








 超级会员免费看
超级会员免费看


使用Python,OpenCV,Tesseract-OCR对自己的运动数据图片进行识别及分析,并使用Matplotlib绘制配速图出来
-
- 1. 效果图
- 2. 源码
- 3. 全量源码及运动图片资源
- 参考
主要分为
- 目录下图片解析及读取;
- 拼九宫格图片出来,可以自由配置(m*n)取决于自己有多少张运动图片
- 遍历图片并进行运动数据OCR识别,并绘制识别结果在原始图
- 对绘制ocr识别文本之后的图片进行拼图呈现;
- 使用matplotlib对运动时间、耗时、最快配速、最慢配速、平均配速等数据进行绘制散点图和折线图
1. 效果图
原始图片拼图呈现:
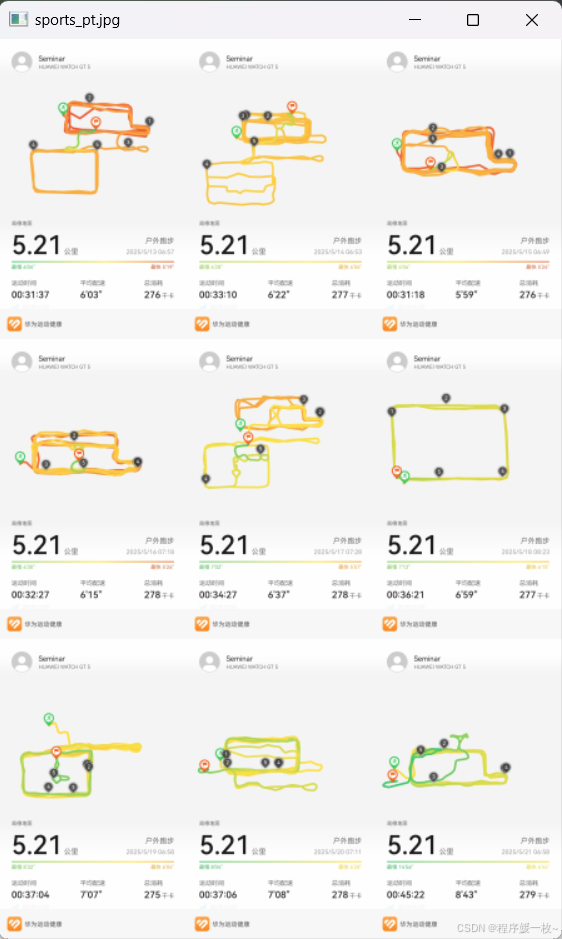
原图 VS 绘制运动区域绿框图对比展示:
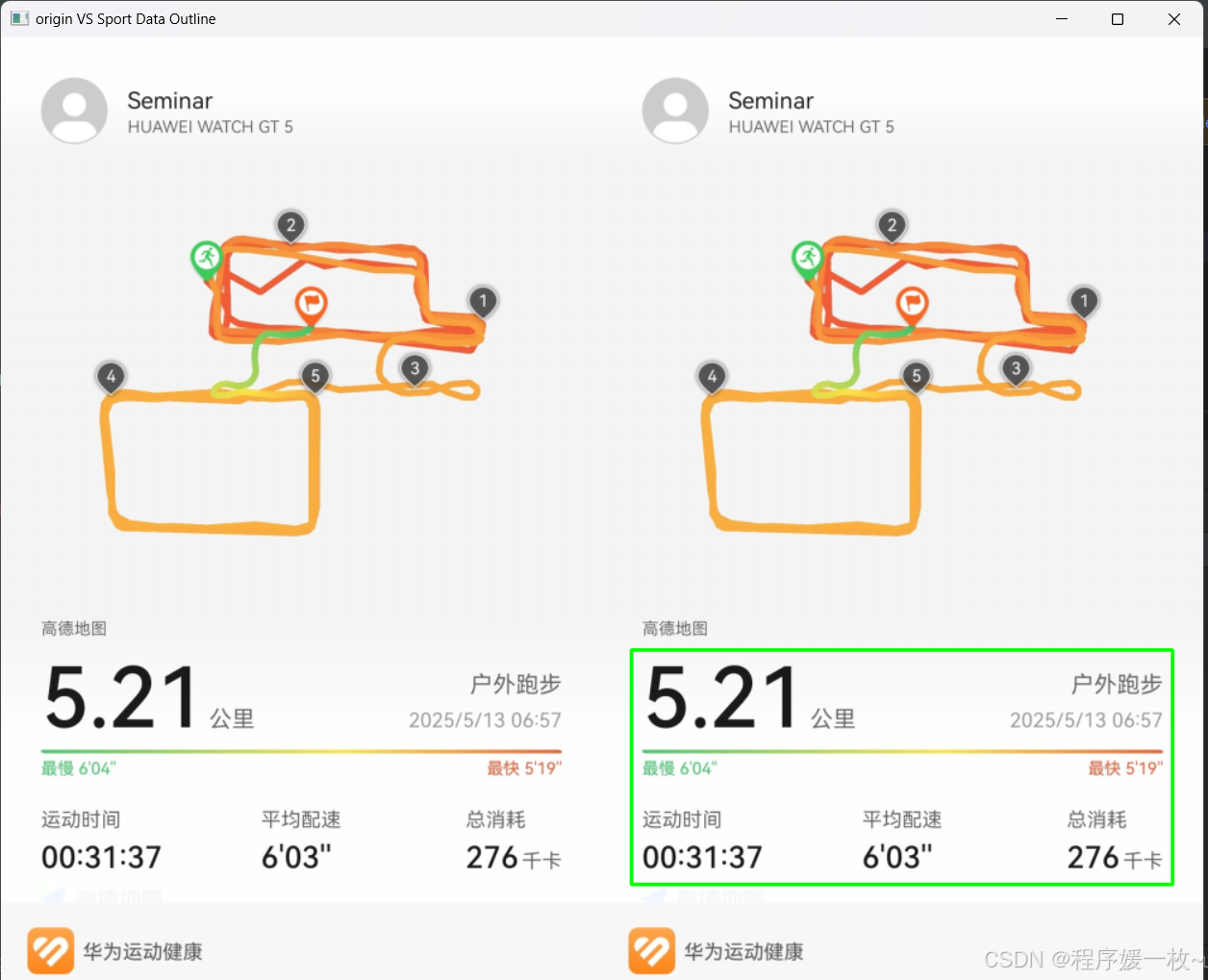
运动数据区域截图及识别数据绘制原图展示:
在原图右中绘制识别到的数据:
分别是运动时间、距离、运动时长、最快配速、最慢配速、平均配速、消耗卡卡;
可以看到也不是识别的100%准确,有俩天5.19,5.20识别的平均配速和最慢配速不太对…

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











