







XGBOD: Improving Supervised Outlier Detection
with Unsupervised Representation Learning
论文链接:https://www.andrew.cmu.edu/user/yuezhao2/papers/18-ijcnn-xgbod.pdf
代码:https://github.com/yzhao062/XGBOD
无监督+有监督
本文工作
补充知识
离群点检测:
【1】监督学习方法
正常样本和异常样本都有标记:
典型的处理方法是对正常值和异常值这两类分别建立预测模型,预测时进行对比,看预测样本属于哪一类?
不平衡数据处理是关键问题。因为获得标记的异常值样本通常远少于正常值样本。
【2】半监督学习方法
仅正常值样本有标记。
对正常值建立模型,然后用来预测异常值。
【3】无监督学习方法
正常值和异常值样本都没有标记。
理想地假设正常值比异常值样本多得多。一旦不满足这个假设,将会出现非常高的错误预警。
无监督离群值检测方法:
无监督方法不依赖于标签信息,可以通过各种方法学习离群值特征,如局部密度等。无监督离群点检测方法可以分为四类:
①线性模型(主成分分析)
②基于接近度,如基于密度或者距离
③依赖价值分析的统计和概率模型
④隔离森林等高维离群模型。
(在本研究中,使用各种各样的无监督离群点检测方法作为基检测器来构造一个有效的集合)
1、背景
- 离群点检测被广泛应用于异常识别方面
- 使用有监督的离群检测有困难:①数据中的离群值往往只占数据集的一小部分(数据不平衡)②标记数据不足
本文提出了一种用于离群点检测的半监督集成框架,通过应用各种无监督离群点检测函数扩充原始特征空间,由无监督的离群值检测函数生成的转换离群值(TOS)被视为数据的更丰富的表示。然后采用贪婪算法选择TOS对增广特征空间进行剪枝,以控制计算复杂度,提高预测的准确性。最后,使用监督集成方法XGBoost作为精细化特征空间的最终输出分类器。这种将原始特征与各种基本无监督离群点检测算法的输出相结合,可以更好地表示数据,类似于分类元框架叠加。
这项研究背后的动机:
- 与有监督的学习方法相比,无监督的离群值检测算法在学习极度不平衡数据集中的复杂模式方面更出色。有监督学习特征需要大量带标签数据。
- 采用叠加作为组合框架,自动学习原始特征和新生成TOS的权重。与现有的方法相比,本方法(XGBOD)不依赖于代价高昂的EasyEnsemble方法(通过构建多个平衡数据集样本处理数据不平衡问题) 极端梯度增加(XGBoost)与现有的增强算法(比如梯度增强)相比,XGBoost利用正则化项降低过拟合效果,产生更好的预测和更短的执行时间。与其他集成方法相比,XGBoost集成方法处理不平衡数据集的能力最强。因此,本研究选择XGBoost作为最终的监督分类器来替代EasyEnsemble。此外,XGBoost在拟合数据时可以自动生成特征重要度排名,这有助于实现特征剪枝方案,提高本文算法的计算效率。
2、模型框架
-
有人提出首先使用各种无监督的离群值检测方法对训练数据生成离群值得分
然后将这些无监督的离群值与原始特征结合=》新的特征空间
利用EasyEnsemble创建平衡样本解决利群问题中的数据不平衡问题
在子样本上应用L2正则化逻辑回归识别离群值 -
还有另一种半监督的离群值集合框架:
将温和的监督与无监督的离群值模型结合使用。通过访问少量的离群值标签,可以使用逻辑回归或支持向量机来学习基础检测器的权值。L1正则化是为了防止过拟合和进行特征选择,同时提出了许多检测器。
在本研究中将这两种作为基线方法,本文模型框架:
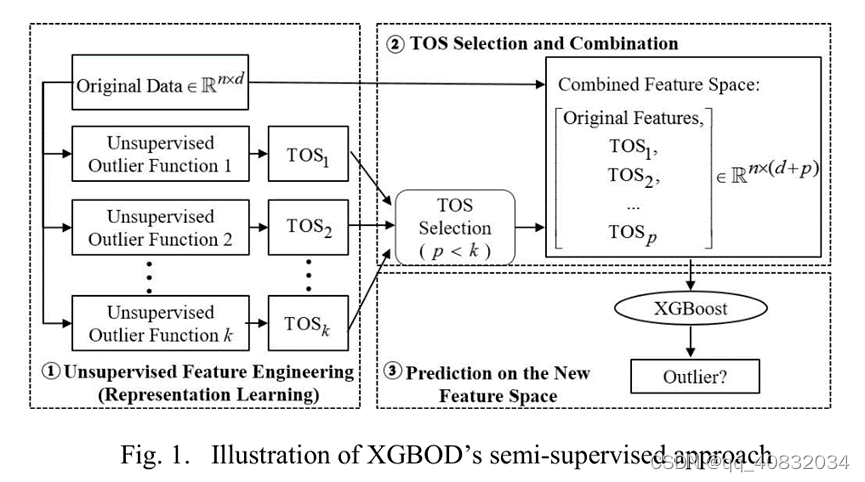
在第一阶段通过各种无监督的离群值检测方法获得转换后的离群值得分;
在第二阶段对新生成的离群值执行过程保留有用值,结合原始特征成为新的特征空间;
在第三个阶段训练XGBoost分类器,输出作为预测结果。
- 第一阶段:从原始数据中提取离群值评分TOS
设原始特征空间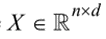 表示n个具有d个特征的数据点的集合,由于离群值检测是一种二分类,
表示n个具有d个特征的数据点的集合,由于离群值检测是一种二分类,
向量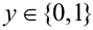 分配离群值标签,y是1表示离群值,0表示正常点,设L为X的标记观察值集合:
分配离群值标签,y是1表示离群值,0表示正常点,设L为X的标记观察值集合:
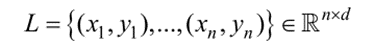
离群值评分函数可以是任何无监督的离群值检测方法。将输出的TOS作为新的特征来扩充原有的特征空间。结合k个离群值评分函数构造一个变换函数矩阵,生成原始特征空间X上的k个基分函数的离群值得分矩阵
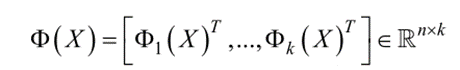
虽然任意无监督的离群值检测方法都可以作为离群值评分函数,但是异构的效果更好,可以减少重复学习和不必要的高计算。此外,离群值评分函数也应该尽可能准确,否则会降低预测的准确性。所以需要在多样性和准确性之间获得平衡。
- 第二阶段:TOS选择
将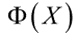 与原始特征X结合,称为联合特征空间,因为不是所有的TOS都会对预测做出贡献,减少数量也会加快训练速度,第二阶段只从生成的k个TOS中选择p个。
与原始特征X结合,称为联合特征空间,因为不是所有的TOS都会对预测做出贡献,减少数量也会加快训练速度,第二阶段只从生成的k个TOS中选择p个。
定义了三种选择方法:
①随机选p个
②选取精确度高的TOS的方法,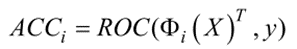
③

