







功能
在之前的工作中 XMLConfigBuilder 已经将 configuration 配置信息都解析过了,接下来就是mapper映射文件的解析。XMLMapperBuilder是专门负责解析mapper文件的。
第一步:首先根据你配置的mapper文件的路径,resouce、url或者是class、package来找到路径,如果是resource、url会有一个流资源的读取来解析,class与package则是另一种方式,通过MapperProxy代理来完成。
第二步:获取到资源,就是对常见的标签的解析,比如:namespace、cache-ref(引用其它命名空间的缓存配置)、cache(缓存配置)、parameterMap(入参map)、resultMap(结果封装集)、sql(sql块)、CRUD等标签,当然会对它们各自的属性也会做解析判断,比如parameterType(入参类型)、resultMap(结果集引用)、flushCache(每次调用清空本地一级二级缓存)、useCache(使用缓存)、statementType(执行语句的方式,一般都是预处理)
第三步:处理完成后就是将解析出来的mapperStatement放入configuration中
UML
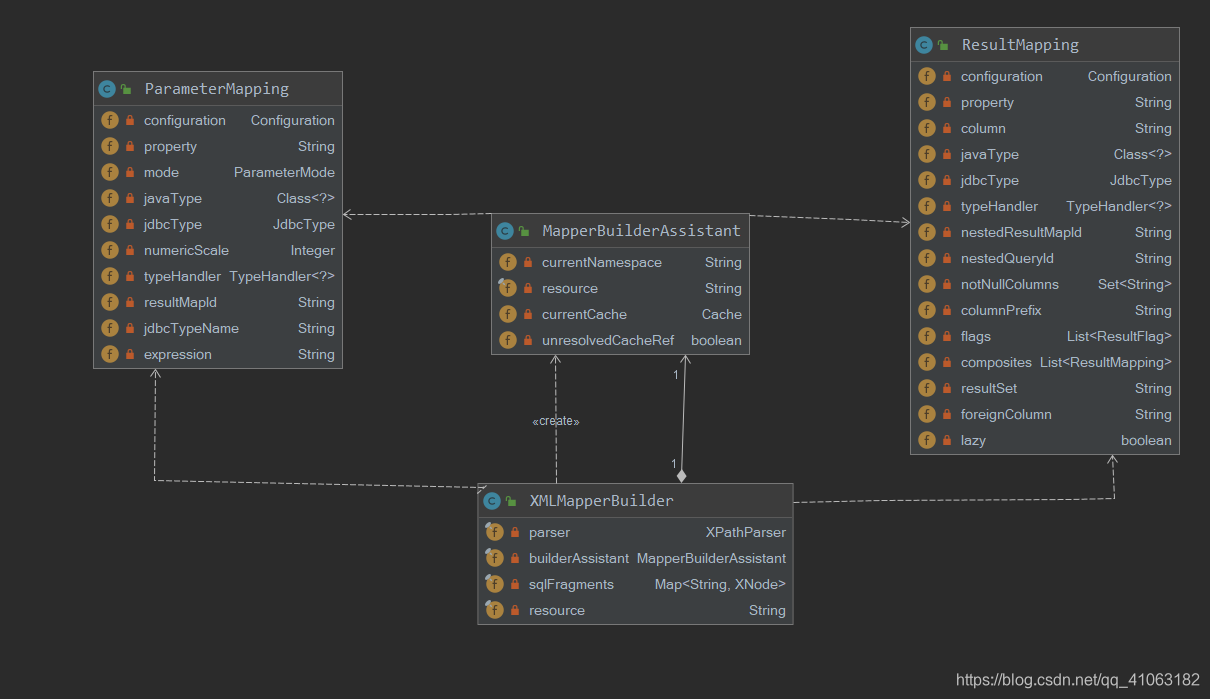
与 XMLMapperBuilder 相关的有几个重要的类,一个是 MapperBuilderAssistant,Assistant意思是助手,外国人起名字还是有意思的,MapperBuilderAssistant就是充当助手之类的作用,一些构建parameterMapping、resultMap等参数的功能都在这里边,然后就是ParameterMapping与ResultMapping,每个CRUD语句都有入参与返参,这些参数是如何在java内存中存放的以及是如何与数据库的数据对应的,其实都会封装在这两个类中,这两个类有些类似是元数据,每个mapping描述一种参数的数据, 所以一个入参Map会有多个ParameterMapping去描述它。
时序图
代码解析
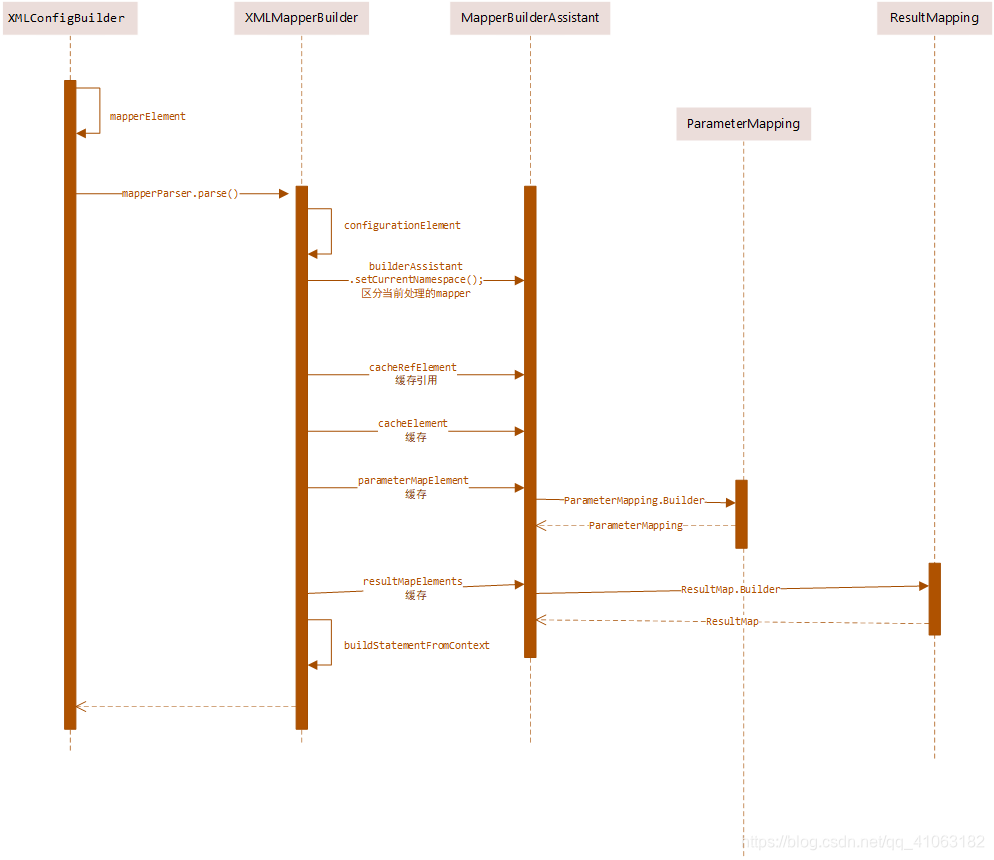
在XMLConfigBuilder 中有个mapperElement的方法,这个方法就是XMLMapperBuilder的入口,在这个方法中,会根据你配置的mapper路径来执行不同的策略,mapper的配置一般是有 package 、resource、url、class这四种,其中package与class是通过class类注解的方式来解析,而resource、url则是通过xml的方式来解析。
mybatis解析映射器是由两种方式的,基于class的其实会生成一个MapperProxyFactory代理并且通过MapperAnnotationBuilder的方式去parse(),我们现在先说基于xml配置的解析。
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// package方式直接扫描这个包下的类
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
// resource的方式,通过流读取进来
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
// url,通过流读取进来
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
获取到流之后会构建一个XMLMapperBuilder,这里会传入一个configuration.getSqlFragments()进来,这个东西其实就是之前解析出来的sql标签。构建好XMLMapperBuilder之后,就是调用parse()方法解析了,parse方法中其实是有几个有趣的地方的,一个是为了防止重复解析mapper会维护一个Set容器来保证幂等性,还有就是有一个兜底方案,会将之前解析异常的标签在解析一次。
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
// 解析mapper标签
configurationElement(parser.evalNode("/mapper"));
// 这一步其实是为了防止mapper重复解析
configuration.addLoadedResource(resource);
// 为xml的方式生成 MapperProxyFactory,是为了
bindMapperForNamespace();
}
// 解析失败的resultMaps、cacheRefs、statement会在这里再次解析一遍,其实是保底
// 我们设计系统的时候也可以考虑这里留一个口子
