0
长沙 5000.0
重庆 5000.0
西安 4000.0
杭州 3000.0
北京 3000.0
武汉 2500.0
成都 2500.0
广州 2500.0
南京 2500.0
上海 1500.0
深圳 1000.0
Name: 平均薪资, dtype: float64
max_salary. index
Index(['佛山', '苏州', '福州', '厦门', '天津', '长沙', '重庆', '西安', '杭州', '北京', '武汉', '成都',
'广州', '南京', '上海', '深圳'],
dtype='object', name='城市')
max_salary. values
array([10500., 7500., 7000., 7000., 6000., 5000., 5000., 4000.,
3000., 3000., 2500., 2500., 2500., 2500., 1500., 1000.])
df. 平均薪资 == 75000 .
0 False
1 False
2 False
3 False
4 False
...
1633 False
1634 False
1635 False
1636 False
1637 False
Length: 1609, dtype: bool
df. 城市 == '上海'
0 True
1 True
2 True
3 True
4 True
...
1633 False
1634 False
1635 False
1636 False
1637 False
Name: 城市, Length: 1609, dtype: bool
( ( df. 城市 == '上海' ) & ( df. 平均薪资 == 75000 . ) ) . sum ( )
1
df[ ( df. 城市 == '上海' ) & ( df. 平均薪资 == 75000 . ) ]
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 367 高级数据分析总监 靖琪 上海 虹口区 电商 工具软件 “公司实力强,成长空间大,福利待遇好” 经验5-10年 本科 移动互联网 天使轮 50-150人 100000 50000 75000.0
list ( zip ( max_salary. index, max_salary. values) )
[('佛山', 10500.0),
('苏州', 7500.0),
('福州', 7000.0),
('厦门', 7000.0),
('天津', 6000.0),
('长沙', 5000.0),
('重庆', 5000.0),
('西安', 4000.0),
('杭州', 3000.0),
('北京', 3000.0),
('武汉', 2500.0),
('成都', 2500.0),
('广州', 2500.0),
('南京', 2500.0),
('上海', 1500.0),
('深圳', 1000.0)]
[ * zip ( max_salary. index, max_salary. values) ]
[('佛山', 10500.0),
('苏州', 7500.0),
('福州', 7000.0),
('厦门', 7000.0),
('天津', 6000.0),
('长沙', 5000.0),
('重庆', 5000.0),
('西安', 4000.0),
('杭州', 3000.0),
('北京', 3000.0),
('武汉', 2500.0),
('成都', 2500.0),
('广州', 2500.0),
('南京', 2500.0),
('上海', 1500.0),
('深圳', 1000.0)]
df_m = pd. DataFrame( )
for i, j in zip ( max_salary. index, max_salary. values) :
df_c = df[ ( df. 城市== i) & ( df. 平均薪资== j) ]
df_m = pd. concat( [ df_m, df_c] )
df_m. head( 2 )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 409 数据分析师 美的电商 佛山 顺德区 电商 大数据 数据分析 数据运营 SPSS 商业 “不打卡 团队年轻 领导nice” 经验3-5年 本科 电商 上市公司 2000人以上 13000 8000 10500.0 1608 数据分析师 迈科网络 苏州 工业园区 通信/网络设备 “公司核心技术岗位,发展空间大” 经验1年以下 本科 数据服务 上市公司 15-50人 10000 5000 7500.0
min_salary = df. groupby( '城市' ) [ '平均薪资' ] . min ( )
min_salary
list ( zip ( min_salary. index, min_salary. values) )
df_res = pd. DataFrame( )
for i, j in zip ( min_salary. index, min_salary. values) :
temp_series = df[ ( df. 城市 == i) & ( df. 平均薪资 == j) ]
df_res = pd. concat( [ df_res, temp_series] , axis = 0 )
min_salary. to_dict( ) . items( )
dict_items([('上海', 1500.0), ('佛山', 10500.0), ('北京', 3000.0), ('南京', 2500.0), ('厦门', 7000.0), ('天津', 6000.0), ('广州', 2500.0), ('成都', 2500.0), ('杭州', 3000.0), ('武汉', 2500.0), ('深圳', 1000.0), ('福州', 7000.0), ('苏州', 7500.0), ('西安', 4000.0), ('重庆', 5000.0), ('长沙', 5000.0)])
min_salary = df. groupby( '城市' ) [ '平均薪资' ] . min ( )
min_salary. sort_values( ascending= False , inplace= True )
df_t = pd. DataFrame( )
for i, j in zip ( min_salary. index, min_salary. values) :
df_one = df[ ( df. 城市== i) & ( df. 平均薪资== j) ]
df_t = pd. concat( [ df_t, df_one] )
df_t. shape
(24, 14)
df_t. head( )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 409 数据分析师 美的电商 佛山 顺德区 电商 大数据 数据分析 数据运营 SPSS 商业 “不打卡 团队年轻 领导nice” 经验3-5年 本科 电商 上市公司 2000人以上 13000 8000 10500.0 1608 数据分析师 迈科网络 苏州 工业园区 通信/网络设备 “公司核心技术岗位,发展空间大” 经验1年以下 本科 数据服务 上市公司 15-50人 10000 5000 7500.0 1596 数据分析师 戎易商智(北京)科技有限公司 福州 五四路 移动互联网 SQL 数据库 数据分析 SPSS “周末双休,五险一金,员工旅游,生日福利” 经验1-3年 本科 移动互联网,数据服务 未融资 15-50人 8000 6000 7000.0 906 软件开发工程师(数据分析) 福建天闻 厦门 集美区 大数据 “五险一金、带薪年假” 经验1-3年 本科 数据服务,教育 未融资 15-50人 8000 6000 7000.0 916 金融数据分析师 投中信息 天津 滨海新区 VC 数据分析 行业研究 分析师 “全勤奖 饭补 车补 下午茶 年终奖” 经验不限 本科 金融 D轮及以上 150-500人 8000 4000 6000.0
def func ( data, column) :
high = data[ column] . mean( ) + 3 * data[ column] . std( )
low = data[ column] . mean( ) - 3 * data[ column] . std( )
res_df = data[ ( data[ column] > high) | ( data[ column] < low) ]
return res_df
func( df, "平均薪资" )
func( df, "最高薪资" )
