



 本文探讨了影响数据库性能的因素,包括SQL查询速度、服务器硬件、网卡流量、磁盘I/O、QPS和TPS。分析了大表、大事务对数据库性能的影响,并提出了分库分表、历史数据归档、事务管理等优化策略。
本文探讨了影响数据库性能的因素,包括SQL查询速度、服务器硬件、网卡流量、磁盘I/O、QPS和TPS。分析了大表、大事务对数据库性能的影响,并提出了分库分表、历史数据归档、事务管理等优化策略。
在主服务器中不要远程备份,或者在大型活动之前停止远程备份等耗费资源的操作
影响数据库查询性能因素:sql查询速度,服务器硬件,网卡流量,磁盘IO
超高QPS和TPS会影响sql查询效率
QPS是一秒钟处理请求的数量
大多数80%的优化都可以通过慢查询解决,优化sql
风险:大量的并发和超高的CPU使用率
大量的并发:数据库连接数被占满(max_connections默认100)
超高的CPU使用率:因CPU资源耗尽而出现宕机
磁盘IO风险:磁盘IO性能突然下降(使用更快的磁盘设备),其他大量消耗磁盘性能
的计划任务(调整计划任务,做好磁盘维护)
网卡流量风险:网卡IO被占满,可避免无法连接数据库的情况:减少从服务器数量,进行分级缓存
,避免使用select * 进行查询,分离业务网络和服务网络
还有什么会影响数据库性能:大表和大事务
大表:1、记录行数巨大,单表超过千万行数据
2、表数据文件巨大,表数据文件超过10G
大表对DDL操作的影响:
1、建立索引需要很长时间,mysql版本<5.5建立索引会锁表
mysql版本>=5.5不会锁表但是会引起主从延迟。
2、修改表结构需要长时间锁表:会造成长时间的主从延迟。影响正常的数据操作
如何处理数据库中的大表:
一、分库分表将一张大表分成多个小表:难点:①分表主键的选择
②分表后跨分区数据的查询和统计
二、对大表进行历史数据归档--会减少对前后端业务的影响
前端表结构无变化,影响不大,不过需要增加一个历史查询的入口。(归档表可放在另一个服务器上)
难点:第一个难点,归档时间点的选择。(归档数据很少使用,如订单列表归档一年前的数据,日志类的归档一周前的数据)
第二个难点,如何进行归档,对大表的增删改查需要特别小心(轻则主从延迟,重则造成阻塞,影响正常访问)
大事务:什么是事务--事务是数据库系统区别于其他一切文件系统的重要特征之一(数据库服务器崩溃后可以恢复崩溃前的数据,保存数据的一致性)
事务是一组具有原子性的sql语句,或是一个独立的工作单元
(事务中的sql要么全部完成要么全部失败)
事务四大特性:原子性,一致性,隔离性,持久性
原子性:事务要么全部成功,要么全部失败
一致性:在事务开始之前和事务结束之后,都必须保持一致性状态
隔离性:在一个事务未结束之前对于其他事务是不可见的
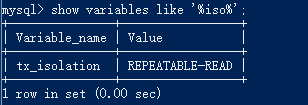
mysql隔离级别默认可重复读
(四种隔离性:未提交读,事务可以读取未提交的数据,脏读(不建议使用)。
已提交读(默认隔离级别已提交读,mysql是例外默认可重复读),只能读取已提交的数据。
可重复读
可串行化
(四种隔离级别的并发性由高到底)
持久性:事务一旦提交,所做的更改就会永久保存到数据库中
什么是大事务:运行时间比较长,操作的数据比较多的事务
风险:1、锁定太多数据,造成大量的阻塞和超时
2、回滚所需要的时间比较长。
3、容易造成主从延迟
如何处理大事务:避免一次性处理太多的数据(增删改查),可以分批次来进行操作
移出不必要的select的操作

















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









