






目录
一、定义
输入特征 x,通过找到的函数function输出数值Scalar
应用举例:
- 股市预测(Stock market forecast)
- 输入:过去10年股票的变动、新闻咨询、公司并购咨询等
- 输出:预测股市明天的平均值
- 自动驾驶(Self-driving Car)
- 输入:无人车上的各个sensor的数据,例如路况、测出的车距等
- 输出:方向盘的角度
- 商品推荐(Recommendation)
- 输入:商品A的特性,商品B的特性
- 输出:购买商品B的可能性
- Pokemon精灵攻击力预测(Combat Power of a pokemon):
- 输入:进化前的CP值、物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)
- 输出:进化后的CP值
- 下面的模型也以该例为基础进行展示
二、模型步骤
step1:模型假设,选择模型框架(线性模型)
1. 一元线性模型
即模型为单个输入特征,线性模型假设为
2. 多元线性模型
即模型为多个输入特征,线性模型假设为
其中表示输入的多个特征,
表示各输入特征的权重,b表示偏移量
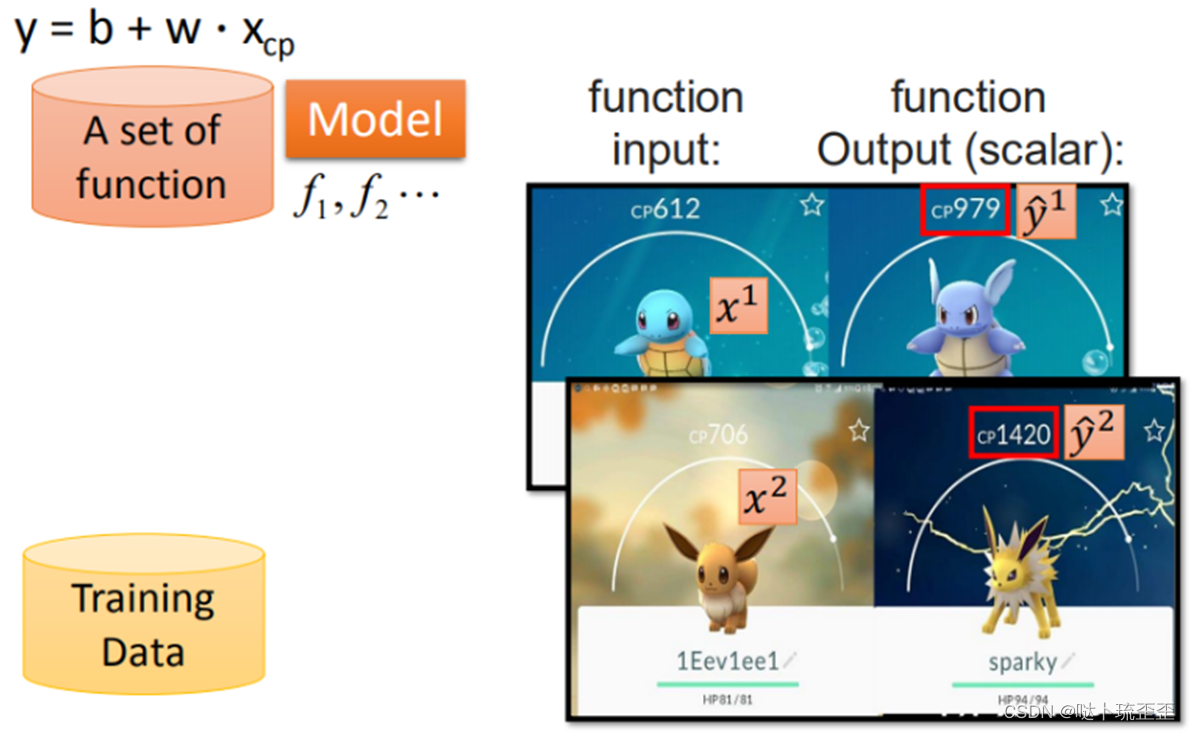
图中为进化前的CP值,
表进化后的CP值,即输出的Scalar,
所代表的是真实值
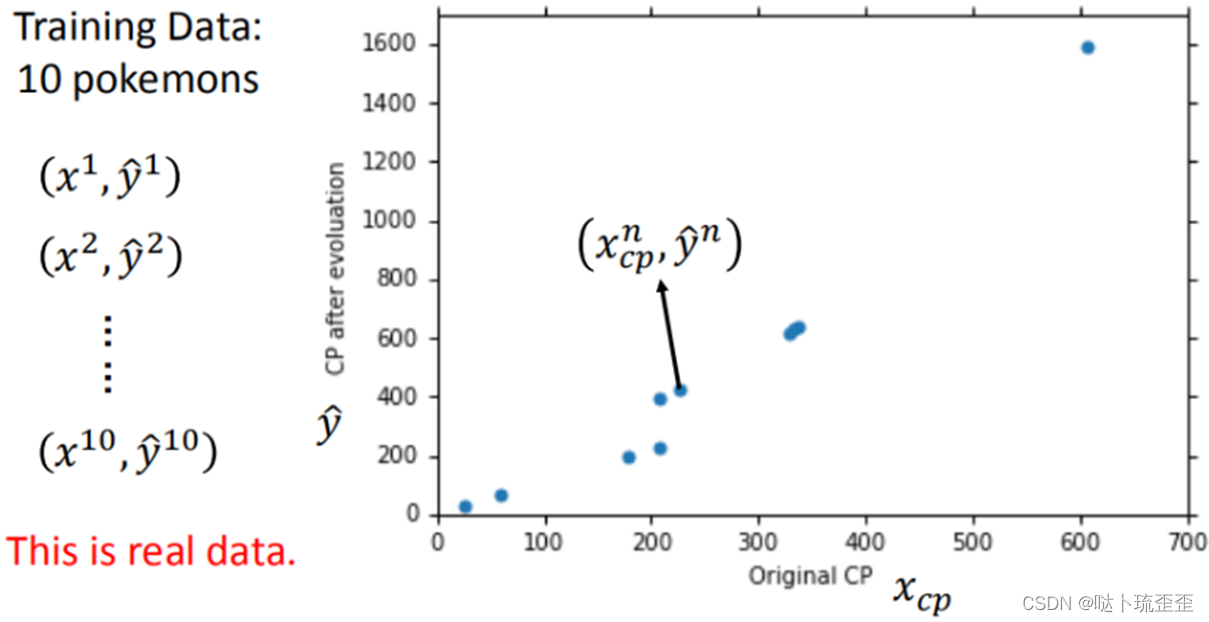
上图为10组数据在二维图中的展示,每一个点代表输入进化前的CP值和进化后的CP值
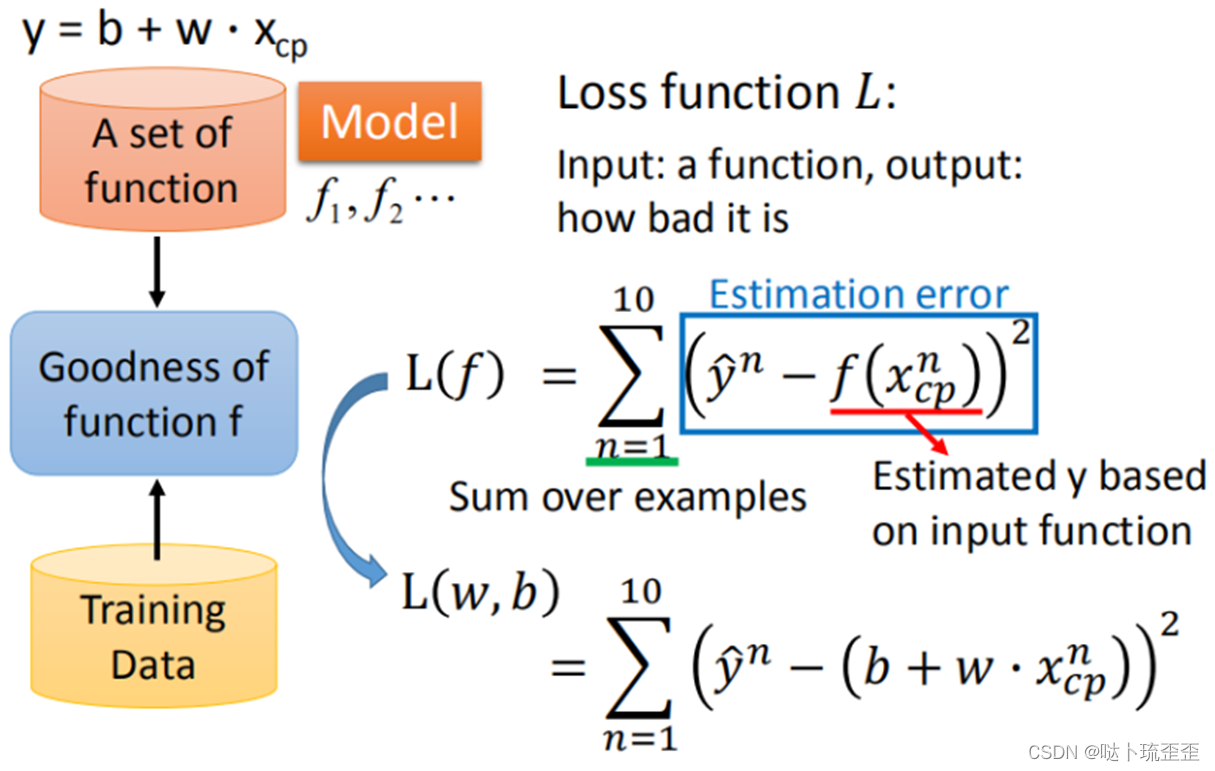
step2:模型评估,判断模型的好坏(损失函数)