func( df, '最低薪资' )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 147 数据分析与建模专家 招商银行信用卡中心 上海 浦东新区 数据分析 数据架构 “职位晋升 福利待遇好 工作氛围好” 经验5-10年 本科 金融 上市公司 2000人以上 65000 40000 52500.0 364 安全数据分析平台高级开发工程师 上海瑞阙文化发展有限公司 上海 黄浦区 安全 “弹性工作,提供晚餐” 经验1-3年 本科 移动互联网,金融 不需要融资 150-500人 80000 40000 60000.0 367 高级数据分析总监 靖琪 上海 虹口区 电商 工具软件 “公司实力强,成长空间大,福利待遇好” 经验5-10年 本科 移动互联网 天使轮 50-150人 100000 50000 75000.0 744 数据分析师/数据科学家 滴滴 北京 西北旺 Hadoop 数据挖掘 MySQL “数据精确,老大nb,汇报线简单” 经验5-10年 本科 汽车丨出行 不需要融资 2000人以上 60000 40000 50000.0 762 数据分析总监 发现旅行 北京 朝阳区 数据分析 “扁平化管理,氛围超好,地位重要,待遇优厚” 经验5-10年 本科 旅游 B轮 50-150人 80000 50000 65000.0 1206 数据分析总监 多准大数据 杭州 西溪 大数据 电商 数据分析 “缴纳五险一金,带薪年假,出国旅游,培训” 经验5-10年 本科 数据服务,广告营销 A轮 50-150人 50000 40000 45000.0 1241 商业数据分析总监 网易 杭州 长河 电商 移动互联网 SQLServer Hive 数据分析 算法 “跨境电商,薪酬有竞争力” 经验10年以上 本科 电商 上市公司 2000人以上 80000 60000 70000.0 1450 数据分析总监 深圳白骑士大数据有限公司 深圳 科技园 金融 算法 数据挖掘 数据分析 “平台好,创新型,发展迅速,股权期权” 经验5-10年 硕士 企业服务,金融 A轮 50-150人 65000 38000 51500.0 1455 资深数据分析师(J11772) 货拉拉 深圳 上梅林 BI 商业 数据分析 “发展空间大” 经验5-10年 本科 移动互联网,消费生活 C轮 2000人以上 70000 50000 60000.0 1504 商业数据分析师 (003969) vivo 深圳 宝安区 移动互联网 “弹性工作,股票期权,大数据平台 千万用户” 经验3-5年 本科 硬件 未融资 2000人以上 80000 50000 65000.0 1512 数据分析高级工程师 腾讯 深圳 前海 数据分析 Hadoop Spark 数据挖掘 “腾讯平台 福利待遇好 技术成长” 经验3-5年 本科 社交 上市公司 2000人以上 70000 40000 55000.0 1514 商业数据分析师 vivo 深圳 宝安区 移动互联网 “股票期权,精英团队,弹性工作” 经验3-5年 本科 硬件 未融资 2000人以上 80000 50000 65000.0 1538 数据分析总监 万顺赢 深圳 科技园 医疗健康 工具软件 “中国知名企业,福利好” 经验5-10年 硕士 移动互联网,金融 未融资 150-500人 80000 45000 62500.0
a = df. 平均薪资. mean( ) + 3 * df. 平均薪资. std( )
a
47879.54133696899
b = df. 平均薪资. mean( ) - 3 * df. 平均薪资. std( )
b
-9553.873220126236
df[ df. 平均薪资 > a]
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 147 数据分析与建模专家 招商银行信用卡中心 上海 浦东新区 数据分析 数据架构 “职位晋升 福利待遇好 工作氛围好” 经验5-10年 本科 金融 上市公司 2000人以上 65000 40000 52500.0 201 数据分析leader 上海腾聘 上海 张江 移动互联网 “发展空间,薪资给力,期权” 经验5-10年 本科 移动互联网,数据服务 B轮 50-150人 65000 35000 50000.0 364 安全数据分析平台高级开发工程师 上海瑞阙文化发展有限公司 上海 黄浦区 安全 “弹性工作,提供晚餐” 经验1-3年 本科 移动互联网,金融 不需要融资 150-500人 80000 40000 60000.0 367 高级数据分析总监 靖琪 上海 虹口区 电商 工具软件 “公司实力强,成长空间大,福利待遇好” 经验5-10年 本科 移动互联网 天使轮 50-150人 100000 50000 75000.0 744 数据分析师/数据科学家 滴滴 北京 西北旺 Hadoop 数据挖掘 MySQL “数据精确,老大nb,汇报线简单” 经验5-10年 本科 汽车丨出行 不需要融资 2000人以上 60000 40000 50000.0 762 数据分析总监 发现旅行 北京 朝阳区 数据分析 “扁平化管理,氛围超好,地位重要,待遇优厚” 经验5-10年 本科 旅游 B轮 50-150人 80000 50000 65000.0 1241 商业数据分析总监 网易 杭州 长河 电商 移动互联网 SQLServer Hive 数据分析 算法 “跨境电商,薪酬有竞争力” 经验10年以上 本科 电商 上市公司 2000人以上 80000 60000 70000.0 1450 数据分析总监 深圳白骑士大数据有限公司 深圳 科技园 金融 算法 数据挖掘 数据分析 “平台好,创新型,发展迅速,股权期权” 经验5-10年 硕士 企业服务,金融 A轮 50-150人 65000 38000 51500.0 1455 资深数据分析师(J11772) 货拉拉 深圳 上梅林 BI 商业 数据分析 “发展空间大” 经验5-10年 本科 移动互联网,消费生活 C轮 2000人以上 70000 50000 60000.0 1466 数据分析专家 字节跳动 深圳 南山区 数据分析 “扁平管理,过亿用户,职业大牛” 经验不限 本科 文娱丨内容 C轮 2000人以上 70000 35000 52500.0 1504 商业数据分析师 (003969) vivo 深圳 宝安区 移动互联网 “弹性工作,股票期权,大数据平台 千万用户” 经验3-5年 本科 硬件 未融资 2000人以上 80000 50000 65000.0 1512 数据分析高级工程师 腾讯 深圳 前海 数据分析 Hadoop Spark 数据挖掘 “腾讯平台 福利待遇好 技术成长” 经验3-5年 本科 社交 上市公司 2000人以上 70000 40000 55000.0 1514 商业数据分析师 vivo 深圳 宝安区 移动互联网 “股票期权,精英团队,弹性工作” 经验3-5年 本科 硬件 未融资 2000人以上 80000 50000 65000.0 1538 数据分析总监 万顺赢 深圳 科技园 医疗健康 工具软件 “中国知名企业,福利好” 经验5-10年 硕士 移动互联网,金融 未融资 150-500人 80000 45000 62500.0
def get_three_std_data ( df) :
"""提取疑似异常数据进行分析"""
mean = df. 平均薪资. mean( )
std = df. 平均薪资. std( )
a = df. 平均薪资. mean( ) + 3 * df. 平均薪资. std( )
b = df. 平均薪资. mean( ) - 3 * df. 平均薪资. std( )
result = df[ ( df. 平均薪资 > a) | ( df. 平均薪资 < b) ]
return result
get_three_std_data( df) . shape
(14, 14)
df_all = get_three_std_data( df)
df_all[ df. 城市== '北京' ]
<ipython-input-442-4ce1ac862829>:2: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
df_all[df.城市=='北京']
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 744 数据分析师/数据科学家 滴滴 北京 西北旺 Hadoop 数据挖掘 MySQL “数据精确,老大nb,汇报线简单” 经验5-10年 本科 汽车丨出行 不需要融资 2000人以上 60000 40000 50000.0 762 数据分析总监 发现旅行 北京 朝阳区 数据分析 “扁平化管理,氛围超好,地位重要,待遇优厚” 经验5-10年 本科 旅游 B轮 50-150人 80000 50000 65000.0
get_three_std_data( df[ df. 城市 == "北京" ] )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 744 数据分析师/数据科学家 滴滴 北京 西北旺 Hadoop 数据挖掘 MySQL “数据精确,老大nb,汇报线简单” 经验5-10年 本科 汽车丨出行 不需要融资 2000人以上 60000 40000 50000.0 762 数据分析总监 发现旅行 北京 朝阳区 数据分析 “扁平化管理,氛围超好,地位重要,待遇优厚” 经验5-10年 本科 旅游 B轮 50-150人 80000 50000 65000.0
df. 学历要求. value_counts( )
本科 1332
不限 109
大专 89
硕士 78
博士 1
Name: 学历要求, dtype: int64
df. groupby( '学历要求' ) . mean( ) . sort_values( by= '平均薪资' , ascending= False )
最高薪资 最低薪资 平均薪资 学历要求 博士 60000.000000 35000.000000 47500.000000 硕士 27474.358974 15692.307692 21583.333333 本科 24875.375375 14390.390390 19632.882883 不限 22807.339450 13146.788991 17977.064220 大专 13932.584270 8348.314607 11140.449438
df_beijing = df[ df. 城市 == "北京" ] . copy( )
df_beijing. 地点. value_counts( )
朝阳区 82
海淀区 76
望京 44
中关村 20
西北旺 14
..
