import pandas as pd
import numpy as np
df = pd. read_csv( './table_missing.csv' )
df. head( )
School Class ID Gender Address Height Weight Math Physics 0 S_1 C_1 NaN M street_1 173 NaN 34.0 A+ 1 S_1 C_1 NaN F street_2 192 NaN 32.5 B+ 2 S_1 C_1 1103.0 M street_2 186 NaN 87.2 B+ 3 S_1 NaN NaN F street_2 167 81.0 80.4 NaN 4 S_1 C_1 1105.0 NaN street_4 159 64.0 84.8 A-
df[ 'Physics' ] . isna( ) . head( )
0 False
1 False
2 False
3 True
4 False
Name: Physics, dtype: bool
df[ 'Physics' ] . notna( ) . head( )
0 True
1 True
2 True
3 False
4 True
Name: Physics, dtype: bool
df. isna( ) . head( )
School Class ID Gender Address Height Weight Math Physics 0 False False True False False False True False False 1 False False True False False False True False False 2 False False False False False False True False False 3 False True True False False False False False True 4 False False False True False False False False False
df. isna( ) . sum ( )
School 0
Class 4
ID 6
Gender 7
Address 0
Height 0
Weight 13
Math 5
Physics 4
dtype: int64
df. info( )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 35 entries, 0 to 34
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 School 35 non-null object
1 Class 31 non-null object
2 ID 29 non-null float64
3 Gender 28 non-null object
4 Address 35 non-null object
5 Height 35 non-null int64
6 Weight 22 non-null float64
7 Math 30 non-null float64
8 Physics 31 non-null object
dtypes: float64(3), int64(1), object(5)
memory usage: 2.6+ KB
df[ df[ 'Physics' ] . isna( ) ]
School Class ID Gender Address Height Weight Math Physics 3 S_1 NaN NaN F street_2 167 81.0 80.4 NaN 8 S_1 C_2 1204.0 F street_5 162 63.0 33.8 NaN 13 S_1 C_3 1304.0 NaN street_2 195 70.0 85.2 NaN 22 S_2 C_2 2203.0 M street_4 155 91.0 73.8 NaN
df[ df. notna( ) . all ( 1 ) ]
School Class ID Gender Address Height Weight Math Physics 5 S_1 C_2 1201.0 M street_5 159 68.0 97.0 A- 6 S_1 C_2 1202.0 F street_4 176 94.0 63.5 B- 12 S_1 C_3 1303.0 M street_7 188 82.0 49.7 B 17 S_2 C_1 2103.0 M street_4 157 61.0 52.5 B- 21 S_2 C_2 2202.0 F street_7 194 77.0 68.5 B+ 25 S_2 C_3 2301.0 F street_4 157 78.0 72.3 B+ 27 S_2 C_3 2303.0 F street_7 190 99.0 65.9 C 28 S_2 C_3 2304.0 F street_6 164 81.0 95.5 A- 29 S_2 C_3 2305.0 M street_4 187 73.0 48.9 B
np. nan == np. nan
False
np. nan == 0
False
np. nan == None
False
df. equals( df)
True
type ( np. nan)
float
pd. Series( [ 1 , 2 , 3 ] ) . dtype
dtype('int64')
pd. Series( [ 1 , np. nan, 3 ] ) . dtype
dtype('float64')
pd. Series( [ 1 , np. nan, 3 ] , dtype= 'bool' )
0 True
1 True
2 True
