




该系列主要是听李宏毅老师的《深度强化学习》过程中记下的一些听课心得,除了李宏毅老师的强化学习课程之外,为保证内容的完整性,我还参考了一些其他的课程,包括周博磊老师的《强化学习纲要》、李科浇老师的《百度强化学习》以及多个强化学习的经典资料作为补充。
笔记【4】到笔记【11】为李宏毅《深度强化学习》的部分;
笔记 【1】和笔记 【2】根据《强化学习纲要》整理而来;
笔记 【3】 和笔记 【12】根据《百度强化学习》 整理而来。
一、Q表格
(1)Q-table
MDP包括{S,A,R,P}四个要素,其中R为奖励函数,P为环境的状态转移概率,即环境不确定度,但是以上两个因素很多情况下是未知的,这时就需要使用无模型(model-free)的方法。
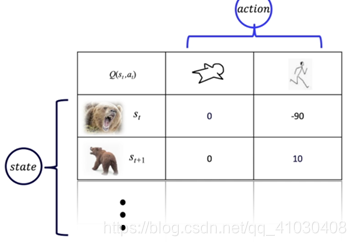
图1. Q表格示意图
Q-table可以形象地将其称为生活手册,因为其表示了在不同动作和状态之下所得到的Q函数(我觉得Q函数可以理解为在action与state共同作用下的value,是V函数的升级版),该表格中横为动作a,纵为状态s,表格里面是Q(s,a),如图1所示。
Q-table可以作为一种我们强化学习之后得到的结果,也就是输出。为了得到这个输出,我们可以使用model-based或者model-free的方法进行训练,具体使用哪种方法根据环境是否已知来决定。今天我们聚焦在model-free方法。
在model-free的强化学习之下,要得到Q-table,首先需要将该表格初始化,之后通过agent与环境的交互来不断更新Q-table。要更新,在model-free的情况下,我们可以想到使用MC(蒙特卡洛)或者TD(Temporal Difference,时序差分)的方法来解决。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