石景山区 1
八角 1
国贸 1
西苑 1
燕莎 1
Name: 地点, Length: 68, dtype: int64
df_beijing[ '地点' ] . values
array(['苏州街', '海淀区', '大屯', '太平桥', '海淀区', '西北旺', '朝阳区', '海淀区', '和平里',
'海淀区', '酒仙桥', '朝阳区', '五道口', '海淀区', '西直门', '西二旗', '海淀区', '大山子',
'朝阳区', '苏州街', '北太平庄', '朝阳区', '西二旗', '大山子', '西三旗', '中关村', '海淀区',
'亦庄', '朝阳区', '海淀区', '上地', '中关村', '中关村', '五道口', '西城区', '上地', '朝阳区',
'宣武门', '西二旗', '朝阳区', '海淀区', '朝阳区', '三元桥', '东四', '中关村', '海淀区', '望京',
'团结湖', '海淀区', '亚运村', '中关村', '东城区', '朝阳区', '朝阳区', '西直门', '朝阳区',
'朝阳区', '朝阳区', '朝阳区', '酒仙桥', '海淀区', '东城区', '西城区', '望京', '亦庄', '海淀区',
'中关村', '团结湖', '海淀区', '海淀区', '望京', '小关', '朝阳区', '朝阳区', '海淀区', '东城区',
'海淀区', '朝阳区', '朝阳区', '西北旺', '望京', '望京', '西北旺', '海淀区', '朝阳区', '东四',
'朝阳区', '海淀区', '海淀区', '上地', '朝阳区', '朝阳区', '朝阳区', '海淀区', '团结湖',
'大望路', '望京', '海淀区', '大望路', '石佛营', '朝阳区', '海淀区', '和平里', '清河', '上地',
'海淀区', '三里河', '海淀区', '望京', '朝阳区', '朝阳区', '三元桥', '三里屯', '朝阳区',
'朝阳区', '中关村', '朝阳区', '望京', '海淀区', '海淀区', '海淀区', '东城区', '朝阳区',
'海淀区', '海淀区', '西北旺', '朝阳区', '西北旺', '海淀区', '北太平庄', '望京', '朝阳区',
'团结湖', '上地', '海淀区', '上地', '西北旺', '望京', '小关', '丰台区', '东城区', '朝阳区',
'海淀区', '望京', '酒仙桥', '国贸', '酒仙桥', '亚运村', '海淀区', '朝阳区', '北京大学', '上地',
'酒仙桥', '北京大学', '朝外', '中关村', '大望路', '中关村', '朝阳区', '望京', '太平桥', '望京',
'朝阳区', '海淀区', '朝阳门', '望京', '雍和宫', '朝阳区', '东四', '石佛营', '海淀区', '望京',
'朝阳区', '东四', '望京', '望京', '东城区', '中关村', '海淀区', '华贸', '西三旗', '西三旗',
'亮马桥', '朝阳区', '海淀区', '酒仙桥', '朝阳区', '海淀区', '望京', '朝阳区', '东城区',
'学院路', '朝阳区', '团结湖', '四惠', '酒仙桥', '朝阳区', '望京', '北京大学', '朝阳区',
'中关村', '望京', '昌平区', '东城区', '望京', '酒仙桥', '学院路', '朝阳区', '西城区', '酒仙桥',
'大望路', '中关村', '小关', '朝阳区', '望京', '朝阳区', '大望路', '海淀区', '昌平区', '海淀区',
'朝阳区', '西三旗', '西北旺', '望京', '东四', '八大处', '望京', '东四', '大山子', '三元桥',
'东坝', '西北旺', '燕莎', '海淀区', '海淀区', '雍和宫', '望京', '十里堡', '学院路', '中关村',
'月坛', '团结湖', '海淀区', '大山子', '朝阳区', '海淀区', '北京大学', '朝阳区', '海淀区',
'西北旺', '海淀区', '八角', '望京', '望京', '学院路', '来广营', '望京', '大望路', '中关村',
'朝阳区', '朝阳区', '海淀区', '北京大学', '海淀区', '昌平区', '万泉河', '海淀区', '望京',
'海淀区', '望京', '望京', '酒仙桥', '朝阳区', '五道口', '西三旗', '中关村', '中关村', '朝阳区',
'海淀区', '朝阳区', '望京', '中关村', '延庆区', '百子湾', '建国门', '中关村', '海淀区', '亦庄',
'安定门', '北苑', '望京', '望京', '海淀区', '朝阳区', '百子湾', '安贞', '西二旗', '望京',
'望京', '上地', '朝阳区', '朝阳区', '朝阳区', '西北旺', '朝阳区', '北苑', '朝外', '海淀区',
'朝阳区', '亮马桥', '双井', '安贞', '学院路', '望京', '双井', '朝外', '酒仙桥', '大山子',
'知春路', '朝阳区', '朝阳区', '海淀区', '朝阳区', '大山子', '海淀区', '朝阳区', '大山子',
'朝阳区', '海淀区', '小关', '西三旗', '昌平区', '望京', '朝阳区', '奥运村', '朝阳区', '海淀区',
'朝阳区', '海淀区', '五道口', '海淀区', '上地', '四惠', '朝阳区', '大兴区', '学院路', '朝外',
'朝阳区', '朝阳区', '朝阳区', '海淀区', '西二旗', '清河', '海淀区', '十里堡', '大屯', '望京',
'海淀区', '朝阳区', '朝阳区', '西北旺', '朝阳区', '望京', '上地', '海淀区', '海淀区', '朝阳区',
'朝阳区', '奥运村', '太阳宫', '西苑', '西二旗', '科技园区', '朝阳公园', '西二旗', '朝阳区',
'太平桥', '大山子', '团结湖', '西北旺', '海淀区', '海淀区', '建外大街', '雍和宫', '望京',
'海淀区', '海淀区', '永顺', '四惠', '大兴区', '安定门', '五道口', '安定门', '大屯', '东坝',
'海淀区', '海淀区', '亦庄', '十里堡', '朝阳区', '海淀区', '朝阳区', '朝阳区', '中关村',
'海淀区', '大屯', '望京', '朝阳门', '中关村', '上地', '海淀区', '大兴区', '大兴区', '石景山区',
'西北旺', '五道口', '东城区', '望京', '潘家园', '西北旺', '海淀区', '朝阳门', '望京', '朝阳门',
'大屯'], dtype=object)
list ( set ( df_beijing[ '地点' ] . values) )
df_beijing. 地点. value_counts( ) . index
np. unique( df_beijing. 地点)
df_beijing. 地点. drop_duplicates( )
418 苏州街
419 海淀区
420 大屯
421 太平桥
423 西北旺
...
816 朝阳公园
825 建外大街
830 永顺
856 石景山区
861 潘家园
Name: 地点, Length: 68, dtype: object
loc = np. unique( df_beijing. 地点)
loc
array(['万泉河', '三元桥', '三里屯', '三里河', '上地', '东四', '东坝', '东城区', '中关村', '丰台区',
'五道口', '亚运村', '亦庄', '亮马桥', '八大处', '八角', '北京大学', '北太平庄', '北苑',
'十里堡', '华贸', '双井', '和平里', '四惠', '团结湖', '国贸', '大兴区', '大屯', '大山子',
'大望路', '太平桥', '太阳宫', '奥运村', '学院路', '安定门', '安贞', '宣武门', '小关', '延庆区',
'建国门', '建外大街', '昌平区', '月坛', '望京', '朝外', '朝阳公园', '朝阳区', '朝阳门',
'来广营', '永顺', '海淀区', '清河', '潘家园', '燕莎', '百子湾', '知春路', '石佛营', '石景山区',
'科技园区', '苏州街', '西三旗', '西二旗', '西北旺', '西城区', '西直门', '西苑', '酒仙桥',
'雍和宫'], dtype=object)
[ plt. cm. tab10( i/ float ( len ( loc) ) ) for i in range ( len ( loc) ) ]
[(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(0.12156862745098039, 0.4666666666666667, 0.7058823529411765, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(1.0, 0.4980392156862745, 0.054901960784313725, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.17254901960784313, 0.6274509803921569, 0.17254901960784313, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.8392156862745098, 0.15294117647058825, 0.1568627450980392, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5803921568627451, 0.403921568627451, 0.7411764705882353, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.5490196078431373, 0.33725490196078434, 0.29411764705882354, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.8901960784313725, 0.4666666666666667, 0.7607843137254902, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.4980392156862745, 0.4980392156862745, 0.4980392156862745, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.7372549019607844, 0.7411764705882353, 0.13333333333333333, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0),
(0.09019607843137255, 0.7450980392156863, 0.8117647058823529, 1.0)]
[ * enumerate ( loc) ]
[(0, '万泉河'),
(1, '三元桥'),
(2, '三里屯'),
(3, '三里河'),
(4, '上地'),
(5, '东四'),
(6, '东坝'),
(7, '东城区'),
(8, '中关村'),
(9, '丰台区'),
(10, '五道口'),
(11, '亚运村'),
(12, '亦庄'),
(13, '亮马桥'),
(14, '八大处'),
(15, '八角'),
(16, '北京大学'),
(17, '北太平庄'),
(18, '北苑'),
(19, '十里堡'),
(20, '华贸'),
(21, '双井'),
(22, '和平里'),
(23, '四惠'),
(24, '团结湖'),
(25, '国贸'),
(26, '大兴区'),
(27, '大屯'),
(28, '大山子'),
(29, '大望路'),
(30, '太平桥'),
(31, '太阳宫'),
(32, '奥运村'),
(33, '学院路'),
(34, '安定门'),
(35, '安贞'),
(36, '宣武门'),
(37, '小关'),
(38, '延庆区'),
(39, '建国门'),
(40, '建外大街'),
(41, '昌平区'),
(42, '月坛'),
(43, '望京'),
(44, '朝外'),
(45, '朝阳公园'),
(46, '朝阳区'),
(47, '朝阳门'),
(48, '来广营'),
(49, '永顺'),
(50, '海淀区'),
(51, '清河'),
(52, '潘家园'),
(53, '燕莎'),
(54, '百子湾'),
(55, '知春路'),
(56, '石佛营'),
(57, '石景山区'),
(58, '科技园区'),
(59, '苏州街'),
(60, '西三旗'),
(61, '西二旗'),
(62, '西北旺'),
(63, '西城区'),
(64, '西直门'),
(65, '西苑'),
(66, '酒仙桥'),
(67, '雍和宫')]
df. loc[ df. 地点== '万泉河' , : ]
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 705 数据分析工程师(可视化方向) 一起考教师 北京 万泉河 教育 可视化 “五险一金、晋升空间大、弹性工作、扁平管理” 经验1-3年 本科 移动互联网,教育 B轮 150-500人 12000 10000 11000.0
plt. figure( figsize= ( 6 , 4 ) , dpi= 100 )
colors = [ plt. cm. tab10( i/ float ( len ( loc) ) ) for i in range ( len ( loc) ) ]
for i, d in enumerate ( loc) :
data = df. loc[ df. 地点== d, : ]
if data. shape[ 0 ] > 6 :
plt. scatter( i, data. shape[ 0 ]
, c= np. array( colors[ i] ) . reshape( 1 , - 1 )
, s= data. shape[ 0 ] * 50
, alpha= .6 )
plt. text( i, data. shape[ 0 ] , d, fontdict= { 'size' : 8 , 'color' : 'b' }
, horizontalalignment= 'center'
, verticalalignment= 'center'
)
plt. xticks( fontsize= 10 )
plt. yticks( fontsize= 10 )
plt. xlim( 0 , 70 )
plt. ylim( 0 , 100 )
plt. title( "北京市不同区所需数据分析师数量" , fontsize= 12 )
plt. legend( )
plt. show( ) ;
No handles with labels found to put in legend.