dtype: bool
s = pd. Series( [ True , False ] , dtype= 'bool' )
s[ 1 ] = np. nan
s
0 1.0
1 NaN
dtype: float64
df[ 'ID' ] . dtype
dtype('float64')
df[ 'Math' ] . dtype
dtype('float64')
df[ 'Class' ] . dtype
dtype('O')
None == None
True
pd. Series( [ None ] , dtype= 'bool' )
0 False
dtype: bool
s = pd. Series( [ True , False ] , dtype= 'bool' )
s[ 0 ] = None
s
0 False
1 False
dtype: bool
s = pd. Series( [ 1 , 0 ] , dtype= 'bool' )
s[ 0 ] = None
s
0 False
1 False
dtype: bool
type ( pd. Series( [ 1 , None ] ) [ 1 ] )
numpy.float64
type ( pd. Series( [ 1 , None ] , dtype= 'O' ) [ 1 ] )
NoneType
pd. Series( [ None ] ) . equals( pd. Series( [ np. nan] ) )
False
s_time = pd. Series( [ pd. Timestamp( '20120101' ) ] * 5 )
s_time
0 2012-01-01
1 2012-01-01
2 2012-01-01
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
s_time[ 2 ] = None
s_time
0 2012-01-01
1 2012-01-01
2 NaT
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
s_time[ 2 ] = np. nan
s_time
0 2012-01-01
1 2012-01-01
2 NaT
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
s_time[ 2 ] = pd. NaT
s_time
0 2012-01-01
1 2012-01-01
2 NaT
3 2012-01-01
4 2012-01-01
dtype: datetime64[ns]
type ( s_time[ 2 ] )
pandas._libs.tslibs.nattype.NaTType
s_time[ 2 ] == s_time[ 2 ]
False
s_time. equals( s_time)
True
s = pd. Series( [ True , False ] , dtype= 'bool' )
s[ 1 ] = pd. NaT
s
0 True
1 True
dtype: bool
s_original = pd. Series( [ 1 , 2 ] , dtype= "int64" )
s_original
0 1
1 2
dtype: int64
s_new = pd. Series( [ 1 , 2 ] , dtype= "Int64" )
s_new
0 1
1 2
dtype: Int64
s_original[ 1 ] = np. nan
s_original
0 1.0
1 NaN
dtype: float64
s_new[ 1 ] = np. nan
s_new
0 1
1 <NA>
dtype: Int64
s_new[ 1 ] = None
s_new
0 1
1 <NA>
dtype: Int64
s_new[ 1 ] = pd. NaT
s_new
0 1
1 <NA>
dtype: Int64
s_original = pd. Series( [ 1 , 0 ] , dtype= "bool" )
s_original
0 True
1 False
dtype: bool
s_new = pd. Series( [ 0 , 1 ] , dtype= "boolean" )
s_new
0 False
1 True
dtype: boolean
s_original[ 0 ] = np. nan
s_original
0 NaN
1 0.0
dtype: float64
s_original = pd. Series( [ 1 , 0 ] , dtype= "bool" )
s_original[ 0 ] = None
s_original
0 False
1 False
dtype: bool
s_new[ 0 ] = np. nan
s_new
0 <NA>
1 True
dtype: boolean
s_new[ 0 ] = None
s_new
0 <NA>
1 True
dtype: boolean
s_new[ 0 ] = pd. NaT
s_new
0 <NA>
1 True
dtype: boolean
bug ,现已经修复s = pd. Series( [ 'dog' , 'cat' ] )
s[ s_new]
1 cat
dtype: object
s = pd. Series( [ 'dog' , 'cat' ] , dtype= 'string' )
s
0 dog
1 cat
dtype: string
s[ 0 ] = np. nan
s
0 <NA>
1 cat
dtype: string
s[ 0 ] = None
s
0 <NA>
1 cat
dtype: string
s[ 0 ] = pd. NaT
s
