






机器学习笔记(一)
回归可划分为:
(1)连续则是多重线性回归
(2)二项分布则是逻辑回归
(3)泊松分布则是泊松回归
(4)负二项分布则是负二项回归
通常使用逻辑回归来解决二分类的问题,逻辑回归也可以用作多分类,逻辑回归的线性预测输出:
y
^
=
w
T
x
+
b
\hat{y}=w^Tx+b
y^=wTx+b
逻辑回归要求输出在[0,1]之间,然而经过线性计算输出的是整个实数区间,因此我们引入sigmoid激励函数,让我们的输出限定在[0,1]之间,逻辑回归的预测输出:
y
^
=
s
i
g
m
o
i
d
(
w
T
x
+
b
)
=
σ
(
w
T
x
+
b
)
\hat{y}=sigmoid(w^Tx+b)=\sigma(w^Tx+b)
y^=sigmoid(wTx+b)=σ(wTx+b)
对于单个样本而言,逻辑回归的表达式为:
z
=
w
T
x
+
b
y
^
=
a
=
σ
(
z
)
L
(
a
,
y
)
=
−
(
y
log
(
a
)
+
(
1
−
y
)
log
(
1
−
a
)
)
z=w^Tx+b\\ \hat{y}=a=\sigma(z)\\ L(a,y)=-(y\log(a)+(1-y)\log(1-a))
z=wTx+by^=a=σ(z)L(a,y)=−(ylog(a)+(1−y)log(1−a))
计算该逻辑回归的反向传播过程,即由Loss function计算参数w和b的偏导数。推导过程如下:
d
a
=
∂
L
∂
a
=
−
y
a
+
1
−
y
1
−
a
d
z
=
∂
L
∂
z
=
∂
L
∂
a
.
∂
a
∂
z
=
(
−
y
a
+
1
−
y
1
−
a
)
.
a
(
1
−
a
)
=
a
−
y
d
w
=
∂
L
∂
w
=
∂
L
∂
z
.
∂
z
∂
w
=
d
z
.
x
=
x
(
a
−
y
)
d
b
=
∂
L
∂
b
=
∂
L
∂
z
.
∂
z
∂
b
=
d
z
.
1
=
a
−
y
da=\frac{\partial{L}}{\partial{a}}=-\frac{y}{a}+\frac{1-y}{1-a}\\ \quad\\ dz=\frac{\partial{L}}{\partial{z}}=\frac{\partial{L}}{\partial{a}}.\frac{\partial{a}}{\partial{z}}=(-\frac{y}{a}+\frac{1-y}{1-a}).a(1-a)=a-y\\ \quad\\ dw=\frac{\partial{L}}{\partial{w}}=\frac{\partial{L}}{\partial{z}}.\frac{\partial{z}}{\partial{w}}=dz.x=x(a-y)\\ \quad\\ db=\frac{\partial{L}}{\partial{b}}=\frac{\partial{L}}{\partial{z}}.\frac{\partial{z}}{\partial{b}}=dz.1=a-y\\
da=∂a∂L=−ay+1−a1−ydz=∂z∂L=∂a∂L.∂z∂a=(−ay+1−a1−y).a(1−a)=a−ydw=∂w∂L=∂z∂L.∂w∂z=dz.x=x(a−y)db=∂b∂L=∂z∂L.∂b∂z=dz.1=a−y
sigmoid数学表达式和函数曲线:
s
i
g
m
o
i
d
=
1
1
+
e
−
z
sigmoid=\frac{1}{1+e^{-z}}
sigmoid=1+e−z1
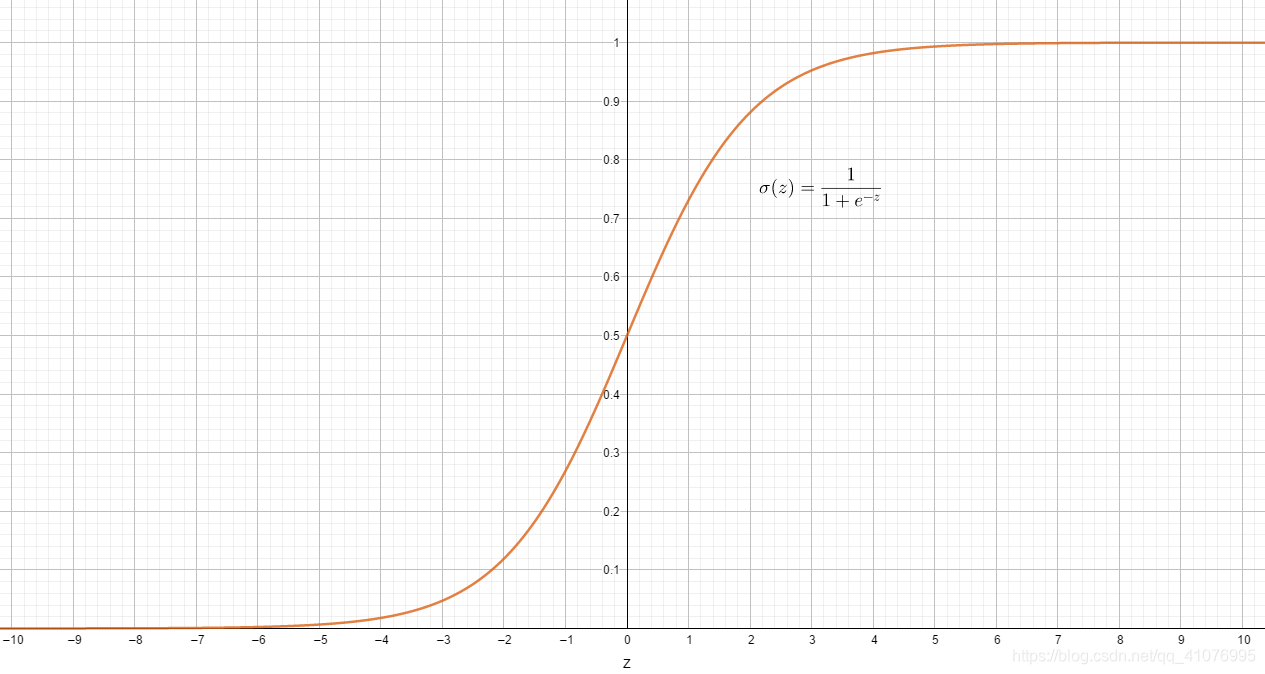