df_beijing. 行业. value_counts( ) [ : 10 ]
金融 46
文娱丨内容 43
移动互联网 36
移动互联网,金融 29
消费生活 29
电商 17
房产家居 17
教育 16
数据服务 15
汽车丨出行 14
Name: 行业, dtype: int64
df. 行业. str . contains( '移动互联网' ) . sum ( )
df. 行业. str . contains( '电商' ) . sum ( )
237
df_beijing[ df_beijing. 行业. str . contains( '移动互联网' ) ] . shape
(151, 14)
df_beijing[ df_beijing. 行业. str . contains( '房' ) ] . shape
(17, 14)
df_beijing[ df_beijing. 行业. str . contains( '金融' ) ] . shape
(87, 14)
df. 岗位技能
0 大数据 移动互联网 Hive Hadoop Spark
1 SQL 数据库
2 SPSS 数据运营 数据库
3 大数据 金融 MySQL Oracle 算法
4 数据分析 数据库
...
1633 大数据 数据分析
1634 移动互联网 大数据
1635 市场 数据分析
1636 架构师 Python 爬虫工程师 机器学习
1637 数据挖掘 数据分析
Name: 岗位技能, Length: 1609, dtype: object
了解一下,数据分析这个行业,对什么技能要求最多
s = df. 岗位技能. str . cat( sep= " " )
work_str = df. 岗位技能. str . cat( sep= " " )
skill_list = work_str. split( " " )
skill_set = set ( skill_list)
res_dict = { }
for i in skill_set:
res_dict[ i] = skill_list. count( i)
sorted ( res_dict. items( ) , key= lambda x: x[ 1 ] , reverse= True )
[('数据分析', 1145),
('大数据', 308),
('SQL', 279),
('电商', 207),
('数据运营', 183),
('移动互联网', 175),
('BI', 167),
('数据挖掘', 159),
('数据库', 125),
('商业', 115),
('SPSS', 100),
('MySQL', 93),
('可视化', 89),
('金融', 64),
('数据处理', 58),
('教育', 48),
('游戏', 48),
('新零售', 46),
('互联网金融', 43),
('Hive', 42),
('SQLServer', 42),
('算法', 40),
('广告营销', 33),
('风控', 29),
('Hadoop', 28),
('企业服务', 25),
('本地生活', 25),
('数据仓库', 25),
('增长黑客', 23),
('运营', 23),
('医疗健康', 21),
('ETL', 20),
('社交', 17),
('分析师', 16),
('银行', 16),
('市场分析', 14),
('视频', 14),
('Spark', 14),
('数据架构', 13),
('房产服务', 12),
('汽车', 12),
('行业分析', 12),
('云计算', 11),
('信息安全', 11),
('物流', 11),
('通信/网络设备', 11),
('Java', 11),
('工具软件', 10),
('其他', 10),
('风险分析', 9),
('Oracle', 9),
('数据库开发', 9),
('DBA', 9),
('借贷', 8),
('旅游', 8),
('直播', 7),
('分析', 7),
('用户增长', 7),
('机器学习', 7),
('产品', 7),
('产品策划', 6),
('保险', 6),
('营销策略', 6),
('用户运营', 5),
('媒体', 5),
('电商运营', 5),
('数据', 5),
('弹性工作', 5),
('市场竞争分析', 5),
('产品运营', 5),
('策略设计', 5),
('信贷风险管理', 5),
('消费者分析', 5),
('征信', 5),
('滴滴', 5),
('审核', 4),
('NLP', 4),
('Scala', 4),
('岗位晋升', 4),
('策略运营', 4),
('产品设计', 4),
('市场', 4),
('财务', 3),
('项目管理', 3),
('Python', 3),
('MongoDB', 3),
('分类信息', 3),
('风险管理', 3),
('智能硬件', 3),
('行业研究', 3),
('建模', 3),
('扁平管理', 3),
('营销', 3),
('内容运营', 3),
('效果跟踪', 3),
('支付', 3),
('SEO', 3),
('绩效奖金', 3),
('技能培训', 3),
('节日礼物', 3),
('股票期权', 2),
('搜索', 2),
('带薪年假', 2),
('定期体检', 2),
('人工智能', 2),
('用户研究', 2),
('推广', 2),
('内容', 2),
('信用产品', 2),
('理财', 2),
('深度学习', 2),
('体育', 2),
('需求分析', 2),
('架构师', 2),
('Redis', 2),
('年度旅游', 2),
('数据审核', 2),
('游戏运营', 2),
('网站分析', 2),
('基金', 2),
('投资/融资', 2),
('数字营销', 2),
('风险评估', 2),
('网店推广', 2),
('DB2', 2),
('服务器端', 2),
('目标管理', 2),
('后端', 2),
('地图', 1),
('资产/项目评估', 1),
('安全', 1),
('SaaS', 1),
('年底双薪', 1),
('人力资源', 1),
('外企', 1),
('售后', 1),
('APP推广', 1),
('就近租房补贴', 1),
('团队建设', 1),
('技术支持', 1),
('新媒体运营', 1),
('管理规范', 1),
('天猫运营', 1),
('决策能力', 1),
('人事', 1),
('售前', 1),
('市场推广', 1),
('数据压缩', 1),
('增长黑客(GrowthHacking)', 1),
('零食水果供应', 1),
('大厨定制三餐', 1),
('名企保面试', 1),
('区块链', 1),
('KPI考核', 1),
('战略管理', 1),
('解决方案', 1),
('会计', 1),
('技术管理', 1),
('产品经理', 1),
('跨境电商', 1),
('资信评估', 1),
('一手内推信息', 1),
('运维', 1),
('资产管理', 1),
('供应链', 1),
('用户', 1),
('专项奖金', 1),
('交互设计', 1),
('产销协调', 1),
('证券/期货', 1),
('Linux/Unix', 1),
('客服', 1),
('上市', 1),
('精准高效对接', 1),
('理财顾问', 1),
('猎头专业服务', 1),
('互相营销', 1),
('领导好', 1),
('营销管理', 1),
('新闻|出版', 1),
('VC', 1),
('广告创意', 1),
('hadoop', 1),
('后台', 1),
('PKI', 1),
('分布式', 1),
('软件开发', 1),
('整合营销', 1),
('核查', 1),
('校对', 1),
('淘宝运营', 1),
('社会化营销', 1),
('尽职调查', 1),
('信用管理', 1),
('爬虫工程师', 1),
('广告协调', 1),
('渠道', 1),
('成本', 1),
('外汇', 1),
('HR', 1),
('商业产品', 1),
('SEM', 1)]
jineng_list = s. split( ' ' )
jineng_list
['大数据',
'移动互联网',
'Hive',
'Hadoop',
'Spark',
'SQL',
