






- Json
字符串形式:import json
#将python转为Json
a={"name":"冯国兴","age":18,"gender":"man"}
str_json=json.dumps(a)
print(str_json)
#将Json转为python
s=json.loads(str_json)
print(s)
- 文件格式json.dump和json.load
import json a=[1,5,5] with open("j.json","w") as f: json.dump(a,f) with open("j.json","r") as e: date=json.load(e) print(date)
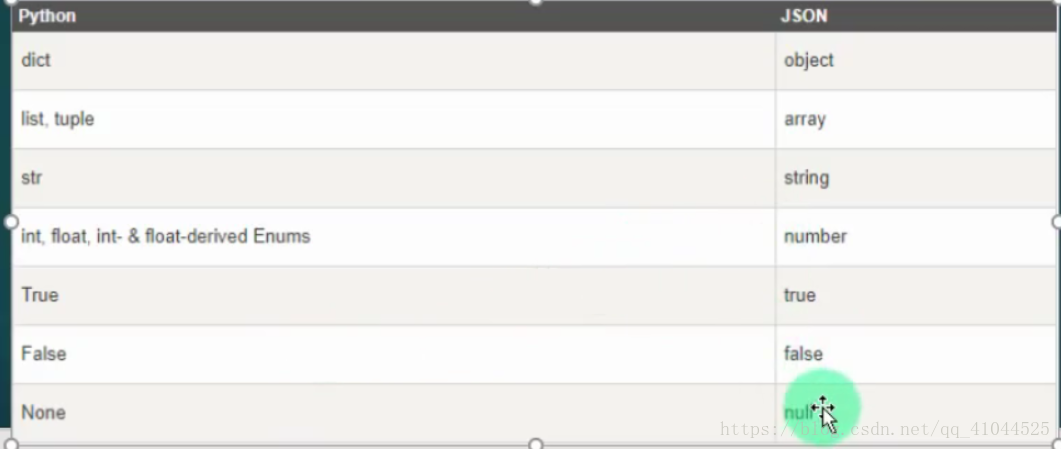
XML
python解析方法主要有三种:Sax,DOM 以及ElementTree
Sax:用时间驱动模型会牵扯到解析器和事件处理器。优点:Sax读取文件较快,占用内存少。缺点:需要用户回调函数
DOM:将XML数据在内存中解析成一个数,通过对树的操作来操作XML,DOM解析XML文档时,一次性读取整个文档
优点:不需要对状态进行追踪,因为每个节点都知道谁是父节点,谁是子节点
缺点:DML需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,使用起来比较麻烦

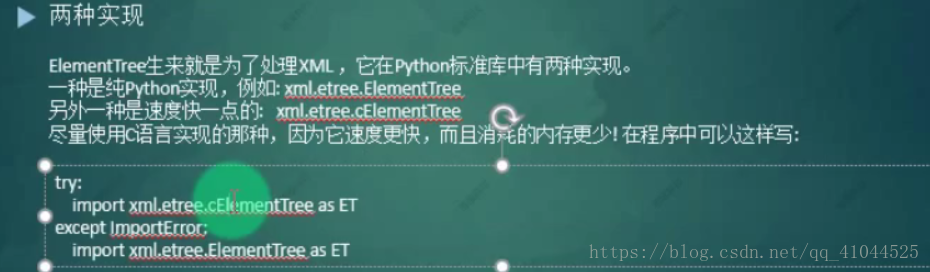
ElementTree:轻量级的DOM,具有方便友好的API,代码可用性好速度快,内存消耗少
当要获取属性值时,用attrib方法
当要获取节点值时,用text方法
当要获取节点名时,要tag方法
import xml.etree.cElementTree as ET tree=ET.parse("movies.xml") root=tree.getroot() print(root.tag,root.attrib) #遍历所有movie标签 for movie in root.findall("movie"): type=movie.find("type").text format = movie.find("format").text rating = movie.find("rating").text stars = movie.find("stars").text description = movie.find("description").text print(type) print(format) print(rating) print(stars) print(description) print("ddddddddddd") for movie in root.findall("movie")[0:3]: year=movie.find("year").text print(year)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