我们可以将损失函数(Loss Function)理解成函数的函数,输入的是一个function,输出的是该function不好的程度。对于本例,使用距离即计算进化后的CP值与模型预测的CP值之间的的差值来判定模型的好坏,即计算的和,和越小,该模型越好。
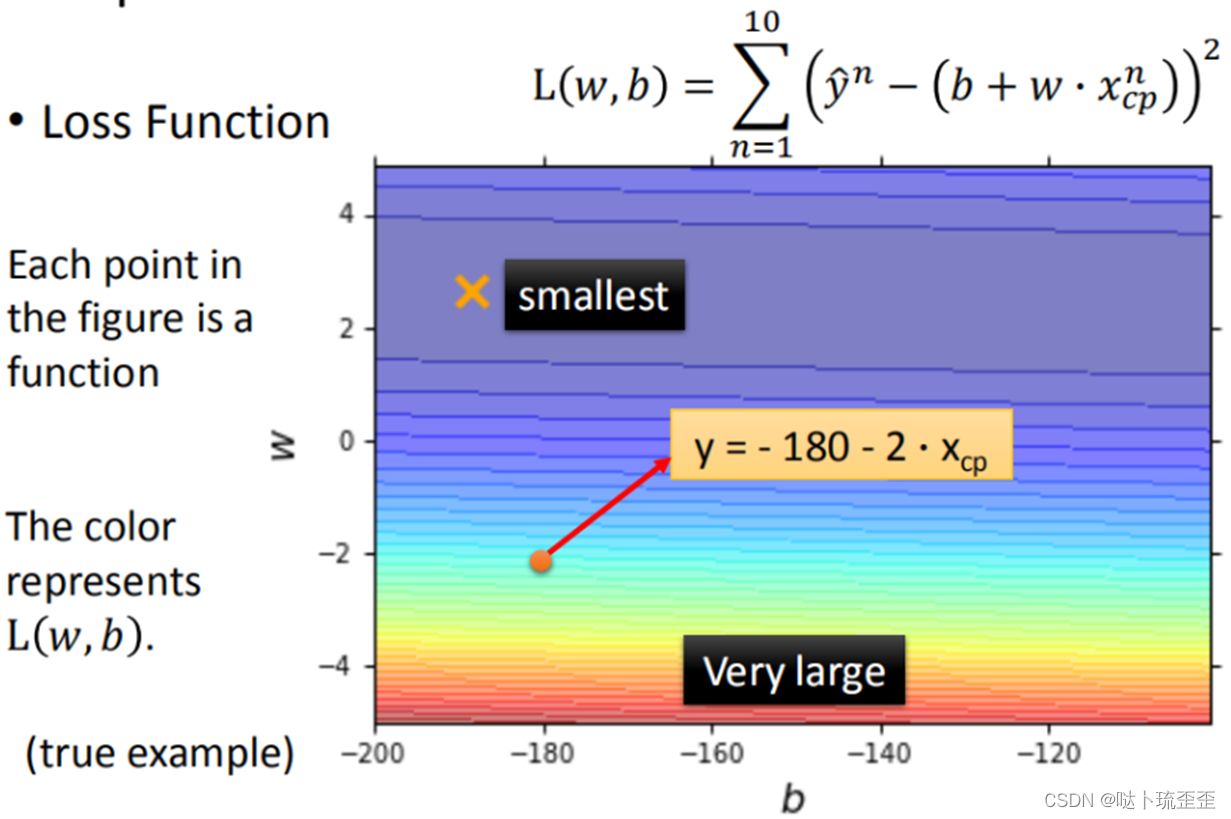
和b
在二维坐标图中的情况如下图所示,图中每一个点代表一个function,颜色代表根据所定义的损失函数该function效果好坏的程度。点所处的区域颜色越红越靠近图片下方,代表代表该function的效果越差。
step3:模型优化,筛选最优的模型(梯度下降)
最终需要找到使得损失函数的值达到最小的
,下图展示的即为该模型中的最优化问题。
我们使用梯度下降法(Gradient Descent)求解该问题,该方法的优点在于只要损失函数可微分,则该问题就可求解。