'数据库',
'SPSS',
'数据运营',
'数据库',
'大数据',
'金融',
'MySQL',
'Oracle',
'算法',
'数据分析',
'数据库',
'分析师',
'电商',
'大数据',
'数据分析',
'SQL',
'数据库',
'电商',
'商业',
'数据分析',
'专项奖金',
'带薪年假',
'弹性工作',
'管理规范',
'BI',
'商业',
'SQL',
'数据分析',
'目标管理',
'KPI考核',
'决策能力',
'战略管理',
'数据分析',
'可视化',
'SQL',
'电商',
'企业服务',
'商业',
'数据分析',
'大数据',
'金融',
'数据分析',
'数据分析',
'新零售',
'大数据',
'商业',
'广告营销',
'移动互联网',
'数据分析',
'数据挖掘',
'MySQL',
'大数据',
'企业服务',
'SQL',
'数据分析',
'金融',
'大数据',
'数据分析',
'数据运营',
'数据库',
'SQL',
'数据分析',
'大数据',
'数据分析',
'数据分析',
'数据处理',
'SQLServer',
'大数据',
'电商',
'数据分析',
'移动互联网',
'教育',
'数据分析',
'大数据',
'机器学习',
'数据挖掘',
'大数据',
'金融',
'数据分析',
'数据处理',
'算法',
'数据分析',
'广告营销',
'企业服务',
'商业',
'数据分析',
'DBA',
'游戏',
'数据分析',
'SQL',
'社交',
'大数据',
'BI',
'数据库',
'增长黑客',
'数据分析',
'互联网金融',
'SQL',
'数据分析',
'电商',
'金融',
'数据挖掘',
'数据分析',
'医疗健康',
'数据分析',
'SPSS',
'金融',
'SQL',
'数据库',
'社交',
'数据分析',
'大数据',
'移动互联网',
'SQL',
'数据分析',
'游戏',
'SQL',
'SPSS',
'数据分析',
'互联网金融',
'数据分析',
'BI',
'商业',
'数据分析',
'信贷风险管理',
'风控',
'风险分析',
'数据分析',
'数据运营',
'数据库',
'新零售',
'物流',
'数据分析',
'电商',
'移动互联网',
'数据分析',
'大数据',
'数据挖掘',
'数据分析',
'大数据',
'可视化',
'SPSS',
'数据分析',
'电商',
'本地生活',
'数据分析',
'数据库',
'数据运营',
'可视化',
'社交',
'移动互联网',
'年底双薪',
'节日礼物',
'技能培训',
'绩效奖金',
'数据分析',
'数据分析',
'大数据',
'商业',
'BI',
'可视化',
'数据分析',
'数据库',
'数据分析',
'SQL',
'大数据',
'数据分析',
'SPSS',
'云计算',
'大数据',
'数据分析',
'BI',
'数据分析',
'SQL',
'数据分析',
'MySQL',
'数据分析',
'运营',
'数据分析',
'数据挖掘',
'数据分析',
'BI',
'风控',
'数据分析',
'移动互联网',
'数据分析',
'电商',
'MySQL',
'新零售',
'电商',
'BI',
'SQL',
'数据分析',
'数据库',
'电商',
'BI',
'数据分析',
'数据运营',
'SQL',
'SQL',
'数据库',
'数据运营',
'SPSS',
'大数据',
'征信',
'数据分析',
'SPSS',
'广告营销',
'数据分析',
'数字营销',
'金融',
'大数据',
'BI',
'可视化',
'数据库',
'电商',
'企业服务',
'可视化',
'SQL',
'数据运营',
'大数据',
'金融',
'商业',
'数据分析',
'大数据',
'互联网金融',
'数据分析',
'大数据',
'BI',
'数据分析',
'电商',
'大数据',
'数据分析',
'SQL',
'数据分析',
'移动互联网',
'本地生活',
'BI',
'数据分析',
'SQL',
'数据库',
'内容',
'Java',
'数据分析',
'数据分析',
'本地生活',
'新零售',
'数据分析',
'数据运营',
'BI',
'SQL',
'大数据',
'移动互联网',
'数据分析',
'数据分析',
'数据运营',
'SQL',
'SPSS',
'旅游',
'大数据',
'ETL',
'Hive',
'数据分析',
'数据处理',
'移动互联网',
'教育',
'数据分析',
'数据运营',
'Spark',
'大数据',
'数据分析',
'新零售',
'教育',
'移动互联网',
'数据分析',
'数据运营',
'SQL',
'电商',
'新零售',
'数据分析',
'数据挖掘',
'数据分析',
'Hive',
'BI',
'可视化',
'数据分析',
'SQL',
'大数据',
'其他',
'ETL',
'DB2',
'数据分析',
'信息安全',
'机器学习',
'建模',
'算法',
'大数据',
'数据分析',
'Hive',
'风控',
'数据分析',
'游戏',
'大数据',
'MySQL',
'Hadoop',
'Spark',
'数据分析',
'银行',
'借贷',
'数据分析',
'SQL',
'电商',
'商业',
'SQL',
'MySQL',
'数据挖掘',
'数据分析',
'数据分析',
'电商',
'数据挖掘',
'数据分析',
'数据处理',
'MySQL',
'互联网金融',
'风控',
'分析师',
'信用产品',
'数据分析',
'数据分析',
'SQL',
'旅游',
'移动互联网',
'数据分析',
'数据库',
'数据分析',
'SQL',
'数据运营',
'金融',
'商业',
'BI',
'可视化',
'数据分析',
'SPSS',
'SQL',
'数据库',
'数据分析',
'数据分析',
'SPSS',
'数据分析',
'数据分析',
'银行',
'MySQL',
'数据分析',
'风控',
'信贷风险管理',
'金融',
'通信/网络设备',
'Hive',
'数据分析',
'大数据',
'移动互联网',
'大数据',
'数据分析',
'SQL',
'电商',
'移动互联网',
'数据分析',
'SQL',
'BI',
'数据分析',
'数据运营',
'电商',
'移动互联网',
'数据分析',
'企业服务',
'大数据',
'数据运营',
'可视化',
'数据库',
'数据分析',
'数据分析',
'数据库',
'SQL',
'移动互联网',
'移动互联网',
'金融',
'数据分析',
'SQL',
'电商',
'新零售',
'数据分析',
'数据分析',
'数据仓库',
'数据库开发',
'电商',
'BI',
'数据分析',
'移动互联网',
'商业',
'BI',
'数据分析',
'BI',
'可视化',
'数据运营',
'数据分析',
'数据分析',
'MySQL',
'Hadoop',
'教育',
'移动互联网',
'SQL',
'BI',
'数据分析',
'数据架构',
'BI',
'可视化',
'数据分析',
'数据运营',
'数据分析',
'MySQL',
'游戏',
'大数据',
'数据挖掘',
'数据分析',
'数据分析',
'数据库',
'数据分析',
'数据运营',
'大数据',
'移动互联网',
'数据分析',
'大数据',
'金融',
'数据分析',
'SQL',
'BI',
'商业',
'Hadoop',
'MySQL',
'数据挖掘',
'信息安全',
'数据分析',
'数据库',
'SQL',
'教育',
'数据分析',
'数据运营',
'SQL',
'大数据',
'数据分析',
'数据分析',
'数据运营',
'数据库',
'SQL',
'大数据',
'数据分析',
'数据处理',
'数据分析',
'电商',
'新零售',
'电商',
'数据挖掘',
'数据分析',
'算法',
'电商',
'BI',
'SPSS',
'互联网金融',
'SQLServer',
'数据分析',
'数据挖掘',
'MySQL',
'大数据',
'数据分析',
'数据库',
'SPSS',
'数据分析',
'数据分析',
'MySQL',
'数据分析',
'新零售',
'数据分析',
'数据分析',
'商业',
'数据分析',
'SQL',
'数据分析',
'电商',
'医疗健康',
'MySQL',
'数据分析',
'BI',
'数据分析',
'数据分析',
'BI',
'数据分析',
'可视化',
'电商',
