










Pycharm中配置Pytorch相关环境
一、对于新手来说,首先应该了解什么环境、什么是解释器?
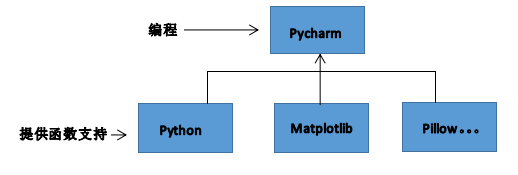
所谓的环境就是,基于你的项目所需要的相关库。比如我们现在做一个深度学习分类项目(基于深度学习框架Pytorch)(在这里,又得说一点,深度学习的框架有很多种,比如还有tensorflow等,这些框架都是大同小异的,都可以调用其中的函数搭建你所需要的深度学习网络框架)。在分类的项目中,不可避免的我们需要一些图像读取、张量运算、卷积运算、池化、图像显示、图表的绘制,而Pytorch、matplotlib、QT5、Pillow等就是包含这些一系列操作的函数,你自然需要把它们加载到你的编程环境下。
所谓的配置Pytorch相关环境,也就是如何将Pytorch、matplotlib、QT5、Pillow等lib加载到你的环境。
那什么是解释器呢?越高级的语言解释器就越为高级,我们在Pycharm中编写的程序要能够被系统机器所识别,就需要有一个解释器去解释我们编写的程序,这个解释器就是python.exe。
注:Pycharm可以说是一个集成的编译器,像anacaonda一样,都是可以在ide内部下载安装进环境所需要的库。
二、如何在Pycharm中加载python解释器
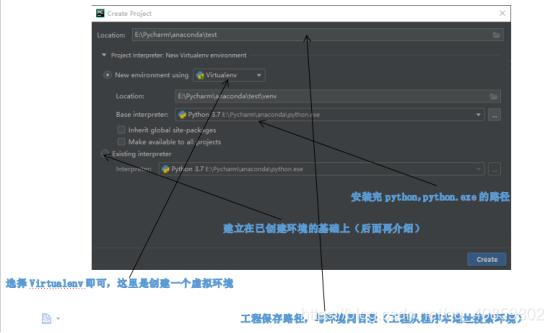
1、首先打开Pycharm,点击File->New projects,弹出以下框
Python直接在官网https://www.python.org/下载即可,下载完可在cmd命令窗口确定是否安装。
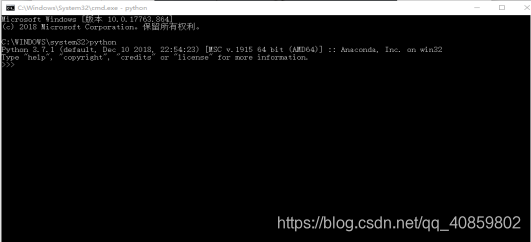
我安装的是python3.7,故出现Python 3.7.1(。。。)
2、点击create就可以完成python环境的配置了
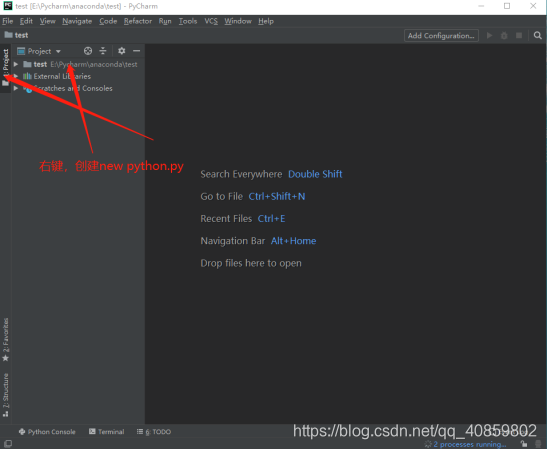