*函数图像由geogebra图形计算器画出,下载地址:链接:https://pan.baidu.com/s/1ZL-v56mbe7-Kcpu38i3YLg 提取码:r56n
从函数曲线,我们不难看出sigmoid的值域范围[0,1],当z越大,那么函数值越趋近于1,反之,当z越小,那么函数值越趋近于0,并且当z取到0时,函数值为0.5。通过以上我们可以看出逻辑回归用于概率预测和二分类是一个很好的选择。概率预测:函数的值域是[0,1]之间的数,刚好可以用来表示概率;二分类:当z=0是,函数的值为0.5,整个函数的值域为[0,1],所以z=0时,刚好可以当作一个中间值,在猫狗分类中,只有两个类别,不是猫就是狗,我们假设函数值<0.5代表猫,可以把小于0.5的划分为0类,很容易可以得出函数值>=0.5代表狗,划分为1类。
我们对sigmoid求一阶导数可得:
σ
(
x
)
=
σ
(
x
)
(
1
−
σ
(
x
)
)
\sigma(x)=\sigma(x)(1-\sigma(x))
σ(x)=σ(x)(1−σ(x))
sigmoid求导推导式如下:
s
i
g
m
o
i
d
:
s
(
x
)
=
1
1
+
e
−
x
倒
置
函
数
:
f
(
x
)
=
1
s
(
x
)
=
1
+
e
−
z
对
f
(
x
)
求
导
得
到
s
1
:
f
′
(
x
)
=
(
1
s
(
x
)
)
′
=
−
s
′
(
x
)
s
(
x
)
2
再
对
f
(
x
)
求
导
另
外
一
种
形
式
得
到
s
2
:
f
′
(
x
)
=
d
d
x
(
1
+
e
−
z
)
=
−
e
−
x
=
1
−
f
(
x
)
=
1
−
1
s
(
x
)
=
s
(
x
)
−
1
s
(
x
)
s
1
和
s
2
代
入
消
元
可
得
:
s
′
(
x
)
=
s
(
x
)
(
1
−
s
(
x
)
)
sigmoid:s(x)= \frac{1}{1+e^{-x}}\\ 倒置函数:f(x)=\frac{1}{s(x)}=1+e^{-z}\\ 对f(x)求导得到s1:\\ f^{'}(x)=(\frac{1}{s(x)})^{'}=-\frac{s^{'(x)}}{s(x)^{2}}\\ 再对f(x)求导另外一种形式得到s2:\\ f^{'}(x)=\frac{d}{dx}(1+e^{-z})=-e^{-x}=1-f(x)=1-\frac{1}{s(x)}=\frac{s(x)-1}{s(x)}\\ s1和s2代入消元可得:\\ s^{'}(x)=s(x)(1-s(x))
sigmoid:s(x)=1+e−x1倒置函数:f(x)=s(x)1=1+e−z对f(x)求导得到s1:f′(x)=(s(x)1)′=−s(x)2s′(x)再对f(x)求导另外一种形式得到s2:f′(x)=dxd(1+e−z)=−e−x=1−f(x)=1−s(x)1=s(x)s(x)−1s1和s2代入消元可得:s′(x)=s(x)(1−s(x))
*注:本文公式表达式均为LaTeX公式
在python可表示为:
import numpy as np
# activation function
def sigmoid(z, derivative=False):
sigmoid = 1.0/(1.0+np.exp(-z))
if (derivative==True):
return sigmoid * (1-sigmoid)
return sigmoid
前向计算就是从输入到输出,由神经网络计算得到预测输出的过程;反向传播则相反,为输出到输入,对参数w和b计算梯度的过程。
二次代价函数(quadratic cost):