'企业服务',
'BI',
'数据分析',
'SQL',
'数据运营',
'电商',
'大数据',
'汽车',
'数据分析',
'SQL',
'移动互联网',
'数据分析',
'大数据',
'数据分析',
'数据分析',
'数据运营',
'金融',
'BI',
'数据分析',
'数据运营',
'商业',
'互联网金融',
'SQL',
'商业',
'数据分析',
'SPSS',
'移动互联网',
'数据分析',
'大数据',
'电商',
'本地生活',
'数据分析',
'BI',
'商业',
'数据分析',
'数据分析',
'可视化',
'SQL',
'数据分析',
'数据库',
'电商',
'社交',
'数据分析',
'数据处理',
'数据分析',
'本地生活',
'汽车',
'数据分析',
'SQL',
'商业',
'商业',
'数据分析',
'增长黑客',
'数据分析',
'SQL',
'BI',
'可视化',
'数据分析',
'移动互联网',
'电商',
'大数据',
'电商',
'数据分析',
'数据挖掘',
'数据分析',
'数据处理',
'大数据',
'金融',
'数据挖掘',
'数据分析',
'数据分析',
'SQL',
'数据库',
'电商',
'SQL',
'数据分析',
'可视化',
'建模',
'深度学习',
'机器学习',
'数据挖掘',
'银行',
'数据挖掘',
'数据分析',
'数据分析',
'电商',
'商业',
'BI',
'可视化',
'数据分析',
'数据分析',
'房产服务',
'移动互联网',
'可视化',
'数据分析',
'数据运营',
'商业',
'SQL',
'数据分析',
'大数据',
'数据挖掘',
'Hadoop',
'数据分析',
'大数据',
'数据分析',
'数据分析',
'SQLServer',
'数据处理',
'大数据',
'媒体',
'数据挖掘',
'数据分析',
'游戏',
'企业服务',
'数据分析',
'行业分析',
'大数据',
'数据分析',
'SQL',
'BI',
'可视化',
'数据分析',
'hadoop',
'风控',
'风险管理',
'风险评估',
'大数据',
'数据分析',
'SQL',
'数据分析',
'Hive',
'MySQL',
'数据分析',
'电商',
'数据分析',
'旅游',
'数据分析',
'SPSS',
'游戏',
'数据分析',
'商业',
'移动互联网',
'数据分析',
'数据运营',
'移动互联网',
'数据分析',
'数据分析',
'数据分析',
'金融',
'数据挖掘',
'数据分析',
'数据分析',
'数据运营',
'数据分析',
'风控',
'策略设计',
'电商',
'移动互联网',
'数据分析',
'数据挖掘',
'数据分析',
'电商',
'教育',
'数据分析',
'MySQL',
'Redis',
'大数据',
'BI',
'数据分析',
'SQL',
'可视化',
'数据分析',
'SPSS',
'新零售',
'物流',
'数据分析',
'Hive',
'数据处理',
'数据分析',
'BI',
'数据分析',
'数据库',
'DBA',
'大数据',
'数据挖掘',
'算法',
'大数据',
'MySQL',
'电商',
'BI',
'可视化',
'数据分析',
'SQL',
'移动互联网',
'增长黑客',
'数据分析',
'数据运营',
'大数据',
'新零售',
'数据分析',
'移动互联网',
'MySQL',
'数据分析',
'大数据',
'数据分析',
'数据分析',
'新零售',
'电商',
'数据分析',
'MySQL',
'数据仓库',
'广告创意',
'广告协调',
'数据分析',
'广告营销',
'数据分析',
'数据分析',
'移动互联网',
'商业',
'数据分析',
'增长黑客',
'可视化',
'大数据',
'数据分析',
'数据分析',
'SPSS',
'SQL',
'数据分析',
'SQL',
'数据库',
'医疗健康',
'数据分析',
'大数据',
'金融',
'数据分析',
'移动互联网',
'媒体',
'商业',
'数据分析',
'银行',
'数据分析',
'SPSS',
'电商',
'大数据',
'商业',
'SQL',
'数据分析',
'其他',
'数据分析',
'运营',
'内容运营',
'新零售',
'本地生活',
'BI',
'数据分析',
'数据分析',
'数据分析',
'市场',
'游戏',
'BI',
'数据分析',
'教育',
'电商',
'大数据',
'数据分析',
'后端',
'服务器端',
'电商',
'分析',
'移动互联网',
'BI',
'数据分析',
'数据库',
'房产服务',
'企业服务',
'BI',
'可视化',
'数据库',
'电商',
'数据分析',
'SQL',
'数据库',
'数据运营',
'数据分析',
'数据分析',
'移动互联网',
'风控',
'游戏',
'数据分析',
'SPSS',
'BI',
'数据分析',
'数据分析',
'大数据',
'电商',
'移动互联网',
'数据分析',
'BI',
'增长黑客(GrowthHacking)',
'数据分析',
'数据分析',
'医疗健康',
'移动互联网',
'大数据',
'移动互联网',
'移动互联网',
'大数据',
'数据分析',
'商业',
'BI',
'数据库',
'视频',
'产品策划',
'智能硬件',
'数据分析',
'MySQL',
'数据分析',
'数据仓库',
'数据处理',
'风险分析',
'风控',
'移动互联网',
'大数据',
'风控',
'分析师',
'策略设计',
'大数据',
'BI',
'数据分析',
'SPSS',
'金融',
'算法',
'数据挖掘',
'数据分析',
'数据分析',
'大数据',
'数据分析',
'电商',
'数据分析',
'MySQL',
'数据处理',
'电商',
'SQLServer',
'数据分析',
'数据分析',
'数据运营',
'电商',
'SPSS',
'数据分析',
'数据分析',
'商业',
'大数据',
'算法',
'数据挖掘',
'数据分析',
'大数据',
'商业',
'BI',
'可视化',
'数据分析',
'医疗健康',
'数据分析',
'BI',
'游戏',
'数据分析',
'数据挖掘',
'增长黑客',
'BI',
'可视化',
'征信',
'保险',
'数据分析',
'SQL',
'大数据',
'数据分析',
'SPSS',
'数据分析',
'市场分析',
'营销策略',
'运营',
'SEM',
'SEO',
'数据分析',
'金融',
'移动互联网',
'风控',
'信用产品',
'电商',
'移动互联网',
'商业',
'BI',
'数据分析',
'数据库',
'银行',
'数据分析',
'教育',
'数据分析',
'大数据',
'教育',
'数据分析',
'SPSS',
'电商',
'数据挖掘',
'数据架构',
'算法',
'数据分析',
'SQL',
'大数据',
'数据分析',
'房产服务',
'BI',
'数据分析',
'SQL',
'运营',
'BI',
'商业',
'可视化',
'数据分析',
'广告营销',
'汽车',
'营销',
'数据分析',
'行业分析',
'市场分析',
'目标管理',
'大数据',
'数据挖掘',
'大数据',
'数据分析',
'数据挖掘',
'电商',
'移动互联网',
'ETL',
'Spark',
'数据仓库',
'数据分析',
'Hadoop',
'数据分析',
'Hive',
'大数据',
'大数据',
'数据挖掘',
'数据分析',
'数据分析',
'数据分析',
'SQL',
'数据分析',
'数据运营',
'SPSS',
'数据分析',
'电商',
'移动互联网',
'数据分析',
'数据挖掘',
'数据处理',
'算法',
'Hive',
'数据分析',
'消费者分析',
'市场分析',
'数据挖掘',
'数据分析',
'银行',
'解决方案',
'新零售',
'数据分析',
'电商',
'SQL',
'数据分析',
'风控',
'数据分析',
'数据挖掘',
'NLP',
'算法',
'BI',
'数据分析',
'电商',
'移动互联网',
'数据分析',
'数据库开发',
'SQLServer',
'安全',
'大数据',
'数据分析',
'电商',
'工具软件',
'数据分析',
'用户运营',
'数据分析',
'数据分析',
'数据分析',
'企业服务',
'工具软件',
'数据挖掘',
'数据架构',
'数据仓库',
...]