梯度下降(Gradient Descent)
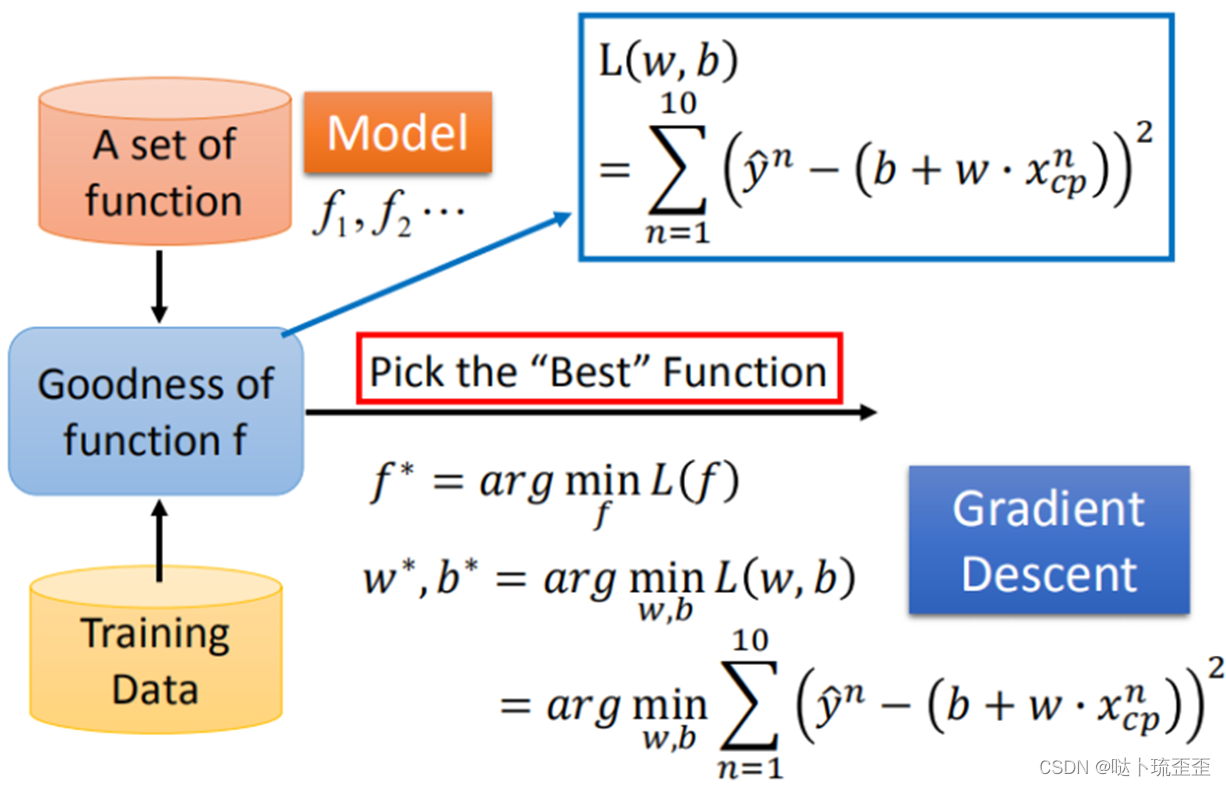
先从最简单的只有一个参数入手,定义
穷举所有可能值,并代入损失函数
中求不同
下的损失。随机选取一个初始的
,计算
在
时的微分(即切线斜率),若小于0(即图中所示情况),说明
左边的损失较高,右边损失较低,我们需要寻找使得损失函数
达到最小的
,所以此时应该增大
的值;反之,应减小
的值。
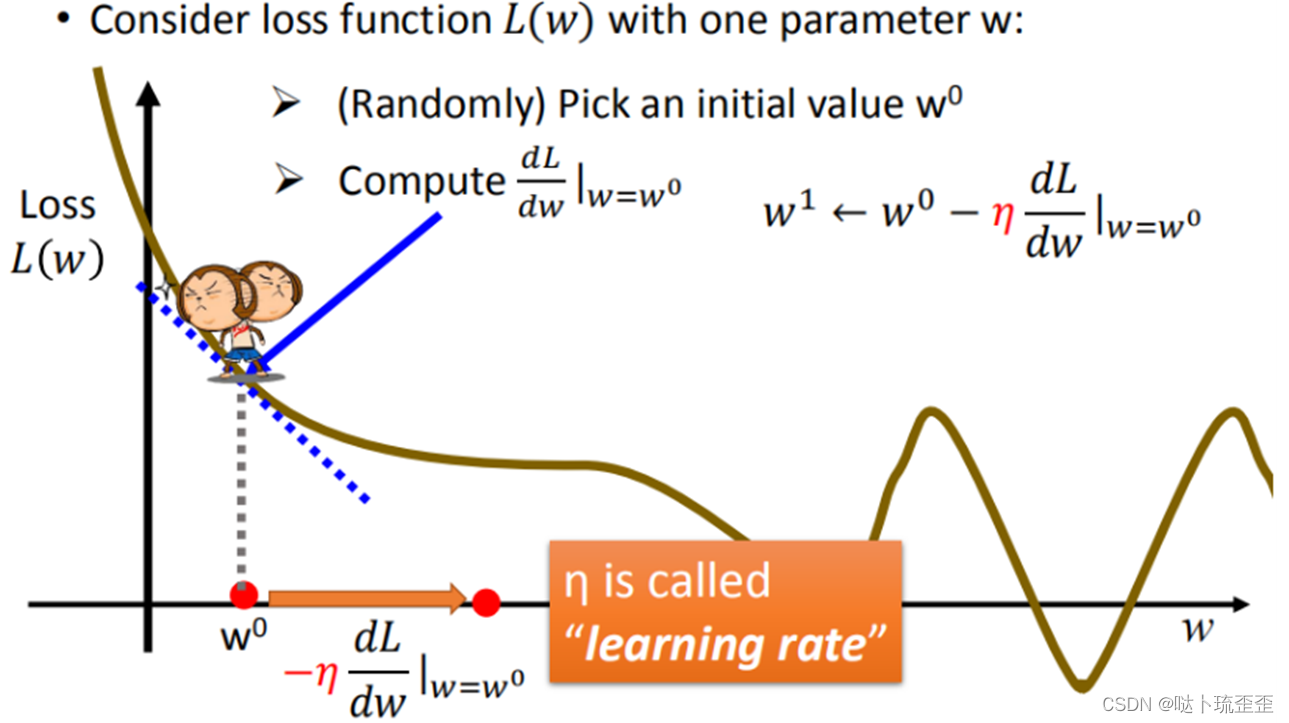
寻找下一个时应该增大或减小的量取决于两个因素,一个是
在
时微分的大小,微分的绝对值越大,代表该点损失函数
的值越大,切线越陡峭,则“迈出的步长”也应该越大;另一个是事先指定的常数项
,即学习率(Learning Rate),
