







RLHF 中主流强化学习算法的损失函数表达式及对比分析
1. 近端策略优化(PPO)
-
损失函数:
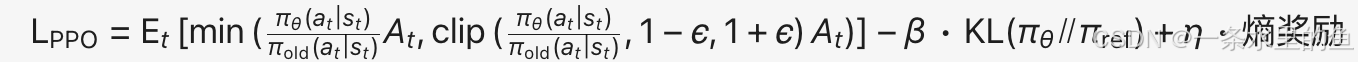 组成:
组成:- 剪切代理目标(Clip Objective):限制策略更新幅度,防止剧烈偏移。
- KL 散度惩罚:约束新策略与参考策略(如 SFT 模型)的偏离程度。
- 熵奖励:鼓励探索,避免策略过早收敛
特点: 需要同时维护策略模型(Actor)、价值函数模型(Critic)、参考模型(Ref Model)和奖励模型(RM),计算复杂度高,但稳定性强
2. 直接偏好优化(DPO)
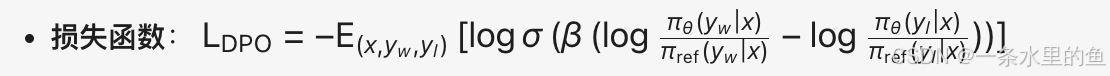
- 核心思想: 通过隐式奖励模型(即策略自身)替代显式奖励模型,直接优化人类偏好数据中的胜率差 <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