jineng_list. count( '大数据' )
308
jineng_set = set ( jineng_list)
len ( jineng_set)
202
jineng_set. remove( '数据分析' )
len ( jineng_set)
201
empty_list = [ ]
for i in jineng_set:
empty_list. append( ( i, jineng_list. count( i) ) )
empty_list
[('地图', 1),
('资产/项目评估', 1),
('教育', 48),
('安全', 1),
('股票期权', 2),
('SaaS', 1),
('用户运营', 5),
('Hadoop', 28),
('风险分析', 9),
('年底双薪', 1),
('分析师', 16),
('互联网金融', 43),
('房产服务', 12),
('搜索', 2),
('人力资源', 1),
('社交', 17),
('审核', 4),
('财务', 3),
('外企', 1),
('带薪年假', 2),
('市场分析', 14),
('银行', 16),
('直播', 7),
('媒体', 5),
('电商运营', 5),
('售后', 1),
('项目管理', 3),
('APP推广', 1),
('就近租房补贴', 1),
('企业服务', 25),
('ETL', 20),
('Hive', 42),
('定期体检', 2),
('SPSS', 100),
('团队建设', 1),
('数据', 5),
('人工智能', 2),
('用户研究', 2),
('分析', 7),
('弹性工作', 5),
('NLP', 4),
('市场竞争分析', 5),
('数据库', 125),
('技术支持', 1),
('Python', 3),
('新媒体运营', 1),
('推广', 2),
('管理规范', 1),
('内容', 2),
('MongoDB', 3),
('医疗健康', 21),
('汽车', 12),
('产品策划', 6),
('工具软件', 10),
('产品运营', 5),
('天猫运营', 1),
('决策能力', 1),
('Scala', 4),
('人事', 1),
('数据运营', 183),
('本地生活', 25),
('信用产品', 2),
('行业分析', 12),
('售前', 1),
('市场推广', 1),
('数据压缩', 1),
('大数据', 308),
('增长黑客(GrowthHacking)', 1),
('零食水果供应', 1),
('大厨定制三餐', 1),
('移动互联网', 175),
('分类信息', 3),
('名企保面试', 1),
('保险', 6),
('策略设计', 5),
('区块链', 1),
('KPI考核', 1),
('理财', 2),
('增长黑客', 23),
('战略管理', 1),
('解决方案', 1),
('数据仓库', 25),
('深度学习', 2),
('会计', 1),
('技术管理', 1),
('产品经理', 1),
('信贷风险管理', 5),
('跨境电商', 1),
('Oracle', 9),
('数据库开发', 9),
('风控', 29),
('资信评估', 1),
('借贷', 8),
('一手内推信息', 1),
('运维', 1),
('资产管理', 1),
('风险管理', 3),
('智能硬件', 3),
('岗位晋升', 4),
('体育', 2),
('供应链', 1),
('游戏', 48),
('用户', 1),
('需求分析', 2),
('SQL', 279),
('架构师', 2),
('广告营销', 33),
('专项奖金', 1),
('行业研究', 3),
('交互设计', 1),
('旅游', 8),
('MySQL', 93),
('数据挖掘', 159),
('Redis', 2),
('建模', 3),
('年度旅游', 2),
('扁平管理', 3),
('产销协调', 1),
('算法', 40),
('新零售', 46),
('DBA', 9),
('营销', 3),
('用户增长', 7),
('证券/期货', 1),
('策略运营', 4),
('Linux/Unix', 1),
('客服', 1),
('消费者分析', 5),
('上市', 1),
('征信', 5),
('精准高效对接', 1),
('数据审核', 2),
('游戏运营', 2),
('理财顾问', 1),
('网站分析', 2),
('视频', 14),
('数据处理', 58),
('滴滴', 5),
('云计算', 11),
('内容运营', 3),
('猎头专业服务', 1),
('机器学习', 7),
('互相营销', 1),
('产品设计', 4),
('领导好', 1),
('基金', 2),
('Spark', 14),
('营销管理', 1),
('新闻|出版', 1),
('VC', 1),
('SQLServer', 42),
('广告创意', 1),
('市场', 4),
('hadoop', 1),
('后台', 1),
('PKI', 1),
('电商', 207),
('投资/融资', 2),
('数字营销', 2),
('效果跟踪', 3),
('支付', 3),
('信息安全', 11),
('风险评估', 2),
('分布式', 1),
('软件开发', 1),
('数据架构', 13),
('营销策略', 6),
('物流', 11),
('SEO', 3),
('绩效奖金', 3),
('整合营销', 1),
('网店推广', 2),
('核查', 1),
('产品', 7),
('校对', 1),
('淘宝运营', 1),
('社会化营销', 1),
('BI', 167),
('尽职调查', 1),
('信用管理', 1),
('其他', 10),
('通信/网络设备', 11),
('DB2', 2),
('爬虫工程师', 1),
('服务器端', 2),
('广告协调', 1),
('运营', 23),
('渠道', 1),
('目标管理', 2),
('成本', 1),
('外汇', 1),
('可视化', 89),
('商业', 115),
('技能培训', 3),
('HR', 1),
('金融', 64),
('节日礼物', 3),
('商业产品', 1),
('后端', 2),
('Java', 11),
('SEM', 1)]
from pyecharts. charts import Page, WordCloud
c = (
WordCloud( )
. add( "岗位技能" , empty_list, word_size_range= [ 20 , 100 ] , shape= "triangle" )
. set_global_opts( title_opts= opts. TitleOpts( title= "岗位技能词云图" ) )
)
c. render( '岗位技能1.html' )
'C:\\Users\\Administrator\\Desktop\\python\\机器学习案例汇总\\1.python数据清洗可视化\\岗位技能1.html'
数据编码 数据离散化 哑变量(One-hot编码) 数据的标准化 0-1标准化, 普通标准化 降维(把方差太小的特征删除,PCA压缩降维) df. head( 2 )
岗位名称 公司名称 城市 地点 岗位技能 公司福利 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 0 数据分析师 名片全能王 上海 静安区 大数据 移动互联网 Hive Hadoop Spark “免费早晚餐、扁平化管理、免费零食供应” 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 15000.0 1 数据分析师 奇虎360金融 上海 张江 SQL 数据库 “发展范围广 薪资高 福利好” 经验不限 本科 金融 上市公司 500-2000人 20000 10000 15000.0
df_copy = df. copy( )
df. drop( columns= [ '公司名称' , '公司福利' ] , inplace= True )
df. head( 2 )
岗位名称 城市 地点 岗位技能 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 15000.0 1 数据分析师 上海 张江 SQL 数据库 经验不限 本科 金融 上市公司 500-2000人 20000 10000 15000.0
df. 工作年限. value_counts( )
经验3-5年 673
经验1-3年 432
经验5-10年 221
经验不限 178
经验应届毕业生 75
经验1年以下 28
经验10年以上 2
Name: 工作年限, dtype: int64
d = { "经验不限" : 0 ,
'经验应届毕业生' : 1 ,
"经验1年以下" : 2 ,
"经验1-3年" : 3 ,
"经验3-5年" : 4 ,
"经验5-10年" : 5 ,
"经验10年以上" : 6 }
df. 工作年限[ : 5 ]
0 经验1-3年
1 经验不限
2 经验1-3年
3 经验1-3年
4 经验1-3年
Name: 工作年限, dtype: object
df. 工作年限. map ( d) [ : 5 ]
0 3
1 0
2 3
3 3
4 3
Name: 工作年限, dtype: int64
df[ '经验编码' ] = df. 工作年限. map ( d)
df. head( )
岗位名称 城市 地点 岗位技能 工作年限 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 经验编码 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 经验1-3年 本科 移动互联网 D轮及以上 150-500人 20000 10000 15000.0 3 1 数据分析师 上海 张江 SQL 数据库 经验不限 本科 金融 上市公司 500-2000人 20000 10000 15000.0 0 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 经验1-3年 本科 移动互联网,企业服务 上市公司 2000人以上 15000 8000 11500.0 3 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 经验1-3年 本科 金融 B轮 2000人以上 26000 13000 19500.0 3 4 数据分析师 上海 虹桥 数据分析 数据库 经验1-3年 大专 移动互联网,电商 D轮及以上 2000人以上 15000 10000 12500.0 3
df. drop( columns= '工作年限' , axis= 1 , inplace= True )
df. head( )
岗位名称 城市 地点 岗位技能 学历要求 行业 融资 人数 最高薪资 最低薪资 平均薪资 经验编码 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 本科 移动互联网 D轮及以上 150-500人 20000 10000 15000.0 3 1 数据分析师 上海 张江 SQL 数据库 本科 金融 上市公司 500-2000人 20000 10000 15000.0 0 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 本科 移动互联网,企业服务 上市公司 2000人以上 15000 8000 11500.0 3 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 本科 金融 B轮 2000人以上 26000 13000 19500.0 3 4 数据分析师 上海 虹桥 数据分析 数据库 大专 移动互联网,电商 D轮及以上 2000人以上 15000 10000 12500.0 3
把公司规模进行编码(即人数)
df. 人数. values
array(['150-500人', '500-2000人', '2000人以上', ..., '500-2000人', '500-2000人',
'2000人以上'], dtype=object)
df[ '人数' ] = df[ '人数' ] . apply ( lambda x: x. strip( ) )
df. 人数. values
array(['150-500人', '500-2000人', '2000人以上', ..., '500-2000人', '500-2000人',
'2000人以上'], dtype=object)
df. 人数. value_counts( )
2000人以上 596
500-2000人 364
150-500人 326
50-150人 219