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
parse() 方法中最重要的其实是configurationElement()这个方法,mapper的一些属性以及标签都是在这里做的处理,比如cacheRef、cache、parameterMap、resultMap、sql、CRUD标签,不过看起来好像映射器配置文件中可以用到的标签也就这几个。cacheRefElement()、cacheElement()标签的解析其实还是很简单的,cacheRefElement()会通过MapperBuilderAssistant去查看configuration中是否有cache,没有则会抛异常,而cacheElement()则是直接通过MapperBuilderAssistant去构建一个cache出来。
private void configurationElement(XNode context) {
builderAssistant.setCurrentNamespace(namespace);
// 解析cacheRef
cacheRefElement(context.evalNode("cache-ref"));
// cache
cacheElement(context.evalNode("cache"));
// 解析入参parameterMap
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析resultMap
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析sql
sqlElement(context.evalNodes("/mapper/sql"));
// 解析CRUD,构建statement
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
}
}
mybatis其实是有一个parameterMap的标签的,不过一般这种标签在开发中没有用过,也是阅读源码的时候才发现对于入参的处理还有这样的一种用法,parameterMap的场景其实就是对于一些复杂入参的时候,可以动态的制定每个参数的javaType、jdbcType,handler等分别用什么处理,对于参数的控制比较细致。(官网:老式风格的参数映射。此元素已被废弃,并可能在将来被移除!请使用行内参数映射。文档中不会介绍此元素。)
哈哈,所以还是不要用了。不过有些场景下可以使用官方推荐的那种方式来控制诸如handler之类的属性处理,这种处理一般是传入一个map进来,其中有些参数可能有二义性,可以指定一下typeHandler防止出错。
where age = #{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
private void parameterMapElement(List<XNode> list) {
for (XNode parameterMapNode : list) {
String id = parameterMapNode.getStringAttribute("id");
String type = parameterMapNode.getStringAttribute("type");
Class<?> parameterClass = resolveClass(type);
List<XNode> parameterNodes = parameterMapNode.evalNodes("parameter");
List<ParameterMapping> parameterMappings = new ArrayList<>();
for (XNode parameterNode : parameterNodes) {
String property = parameterNode.getStringAttribute("property");
String javaType = parameterNode.getStringAttribute("javaType");
String jdbcType = parameterNode.getStringAttribute("jdbcType");
String resultMap = parameterNode.getStringAttribute("resultMap");
String mode = parameterNode.getStringAttribute("mode");
String typeHandler = parameterNode.getStringAttribute("typeHandler");