越大,则“迈出的步长”的幅度即参数更新的幅度越大,学习的速度就越快。
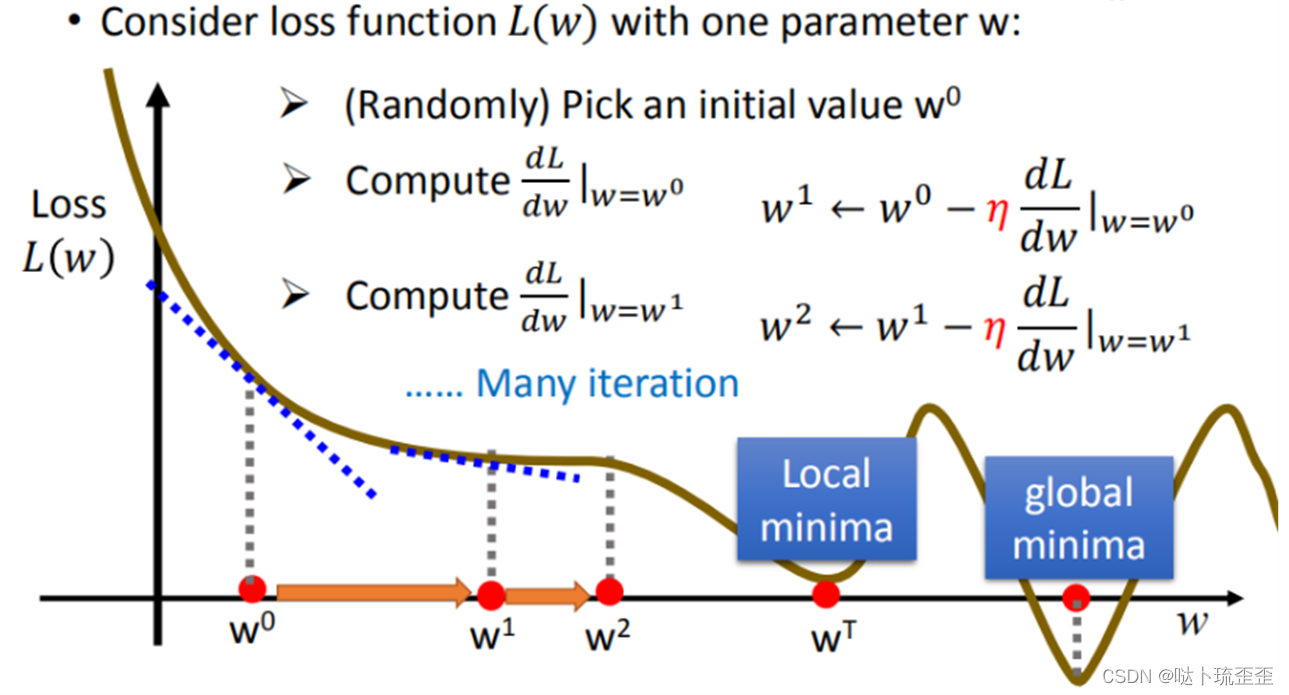
如下图所示,通过该方法找到的是当前的最小值,但可能并不是全局的最小值(取决于损失函数
是否为凸函数,后续更新说明)。
引入2个模型参数和b时, 过程与上述单个参数类似,在这里求微分需要做的是求偏微分。

梯度下降推荐最优模型的过程如下图所示
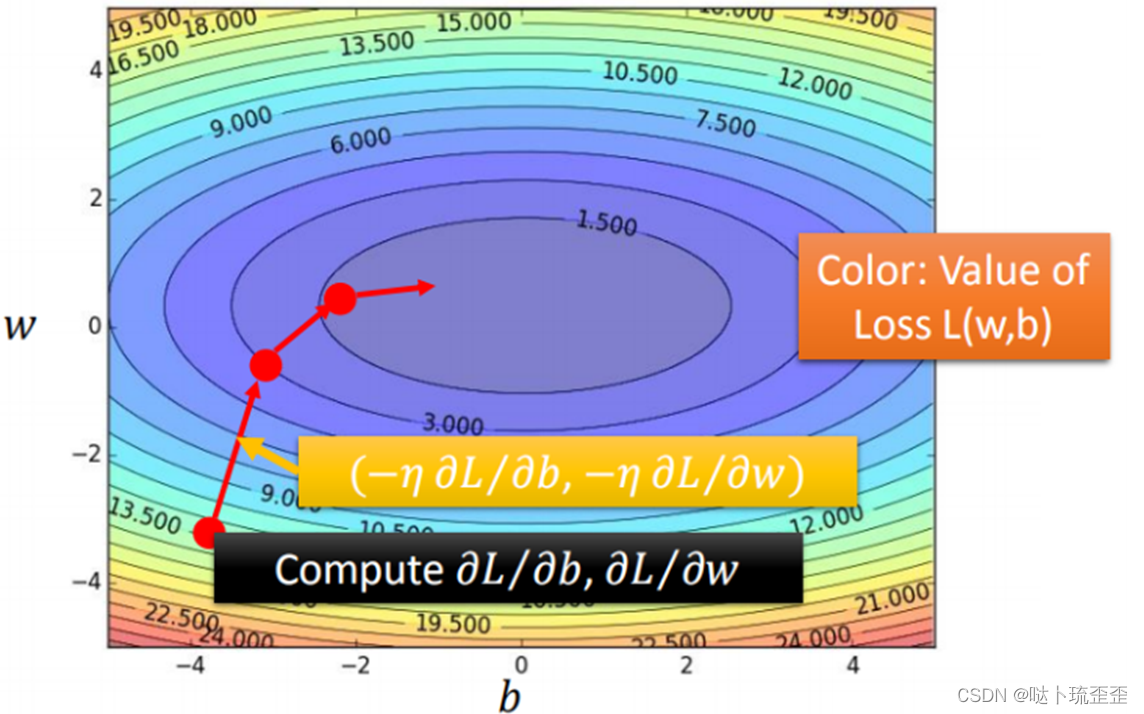
每一条等高线代表损失函数的值,越靠近中心蓝色的部分代表损失函数
越小。红色箭头代表等高线的法线方向。
梯度下降法目前存在的问题:
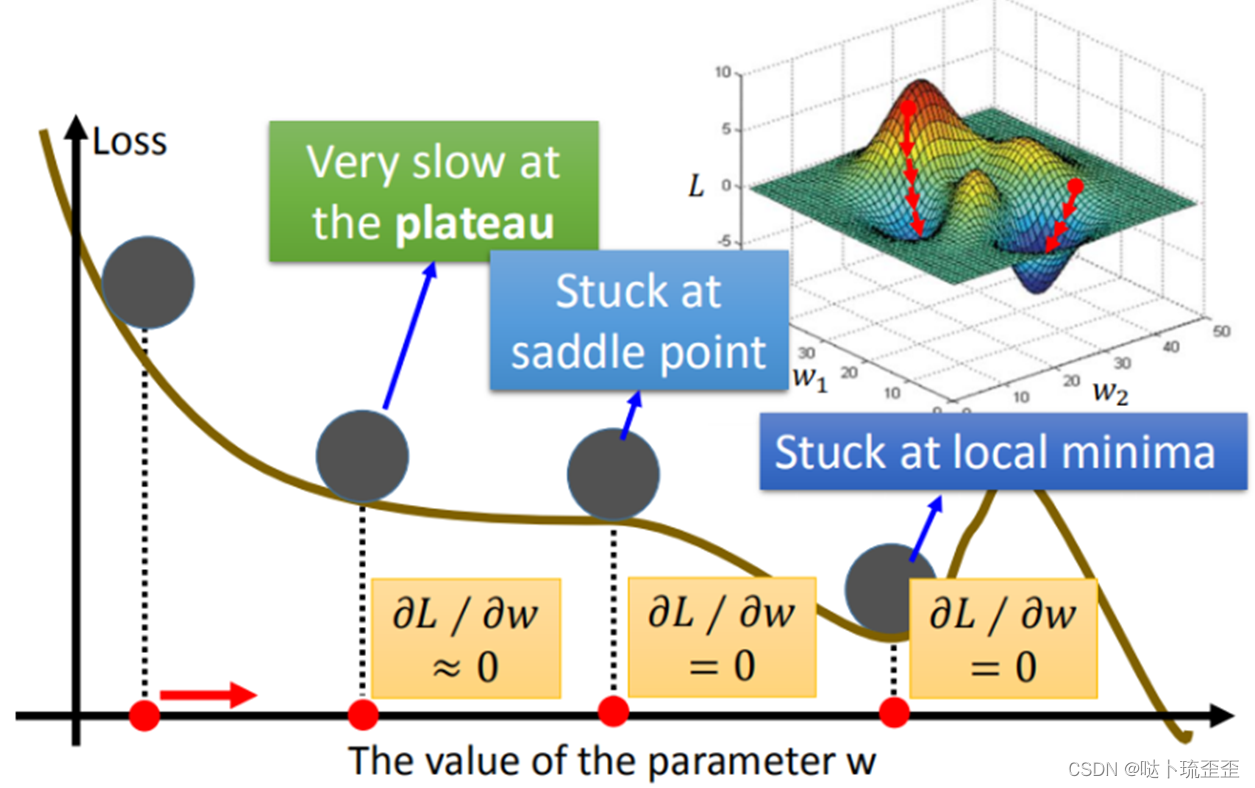
三、模型验证