15-50人 86
少于15人 18
Name: 人数, dtype: int64
d1 = { "少于15人" : 0 ,
'15-50人' : 1 ,
"50-150人" : 2 ,
"150-500人" : 3 ,
"500-2000人" : 4 ,
"2000人以上" : 5 }
df[ '公司规模' ] = df. 人数. map ( d1)
del df[ '人数' ]
df. head( )
岗位名称 城市 地点 岗位技能 学历要求 行业 融资 最高薪资 最低薪资 平均薪资 经验编码 公司规模 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 本科 移动互联网 D轮及以上 20000 10000 15000.0 3 3 1 数据分析师 上海 张江 SQL 数据库 本科 金融 上市公司 20000 10000 15000.0 0 4 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 本科 移动互联网,企业服务 上市公司 15000 8000 11500.0 3 5 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 本科 金融 B轮 26000 13000 19500.0 3 5 4 数据分析师 上海 虹桥 数据分析 数据库 大专 移动互联网,电商 D轮及以上 15000 10000 12500.0 3 5
from sklearn import preprocessing
encoder = preprocessing. LabelEncoder( )
encoder. fit_transform( df. 学历要求. values)
array([3, 3, 3, ..., 3, 3, 3])
encoder. classes_
array(['不限', '博士', '大专', '本科', '硕士'], dtype=object)
df[ '学历编码' ] = encoder. fit_transform( df. 学历要求. values)
df. 学历要求. value_counts( )
本科 1332
不限 109
大专 89
硕士 78
博士 1
Name: 学历要求, dtype: int64
df. 学历编码. value_counts( )
3 1332
0 109
2 89
4 78
1 1
Name: 学历编码, dtype: int64
import sklearn
sklearn. __version__
'0.23.1'
from sklearn. preprocessing import OneHotEncoder
onehot = OneHotEncoder( )
df. 学历要求. values. reshape( 1 , - 1 )
array([['本科', '本科', '本科', ..., '本科', '本科', '本科']], dtype=object)
df. 学历要求. values. reshape( - 1 , 1 )
array([['本科'],
['本科'],
['本科'],
...,
['本科'],
['本科'],
['本科']], dtype=object)
df. 学历要求. isnull( ) . sum ( )
0
df. 学历要求. value_counts( )
本科 1332
不限 109
大专 89
硕士 78
博士 1
Name: 学历要求, dtype: int64
onehot. fit_transform( df. 学历要求. values. reshape( - 1 , 1 ) ) . toarray( )
array([[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
...,
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.]])
data = onehot. fit_transform( df[ '学历要求' ] . values. reshape( - 1 , 1 ) ) . toarray( )
data
array([[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
...,
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.]])
temp = pd. DataFrame( data)
temp
0 1 2 3 4 0 0.0 0.0 0.0 1.0 0.0 1 0.0 0.0 0.0 1.0 0.0 2 0.0 0.0 0.0 1.0 0.0 3 0.0 0.0 0.0 1.0 0.0 4 0.0 0.0 1.0 0.0 0.0 ... ... ... ... ... ... 1604 0.0 0.0 1.0 0.0 0.0 1605 0.0 0.0 0.0 0.0 1.0 1606 0.0 0.0 0.0 1.0 0.0 1607 0.0 0.0 0.0 1.0 0.0 1608 0.0 0.0 0.0 1.0 0.0
1609 rows × 5 columns
pd. concat( [ df, temp] , axis= 1 ) . head( )
岗位名称 城市 地点 岗位技能 学历要求 行业 融资 最高薪资 最低薪资 平均薪资 经验编码 公司规模 学历编码 0 1 2 3 4 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 本科 移动互联网 D轮及以上 20000.0 10000.0 15000.0 3.0 3.0 3.0 0.0 0.0 0.0 1.0 0.0 1 数据分析师 上海 张江 SQL 数据库 本科 金融 上市公司 20000.0 10000.0 15000.0 0.0 4.0 3.0 0.0 0.0 0.0 1.0 0.0 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 本科 移动互联网,企业服务 上市公司 15000.0 8000.0 11500.0 3.0 5.0 3.0 0.0 0.0 0.0 1.0 0.0 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 本科 金融 B轮 26000.0 13000.0 19500.0 3.0 5.0 3.0 0.0 0.0 0.0 1.0 0.0 4 数据分析师 上海 虹桥 数据分析 数据库 大专 移动互联网,电商 D轮及以上 15000.0 10000.0 12500.0 3.0 5.0 2.0 0.0 0.0 1.0 0.0 0.0
df[ [ '学历要求' , '行业' ] ] . info( )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1609 entries, 0 to 1637
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 学历要求 1609 non-null object
1 行业 1609 non-null object
dtypes: object(2)
memory usage: 117.7+ KB
onehot. fit_transform( df[ [ '学历要求' , '行业' ] ] ) . toarray( ) . shape
(1609, 121)
df. head( )
岗位名称 城市 地点 岗位技能 学历要求 行业 融资 最高薪资 最低薪资 平均薪资 经验编码 公司规模 学历编码 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 本科 移动互联网 D轮及以上 20000 10000 15000.0 3 3 3 1 数据分析师 上海 张江 SQL 数据库 本科 金融 上市公司 20000 10000 15000.0 0 4 3 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 本科 移动互联网,企业服务 上市公司 15000 8000 11500.0 3 5 3 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 本科 金融 B轮 26000 13000 19500.0 3 5 3 4 数据分析师 上海 虹桥 数据分析 数据库 大专 移动互联网,电商 D轮及以上 15000 10000 12500.0 3 5 2
len ( df. 岗位技能[ 0 ] . split( ' ' ) )
5
df[ '技能数' ] = df. 岗位技能. str . split( ' ' )
df1 = df[ ~ df[ '技能数' ] . isnull( ) ]
df1. loc[ : , '技能数' ] = df1. 技能数. apply ( lambda x: len ( x) )
df1. head( )
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\indexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
岗位名称 城市 地点 岗位技能 学历要求 行业 融资 最高薪资 最低薪资 平均薪资 经验编码 公司规模 学历编码 技能数 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 本科 移动互联网 D轮及以上 20000 10000 15000.0 3 3 3 5 1 数据分析师 上海 张江 SQL 数据库 本科 金融 上市公司 20000 10000 15000.0 0 4 3 2 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 本科 移动互联网,企业服务 上市公司 15000 8000 11500.0 3 5 3 3 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 本科 金融 B轮 26000 13000 19500.0 3 5 3 5 4 数据分析师 上海 虹桥 数据分析 数据库 大专 移动互联网,电商 D轮及以上 15000 10000 12500.0 3 5 2 2
df. 融资. value_counts( )
上市公司 399
不需要融资 376
D轮及以上 188
B轮 169
C轮 167
A轮 145
未融资 137
天使轮 28
Name: 融资, dtype: int64
encoder1 = preprocessing. LabelEncoder( )
df1. loc[ : , '融资状况' ] = encoder1. fit_transform( df1. 融资. values)
df1. head( )
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\indexing.py:845: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[key] = _infer_fill_value(value)
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\indexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
岗位名称 城市 地点 岗位技能 学历要求 行业 融资 最高薪资 最低薪资 平均薪资 经验编码 公司规模 学历编码 技能数 融资状况 0 数据分析师 上海 静安区 大数据 移动互联网 Hive Hadoop Spark 本科 移动互联网 D轮及以上 20000 10000 15000.0 3 3 3 5 3 1 数据分析师 上海 张江 SQL 数据库 本科 金融 上市公司 20000 10000 15000.0 0 4 3 2 4 2 数据分析 上海 浦东新区 SPSS 数据运营 数据库 本科 移动互联网,企业服务 上市公司 15000 8000 11500.0 3 5 3 3 4 3 2521BK-数据分析师 上海 浦东新区 大数据 金融 MySQL Oracle 算法 本科 金融 B轮 26000 13000 19500.0 3 5 3 5 1 4 数据分析师 上海 虹桥 数据分析 数据库 大专 移动互联网,电商 D轮及以上 15000 10000 12500.0 3 5 2 2 3
df2 = df1. drop( columns= [ '岗位技能' , '学历要求' , '融资' ] , axis= 1 )
df2. to_csv( 'lagou_data_clean.csv' , encoding= 'utf-8' )


























 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