Integer numericScale = parameterNode.getIntAttribute("numericScale");
ParameterMode modeEnum = resolveParameterMode(mode);
Class<?> javaTypeClass = resolveClass(javaType);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
ParameterMapping parameterMapping = builderAssistant.buildParameterMapping(parameterClass, property, javaTypeClass, jdbcTypeEnum, resultMap, modeEnum, typeHandlerClass, numericScale);
parameterMappings.add(parameterMapping);
}
builderAssistant.addParameterMap(id, parameterClass, parameterMappings);
}
}
resultMap是mybatis中一个比较重要的配置了,使用频率也很高。解析resultMap的时候,首先会去解析你配置的类型限定等属性,在mybatis中如果同时配置了type、ofType、resultType、javaType等属性,生效的只有type,别问为什么,这个是因为代码中就这样写死了.。获取到type之后就会根据配置的type去验证是否存在这个类,这里有个细节,就是在验证这个类是否存在之前如果为别名会经过别名器去查找到它真正的全限定名。
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// 这里配置type、ofType、javaType都可以,不过会有一个先后顺序,因为在逻辑遍历写死了,哈!
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
......
}
// 解析别名
public <T> Class<T> resolveAlias(String string) {
try {
if (string == null) {
return null;
}
// issue #748
String key = string.toLowerCase(Locale.ENGLISH);
Class<T> value;
if (typeAliases.containsKey(key)) {
value = (Class<T>) typeAliases.get(key);
} else {
value = (Class<T>) Resources.classForName(string);
}
return value;
} catch (ClassNotFoundException e) {
throw new TypeException("Could not resolve type alias '" + string + "'. Cause: " + e, e);
}
}
type验证完之后,就是对mybatis的 constructor构造声明、discriminator分词、id主键的解析。id标签配置主键的这种方式大家应该经常用,可能constructor与discriminator不经常用。
mybatis是支持构造方法的这种注入的,如果你配置了构造标签,在实例化类时那么将注入你配置的column值到构造方法中,至于分词器,其实是一种类似switch的一种选择方式,会根据你配置的column的值去case不同的策略去映射。
<resultMap id="detailedBlogResultMap" type="Blog">
<constructor>
<idArg column="blog_id" javaType="int"/>
</constructor>
<discriminator javaType="int" column="draft">
<case value="1" resultType="DraftPost"/>
</discriminator>
</resultMap>
这里有个注意的地方是解析 constructor 或者 id时,会往 flags 这个内存中塞进去自己对应的枚举,这个作用是为了表明当前到底用的是constructor 这种构造方法的方式去声明当前resultMap的主键还是通过id标签去声明当前resultMap的主键。constructor 与 id 的用法二者用一就可以。再往下的方法可以看到,就是解析autoMapping是否开启自动映射等属性。
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
......