0 <NA>
1 cat
dtype: string
s = pd. Series( [ "a" , None , "b" ] , dtype= "string" )
s. str . count( 'a' )
0 1
1 <NA>
2 0
dtype: Int64
s2 = pd. Series( [ "a" , None , "b" ] , dtype= "object" )
s2. str . count( "a" )
0 1.0
1 NaN
2 0.0
dtype: float64
s. str . isdigit( )
0 False
1 <NA>
2 False
dtype: boolean
s2. str . isdigit( )
0 False
1 None
2 False
dtype: object
True | pd. NA
True
pd. NA | True
True
False | pd. NA
<NA>
False & pd. NA
False
True & pd. NA
<NA>
pd. NA ** 0
1
1 ** pd. NA
1
pd. NA + 1
<NA>
"a" * pd. NA
<NA>
pd. NA == pd. NA
<NA>
pd. NA < 2.5
<NA>
np. log( pd. NA)
<NA>
np. add( pd. NA, 1 )
<NA>
pd. read_csv( 'data/table_missing.csv' ) . dtypes
School object
Class object
ID float64
Gender object
Address object
Height int64
Weight float64
Math float64
Physics object
dtype: object
pd. read_csv( 'data/table_missing.csv' ) . convert_dtypes( ) . dtypes
School string
Class string
ID Int64
Gender string
Address string
Height Int64
Weight Int64
Math float64
Physics string
dtype: object
s = pd. Series( [ 2 , 3 , np. nan, 4 ] )
s. sum ( )
9.0
s. prod( )
24.0
s. cumsum( )
0 2.0
1 5.0
2 NaN
3 9.0
dtype: float64
s. cumprod( )
0 2.0
1 6.0
2 NaN
3 24.0
dtype: float64
s. pct_change( )
0 NaN
1 0.500000
2 0.000000
3 0.333333
dtype: float64
df_g = pd. DataFrame( { 'one' : [ 'A' , 'B' , 'C' , 'D' , np. nan] , 'two' : np. random. randn( 5 ) } )
df_g
one two 0 A -1.126645 1 B 0.924595 2 C -2.076309 3 D -0.312150 4 NaN 0.961543
df_g. groupby( 'one' ) . groups
{'A': Int64Index([0], dtype='int64'),
'B': Int64Index([1], dtype='int64'),
'C': Int64Index([2], dtype='int64'),
'D': Int64Index([3], dtype='int64')}
df[ 'Physics' ] . fillna( 'missing' ) . head( )
0 A+
1 B+
2 B+
3 missing
4 A-
Name: Physics, dtype: object
df[ 'Physics' ] . fillna( method= 'ffill' ) . head( )
0 A+
1 B+
2 B+
3 B+
4 A-
Name: Physics, dtype: object
df[ 'Physics' ] . fillna( method= 'backfill' ) . head( )
0 A+
1 B+
2 B+
3 A-
4 A-
Name: Physics, dtype: object
df_f = pd. DataFrame( { 'A' : [ 1 , 3 , np. nan] , 'B' : [ 2 , 4 , np. nan] , 'C' : [ 3 , 5 , np. nan] } )
df_f. fillna( df_f. mean( ) )
A B C 0 1.0 2.0 3.0 1 3.0 4.0 5.0 2 2.0 3.0 4.0
df_f. fillna( df_f. mean( ) [ [ 'A' , 'B' ] ] )
A B C 0 1.0 2.0 3.0 1 3.0 4.0 5.0 2 2.0 3.0 NaN
df_d = pd. DataFrame( { 'A' : [ np. nan, np. nan, np. nan] , 'B' : [ np. nan, 3 , 2 ] , 'C' : [ 3 , 2 , 1 ] } )
df_d
A B C 0 NaN NaN 3 1 NaN 3.0 2 2 NaN 2.0 1
df_d. dropna( axis= 0 )
df_d. dropna( axis= 1 )
df_d. dropna( axis= 1 , how= 'all' )
df_d. dropna( axis= 0 , subset= [ 'B' , 'C' ] )
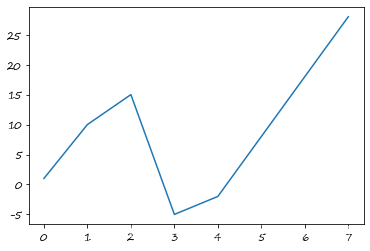