J = 1 2 n ∑ x ∥ y ( x ) − a L ( x ) ∥ 2 J = \frac{1}{2n}\sum_x\Vert y(x)-a^L(x)\Vert^2 J=2n1x∑∥y(x)−aL(x)∥2
其中, J J J表示代价函数, x x x表示样本, y y y表示实际值, a a a表示输出值, n n n表示样本的总数。
使用梯度下降法(Gradient descent)来调整权值参数的大小,权值
w
w
w和偏置
b
b
b的梯度推导如下:
∂
J
∂
w
=
(
a
−
y
)
σ
′
(
z
)
x
∂
J
∂
b
=
(
a
−
y
)
σ
′
(
z
)
\frac{\partial J}{\partial w}=(a-y)\sigma'(z)x\\\frac{\partial J}{\partial b}=(a-y)\sigma'(z)
∂w∂J=(a−y)σ′(z)x∂b∂J=(a−y)σ′(z)
在使用sigmoid函数的情况下, 初始的代价(误差)越大,导致训练越慢。
交叉熵代价函数(cross-entropy):
J = − 1 n ∑ x [ y ln a + ( 1 − y ) ln ( 1 − a ) ] J = -\frac{1}{n}\sum_x[y\ln a + (1-y)\ln{(1-a)}] J=−n1x∑[ylna+(1−y)ln(1−a)]
其中, J J J表示代价函数, x x x表示样本, y y y表示实际值, a a a表示输出值, n n n表示样本的总数。
使用梯度下降法(Gradient descent)来调整权值参数的大小,权值w和偏执项b的梯度推导如下:
∂
J
∂
w
j
=
1
n
∑
x
x
j
(
σ
(
z
)
−
y
)
,
∂
J
∂
b
=
1
n
∑
x
(
σ
(
z
)
−
y
)
\frac{\partial J}{\partial w_j}=\frac{1}{n}\sum_{x}x_j(\sigma{(z)}-y)\;,\frac{\partial J}{\partial b}=\frac{1}{n}\sum_{x}(\sigma{(z)}-y)
∂wj∂J=n1x∑xj(σ(z)−y),∂b∂J=n1x∑(σ(z)−y)
当误差越大时,梯度就越大,权值
w
w
w和偏置
b
b
b调整就越快,训练的速度也就越快。
二次代价函数适合输出神经元是线性的情况,交叉熵代价函数适合输出神经元是S型函数的情况。
为什么要二次代价函数不如交叉熵代价函数???
通过 ∂ J ∂ w j \frac{\partial{J}}{\partial{w_j}} ∂wj∂J可知,权重和偏执的调整与 ∂ ′ z \partial^{'}{z} ∂′z没有关系,权重w的学习受到 σ ( z ) − y \sigma{(z)}-y σ(z)−y的影响,也就是标签与输出的误差,更大的误差,会有更快的学习速度。当误差越大,梯度就越大,w和b就调整的越快,模型就收敛的越快;而二次代价函数权重受到 ∂ ′ z \partial^{'}{z} ∂′z的影响,w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,那么w和b就调整的越快,模型就收敛的越快。
参考:
https://blog.youkuaiyun.com/red_stone1/article/details/77851177
https://blog.youkuaiyun.com/yqljxr/article/details/52075053


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