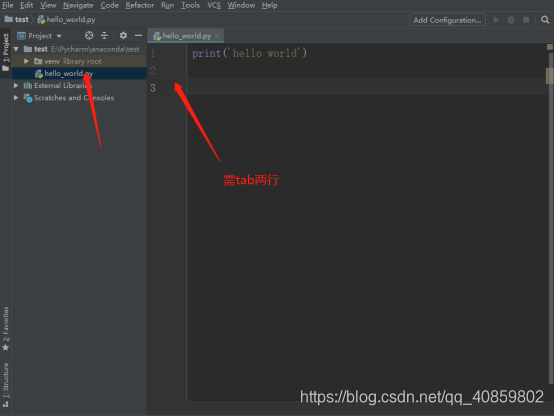
若能正确打印出 hello world 则python配置完成
3、配置Pytorch环境
点击File->settings 弹出
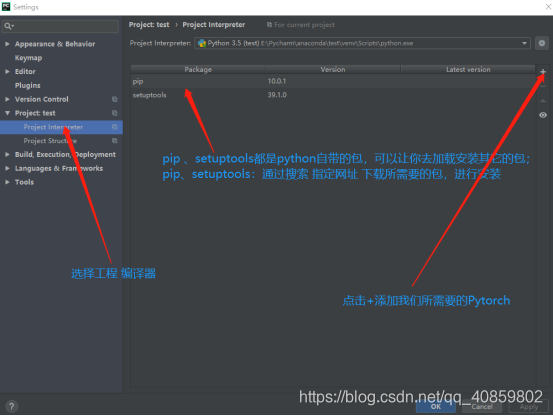
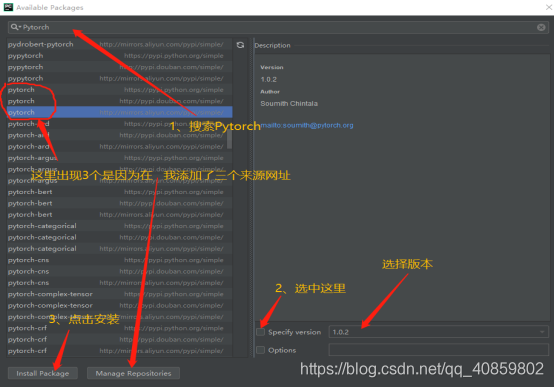
正常情况下,点击intall后,等待一会就可以看到安装成功。但入门即遇,往往这里都会显示error occur:uninstall
4、这里有一点值得提的是:无论在pycharm还是在anaconda中配置环境,比如说安装一个Pytorch1.2.0的库,其背后都是调用cmd命令去下载安装Pytorch。也就是说,‘3、配置Pytorch环境’完全可以由一句在cmd中的指令去完成->
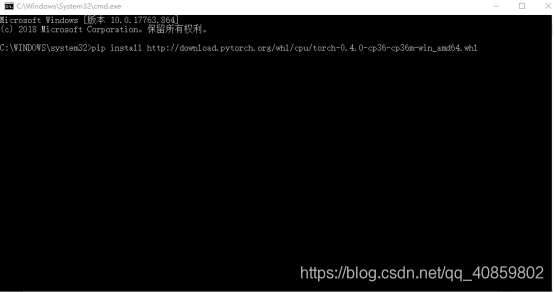
点击enter后,将自动从指定路径中下载Pytorch
如果你在‘3、配置Pytorch环境’步骤安装失败,这时候重新搜索安装一下,一般就可以了。
至于pip的路径,百度一下很快就能找到。
(值得注意的是,应该了解一些pip的配置环境的相关指令)
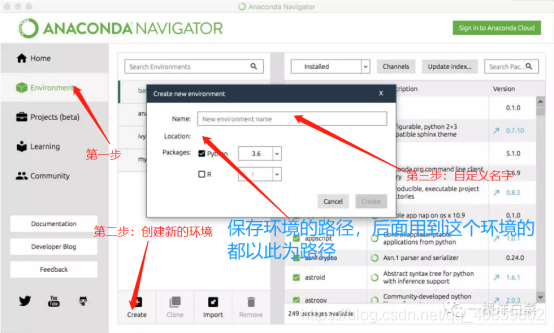
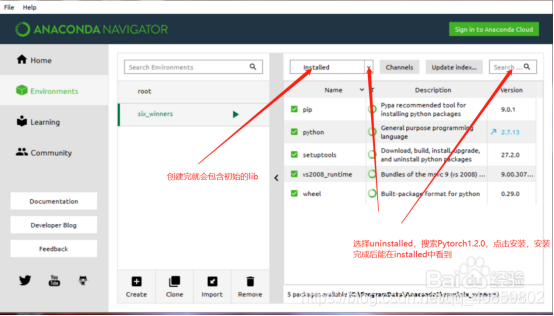
5、这里介绍通过anaconda创建自己的环境,也就是前文所说到,一开始创建工程就可以直接调用自己创建的环境。
打开anaconda navigator

















06-25
 3884
3884
3884
10-27
1373
1373
07-22
585
585
03-23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