s = pd. Series( [ 1 , 10 , 15 , - 5 , - 2 , np. nan, np. nan, 28 ] )
s
0 1.0
1 10.0
2 15.0
3 -5.0
4 -2.0
5 NaN
6 NaN
7 28.0
dtype: float64
s. interpolate( )
0 1.0
1 10.0
2 15.0
3 -5.0
4 -2.0
5 8.0
6 18.0
7 28.0
dtype: float64
s. interpolate( ) . plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7df20af50>
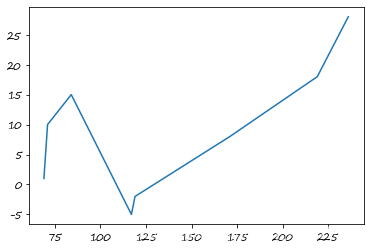
s. index = np. sort( np. random. randint( 50 , 300 , 8 ) )
s. interpolate( )
69 1.0
71 10.0
84 15.0
117 -5.0
119 -2.0
171 8.0
219 18.0
236 28.0
dtype: float64
s. interpolate( ) . plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dfc69890>
s. interpolate( method= 'index' ) . plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dca0c4d0>
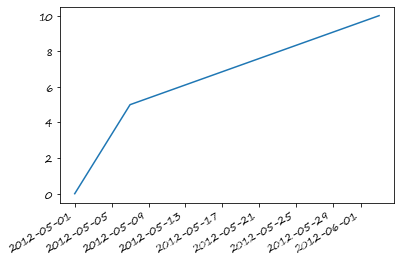
s_t = pd. Series( [ 0 , np. nan, 10 ]
, index= [ pd. Timestamp( '2012-05-01' ) , pd. Timestamp( '2012-05-07' ) , pd. Timestamp( '2012-06-03' ) ] )
s_t
2012-05-01 0.0
2012-05-07 NaN
2012-06-03 10.0
dtype: float64
s_t. interpolate( ) . plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc964850>
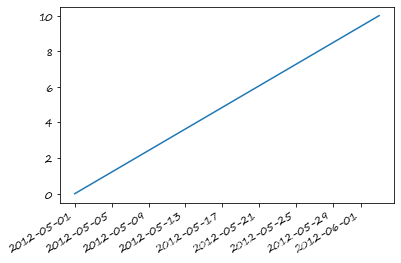
s_t. interpolate( method= 'time' ) . plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc8eda10>
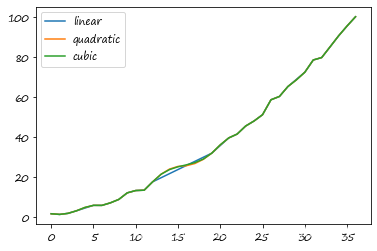
这里 ser = pd. Series( np. arange( 1 , 10.1 , .25 ) ** 2 + np. random. randn( 37 ) )
missing = np. array( [ 4 , 13 , 14 , 15 , 16 , 17 , 18 , 20 , 29 ] )
ser[ missing] = np. nan
methods = [ 'linear' , 'quadratic' , 'cubic' ]
df = pd. DataFrame( { m: ser. interpolate( method= m) for m in methods} )
df. plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x7fe7dc86f810>
s = pd. Series( [ 1 , np. nan, np. nan, np. nan, 5 ] )
s. interpolate( limit= 2 )
0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
dtype: float64
s = pd. Series( [ np. nan, np. nan, 1 , np. nan, np. nan, np. nan, 5 , np. nan, np. nan, ] )
s. interpolate( limit_direction= 'backward' )
0 1.0
1 1.0
2 1.0
3 2.0
4 3.0
5 4.0
6 5.0
7 NaN
8 NaN
dtype: float64
s = pd. Series( [ np. nan, np. nan, 1 , np. nan, np. nan, np. nan, 5 , np. nan, np. nan, ] )
s. interpolate( limit_area= 'inside' )
0 NaN
1 NaN
2 1.0
3 2.0
4 3.0
5 4.0
6 5.0
7 NaN
8 NaN
dtype: float64
s = pd. Series( [ np. nan, np. nan, 1 , np. nan, np. nan, np. nan, 5 , np. nan, np. nan, ] )
s. interpolate( limit_area= 'outside' )
0 NaN
1 NaN
2 1.0
3 NaN
4 NaN
5 NaN
6 5.0
7 5.0
8 5.0
dtype: float64
问题一:data=data.drop(data.columns[data.isna().sum()/data.shape[0]>0.25],axis=1)
data= pd. read_csv( './missing_data_one.csv' ) . head( )
data[ data[ 'C' ] . isna( ) ]