// 分词器,类似switch,会根据值去case对应的映射
Discriminator discriminator = null;
List<ResultMapping> resultMappings = new ArrayList<>();
resultMappings.addAll(additionalResultMappings);
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
// 解析 id autoMapping是否自动映射等属性
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
XMLConfigBuilder 中解析resultMap的常规标签(除了分词器)的具体属性其实是在buildResultMappingFromContext中,这里会将配置的属性标签解析成为一个个resultMapping。
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
String property;
// 之前的 flag
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
// construct 则去name
property = context.getStringAttribute("name");
} else {
// id则去property 这个与配置相关
property = context.getStringAttribute("property");
}
// 数据库中的列名,或者是列的别名
String column = context.getStringAttribute("column");
// 对应的java类型
String javaType = context.getStringAttribute("javaType");
// 对应的数据库类型
String jdbcType = context.getStringAttribute("jdbcType");
// 是否有复杂的子查询,select是用来关联这个的
String nestedSelect = context.getStringAttribute("select");
// 嵌套
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections.emptyList(), resultType));
// 设置某些列非空时才会创建对象
String notNullColumn = context.getStringAttribute("notNullColumn");
String columnPrefix = context.getStringAttribute("columnPrefix");
// 类型映射处理器
String typeHandler = context.getStringAttribute("typeHandler");
String resultSet = context.getStringAttribute("resultSet");
String foreignColumn = context.getStringAttribute("foreignColumn");
// 是否懒加载
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
Class<?> javaTypeClass = resolveClass(javaType);
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
解析完成后最终调用助手类的buildResultMapping方法去构建一个resultMapping出来,在这里会做一个验证,验证你配置的type或者是handler是否存在。
public ResultMapping buildResultMapping(Class<?> resultType,String property,String column,Class<?> javaType,JdbcType jdbcType, String nestedSelect,String nestedResultMap, String notNullColumn, String columnPrefix, Class<? extends TypeHandler<?>> typeHandler, List<ResultFlag> flags,String resultSet,String foreignColumn,boolean lazy) {
Class<?> javaTypeClass = resolveResultJavaType(resultType, property, javaType);
TypeHandler<?> typeHandlerInstance = resolveTypeHandler(javaTypeClass, typeHandler);
List<ResultMapping> composites;
if ((nestedSelect == null || nestedSelect.isEmpty()) && (foreignColumn == null || foreignColumn.isEmpty())) {
composites = Collections.emptyList();
} else {
composites = parseCompositeColumnName(column);
}
return new ResultMapping.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))
.resultSet(resultSet)
.typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList<>() : flags)
.composites(composites)
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix)
.foreignColumn(foreignColumn)
.lazy(lazy)
.build();
}
在mapperElementt()方法中最末尾有个resultMapResolver.resolve()方法,这个方法其实就是将解析好的resultMappings放入到configuration中,不过会有一个差量的过程去将原有的以及现有的全部都容纳在一起。
ResultMap 的一些不常用属性标签解析
association 标签
一个复杂类型的关联,相当与有对象的关联关系时,自动生成一个嵌套对象,注意,一个嵌套结果映射 – 关联可以是 resultMap 元素,或是对其它结果映射的引用
<resultMap id="detailedBlogResultMap" type="Blog">
<constructor>
<idArg column="blog_id" javaType="int"/>
</constructor>
<association property="author" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
<result property="favouriteSection" column="author_favourite_section"/>
</association>
</resultMap>
select标签
用于加载复杂类型属性的映射语句的 ID,它会从 column 属性指定的列中检索数据,作为参数传递给目标 select 语句。 具体请参考下面的例子。注意:在使用复合主键的时候,你可以使用 column="{prop1=col1,prop2=col2}" 这样的语法来指定多个传递给嵌套 Select 查询语句的列名。这会使得 prop1 和 prop2 作为参数对象,被设置为对应嵌套 Select 语句的参数。
如下所示,会将selectAuthor的结果复制给author这个字段。
<resultMap id="blogResult" type="Blog">
<association property="author" column="author_id" javaType="Author" select="selectAuthor"/>
</resultMap>
<select id="selectBlog" resultMap="blogResult">
SELECT * FROM BLOG WHERE ID = #{id}
</select>
<select id="selectAuthor" resultType="Author">
SELECT * FROM AUTHOR WHERE ID = #{id}
</select>
mapper映射文件中常见的标签解析完成之后,就是CRUD标签的解析了,CRUD标签的解析是在XMLStatementBuilder中完成的。

















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