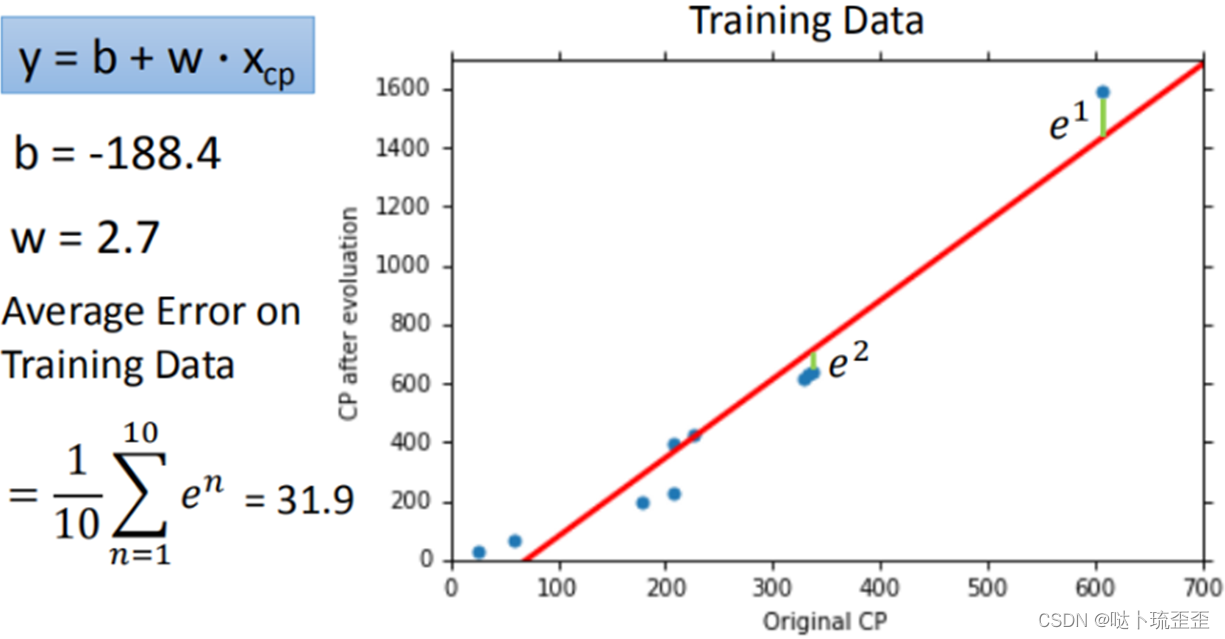
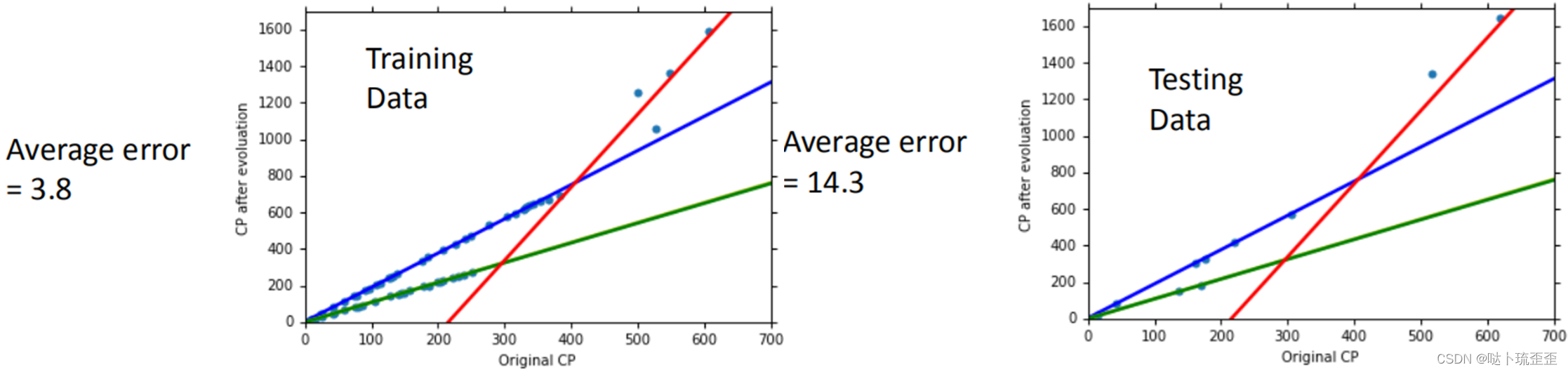
训练集的平均误差
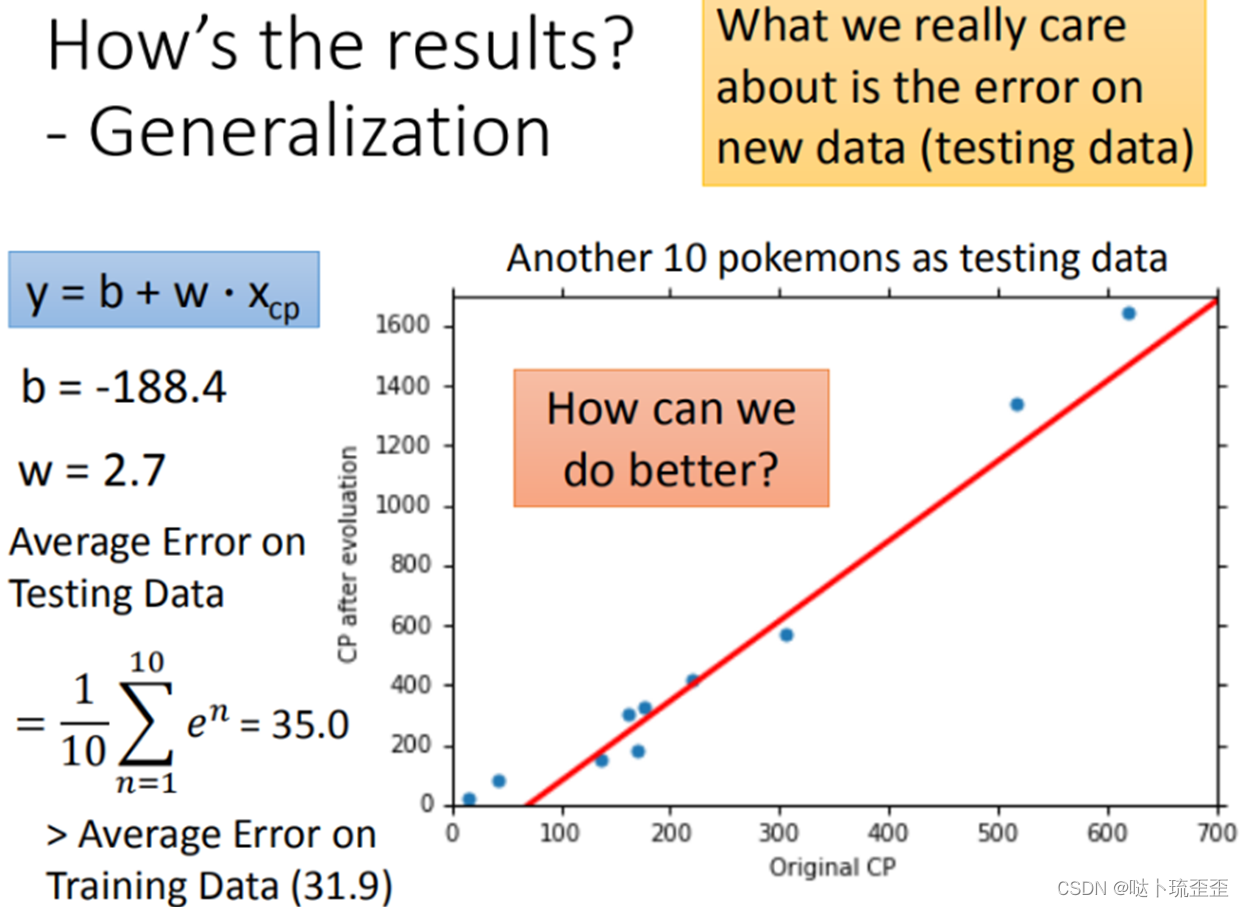
测试集的平均误差,这才是我们真正关心的
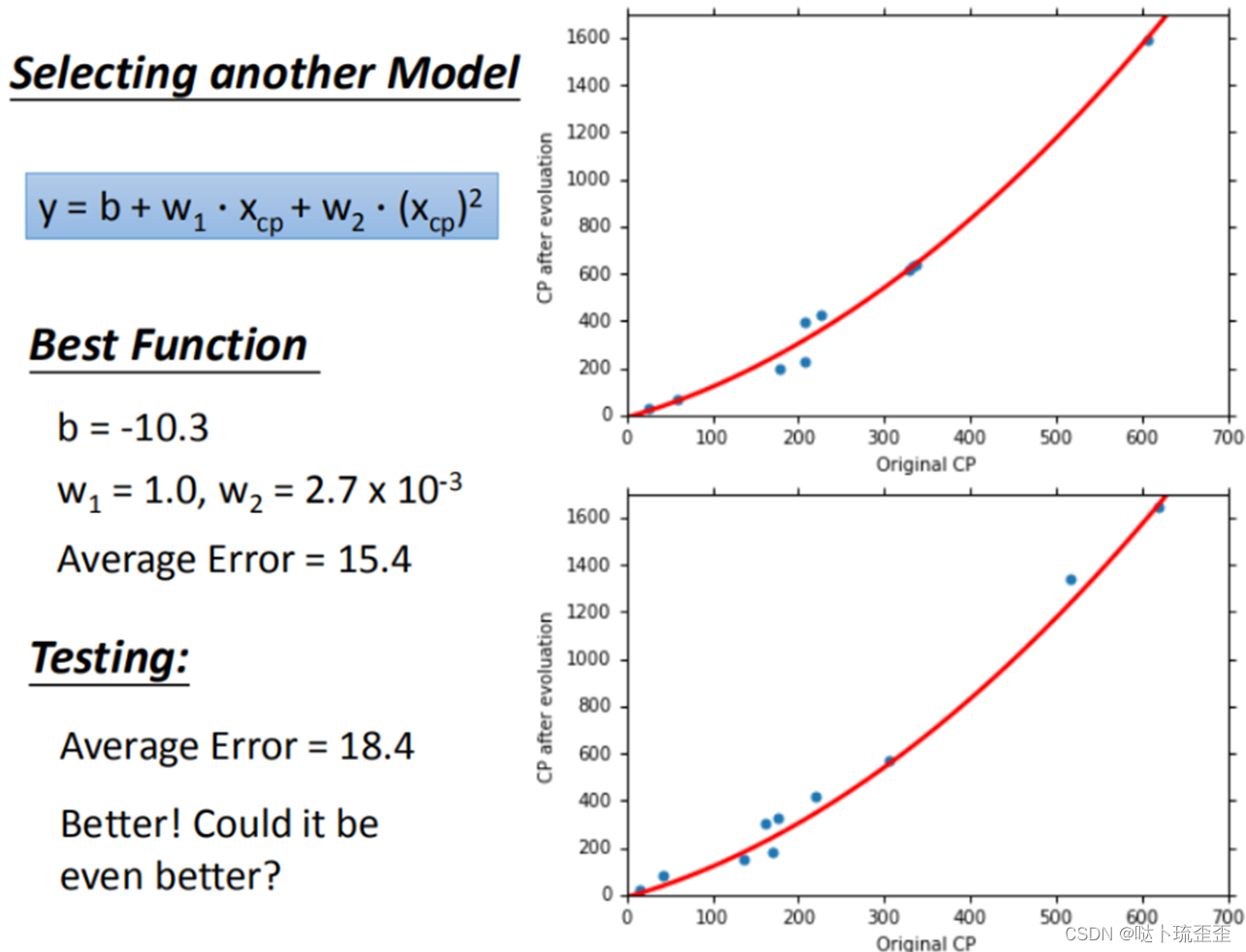
四、模型优化
选择更复杂的模型进行优化,如使用一元二次方程,此时训练集平均误差为15.4,测试集平均误差为18.4
五、过拟合(Over Fitting)
当使用更高次方的模型更进一步优化时,模型平均误差却更大了,模型效果变差。
将每个模型结果视为一个集合,5次方模型4次方模型
3次方模型,所以在4次方模型中找到的最佳模型,肯定不会比5次方模型中找到的更差

3次方以上的模型,已经出现了过拟合的现象:

六、步骤优化
将Pokemons种类通过颜色区分,会发现Pokemons种类是隐藏得比较深的特征,不同Pokemons种类影响了进化后的CP值的结果
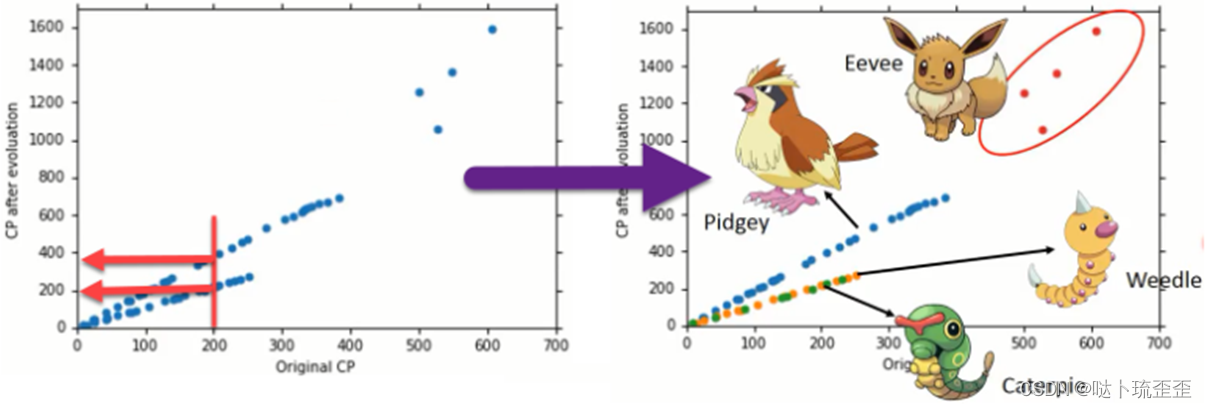
step1:合并模型
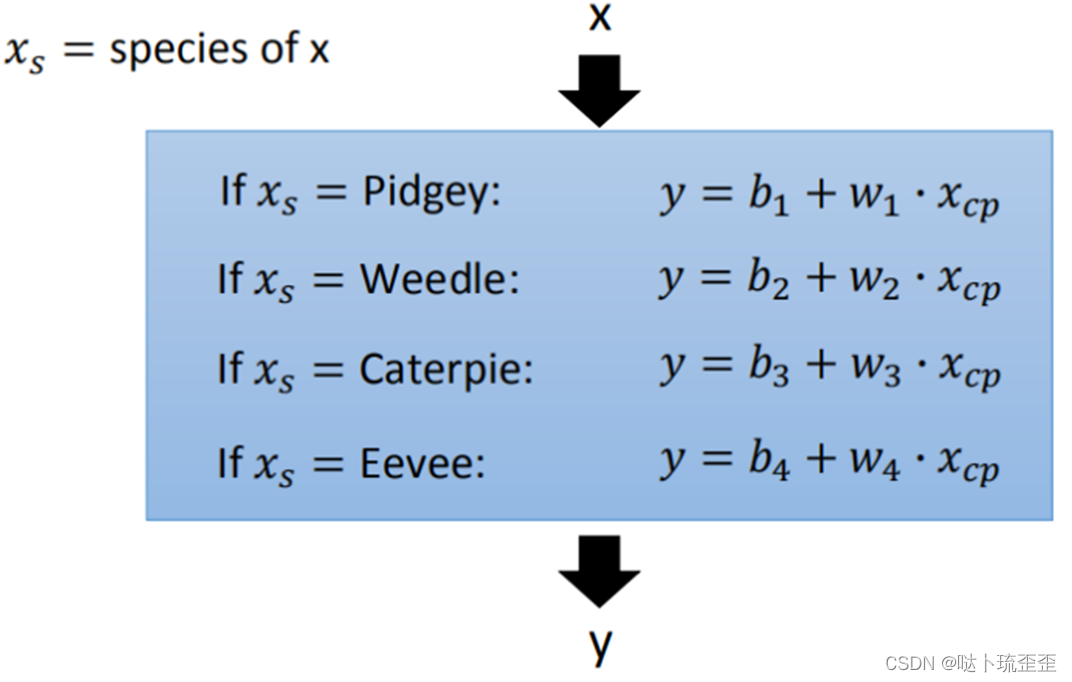
通过对Pokemons种类的判断,将 4个线性模型合并到一个线性模型中

此时训练集和测试集的平均误差如下
step2:输入更多特征
将血量(HP)、重量(Weight)、高度(Height)等特征加入模型
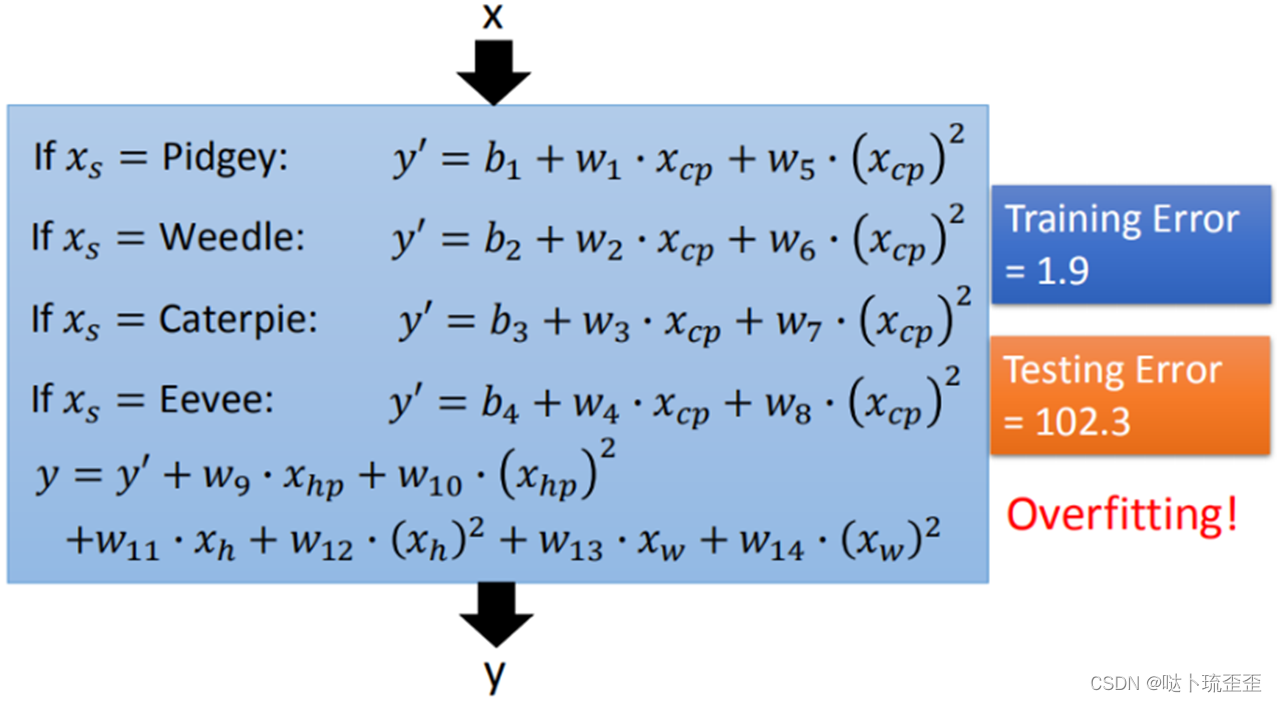
但更多特征和input,数据量没有明显增加,可能仍旧导致overfitting
step3:加入正则化项(Regularization)
