







 RAFT是伯克利大学提出的一种训练方法,用于微调语言模型以适应特定领域的检索增强生成任务。通过区分“oracle”(含答案)和“distractor”(不含答案)文档,以及训练模型生成链式思维答案,提升模型在有干扰文档情况下的性能。实验证明,RAFT在多个领域如医学、编程API等优于基线模型,且包含适量不相关文档的训练数据能提高模型效果。
RAFT是伯克利大学提出的一种训练方法,用于微调语言模型以适应特定领域的检索增强生成任务。通过区分“oracle”(含答案)和“distractor”(不含答案)文档,以及训练模型生成链式思维答案,提升模型在有干扰文档情况下的性能。实验证明,RAFT在多个领域如医学、编程API等优于基线模型,且包含适量不相关文档的训练数据能提高模型效果。
今天来介绍下伯克利大学3.15日新发的一篇paper,RAFT: Adapting Language Model to Domain Specific RAG
主要研究了如何构造训练数据来微调你的LLM,从而在LLM在垂直领域的RAG中表现更好。并且开源了代码:GitHub - ShishirPatil/gorilla: Gorilla: An API store for LLMs
主要工作:
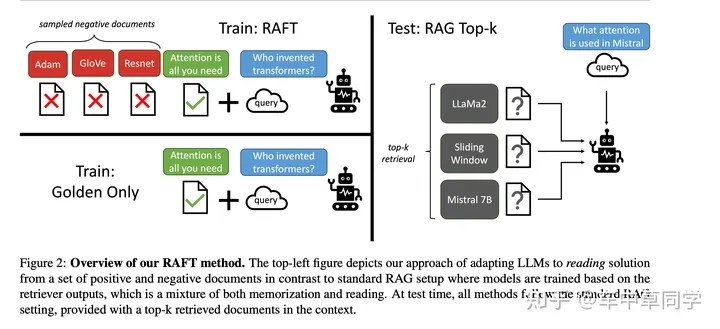
1、Retrieval Augmented Fine Tuning (RAFT):RAFT是一种训练方法,旨在通过微调来适应特定领域的开卷考试设置,即领域特定的RAG。
2、区分文档类型:在训练数据中,区分“oracle”文档(包含问题答案的文档)和“distractor”文档(不包含答案相关信息的文档)。
3、链式思维风格答案:RAFT训练模型生成包含链式思维的答案,这些答案引用了上下文中的原始文档,并详细解释了如何基于引用得出结论。
4、处理干扰文档:在训练过程中,模型被训练以在存在干扰文档的情况下回答问题,这有助于提高模型在测试时对检索结果的鲁棒性。
训练数据是如何构造的?
其实作者在论文中没有明说,只是给了一个示例。笔者看代码搞清楚了这一过程。现在阐述如下。
1.对于一个pdf,先把pdf切分成chunk,也就是产生多个doc。
2.利用chatgpt4为每一个doc,生成多个query。
def generate_instructions_gen(chunk: Any, x: int = 5) -> list[str]:
"""
Generates `x` questions / use cases for `chunk`. Used when the input document is of general types
`pdf`, `json`, or `txt`.
"""
response = client.chat.completions.create(
model= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