- 第三阶段:使用XGBoost进行预测
XGBoost可以平衡数据
XGBoost可以执行后剪枝过程,在后续过程中对TOS减枝选取更好的TOS
XGBoost中的集成和正则化机制可以在不引入很大偏差的情况下实现低方差,尽量减少偏差方差。
3、实验评估
离群值评分函数包括很多广泛的无监督离群点检测算法,如:KNN,K-mean、Avg-KNN、One-Class SVM等,都是无监督的。
设置两个实验:
-
实验一重在比较分类方法,要么使用全部的TOS,要么不用TOS;

结果发现,
使用无监督利群检测组合TOS的评分更高
简单的模型和EasyEnsemble的结合可以被具有强正则化的集成算法所取代,比如XGBoost -
实验二分析了选择不同TOS个数、以及不同算法的结果。
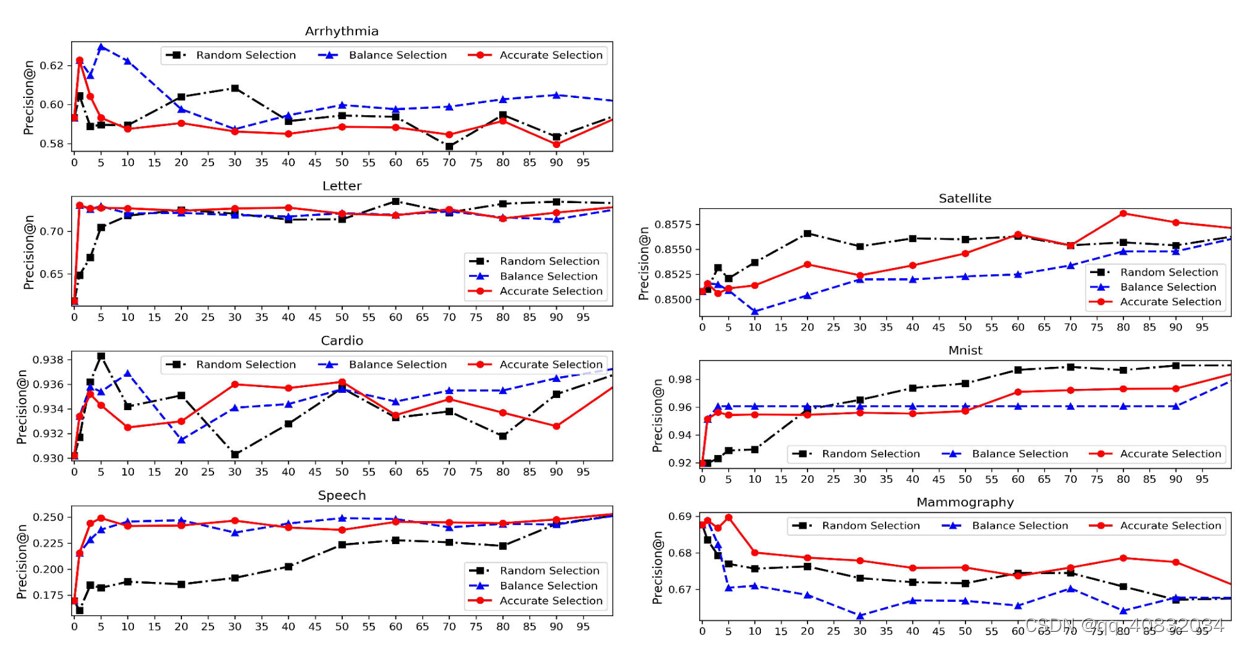
发现使用TOS的子集通常比使用所有TOS产生更好的结果
4、本文不足
利用各种工具降低偏差和方差,考虑采用XGBOD来提高各阶段的泛化能力,但是因为不可预测的病理数据和检测函数的不良性,XGBOD的性能可能不可预测;
在未来的研究中可以引入更多的TOS选择方法,比如对XGBoost的特征重要性进行post-pruning。
可以考虑TOS合并而不是选择



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