越小,则function越平滑,function输出值与输入值相差不大。b的值接近0 ,对曲线的平滑越没有影响。

平滑的function对输入较不敏感,当数据中含有噪音时,一个平滑的function受到的影响较小。在很多应用场景中并不是越小模型越平滑越好,但经验值告诉我们
越小大部分情况下都比较好。
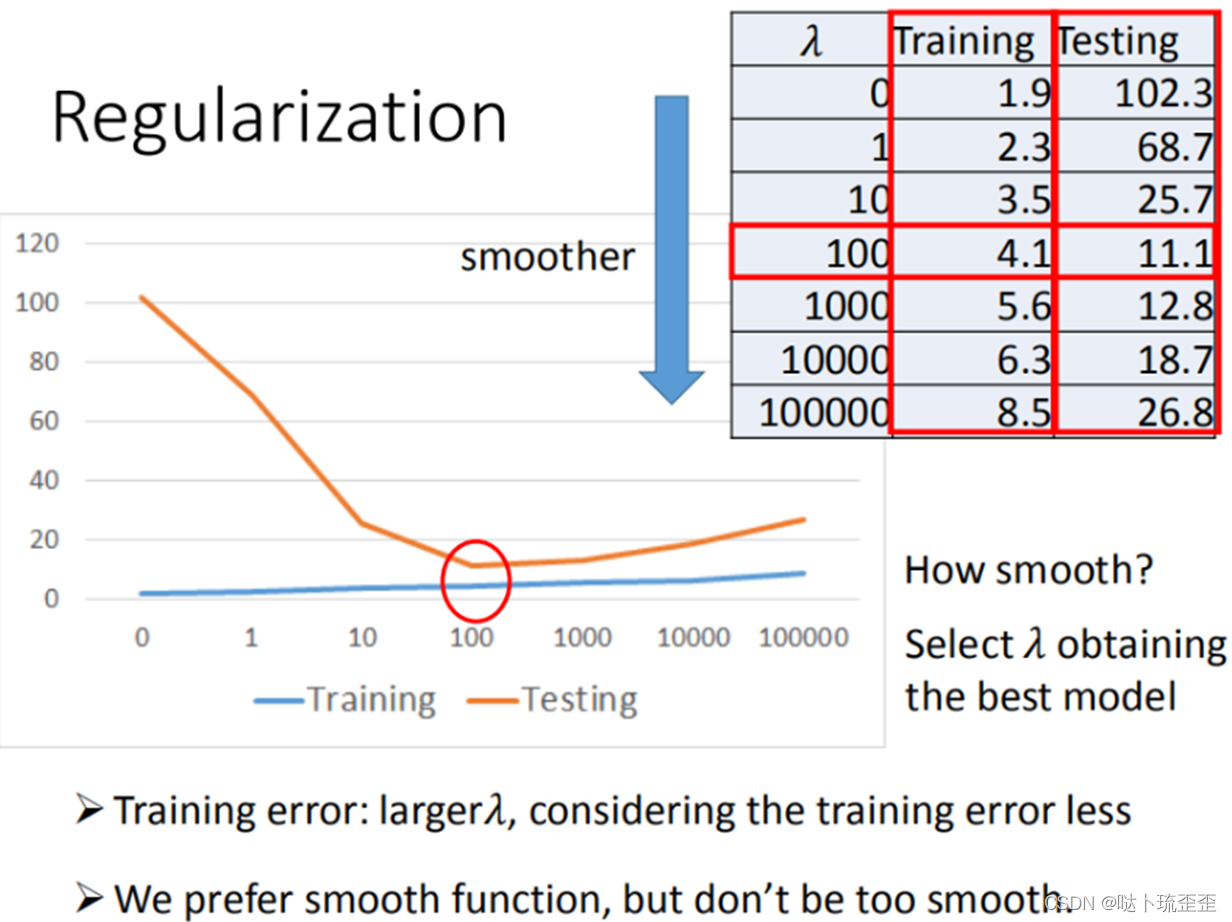
越大,代表考虑smooth越多,找到的function越平滑,越倾向于考虑
本来的数值,考虑error越少,此时在训练集上的平均误差越大,但是在测试集上的误差却可能较小。所以我们希望找到一个较为平滑的function,但是又希望
不要太大。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