min_b= data[ 'B' ] . min ( )
for i in range ( data. shape[ 0 ] ) :
if np. random. rand( ) <= ( data. loc[ i] [ 'B' ] * 0.25 / min_b) :
data. loc[ i, 'A' ] = np. nan
data
A B C 0 not_NaN 0.922 4.0 1 not_NaN 0.700 NaN 2 NaN 0.503 8.0 3 not_NaN 0.938 4.0 4 NaN 0.952 10.0
data= pd. read_csv( 'missing_data_two.csv' )
print ( data. isna( ) . sum ( ) / data. shape[ 0 ] )
data[ data. iloc[ : , - 3 : ] . isna( ) . sum ( axis= 1 ) >= 2 ]
编号 0.000000
地区 0.000000
身高 0.000000
体重 0.222222
年龄 0.250000
工资 0.222222
dtype: float64
编号 地区 身高 体重 年龄 工资 2 3 C 169.09 62.18 NaN NaN 11 12 A 202.56 92.30 NaN NaN 12 13 C 177.37 NaN 79.0 NaN 14 15 C 199.11 89.20 NaN NaN 26 27 B 158.28 NaN 51.0 NaN 32 33 C 181.01 NaN NaN 13021.0 33 34 A 196.67 87.00 NaN NaN
data_A= data. loc[ data[ '地区' ] == 'A' ]
data_A. loc[ 0 , : ] , data_A. loc[ 3 , : ] = data_A. loc[ 3 , : ] , data_A. loc[ 0 , : ]
data_A. index= data_A[ '身高' ]
% matplotlib inline
data_A
H:\aanaconda3\lib\site-packages\pandas\core\indexing.py:966: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
编号 地区 身高 体重 年龄 工资 身高 166.61 4 A 166.61 59.95 77.0 5434.0 157.50 1 A 157.50 NaN 47.0 15905.0 187.13 6 A 187.13 78.42 55.0 13959.0 183.80 8 A 183.80 75.42 48.0 19779.0 202.56 12 A 202.56 92.30 NaN NaN 165.68 16 A 165.68 NaN 46.0 13683.0 172.83 19 A 172.83 65.55 23.0 13768.0 154.63 22 A 154.63 49.17 35.0 14559.0 165.55 24 A 165.55 NaN 66.0 19890.0 164.43 26 A 164.43 57.99 34.0 19899.0 183.73 30 A 183.73 75.36 58.0 8270.0 196.67 34 A 196.67 87.00 NaN NaN
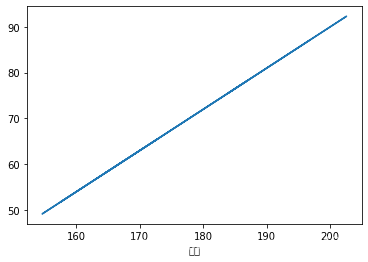
data_A[ '体重' ] . interpolate( method= 'index' ) . plot( )
data_A[ '体重' ] . interpolate( method= 'index' , inplace= True )
H:\aanaconda3\lib\site-packages\pandas\core\generic.py:7023: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._update_inplace(new_data)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 36523 missing from current font.
font.set_text(s, 0.0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 39640 missing from current font.
font.set_text(s, 0.0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:183: RuntimeWarning: Glyph 36523 missing from current font.
font.set_text(s, 0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:183: RuntimeWarning: Glyph 39640 missing from current font.
font.set_text(s, 0, flags=flags)
data_A
编号 地区 身高 体重 年龄 工资 身高 166.61 4 A 166.61 59.950000 77.0 5434.0 157.50 1 A 157.50 51.753000 47.0 15905.0 187.13 6 A 187.13 78.420000 55.0 13959.0 183.80 8 A 183.80 75.420000 48.0 19779.0 202.56 12 A 202.56 92.300000 NaN NaN 165.68 16 A 165.68 59.113853 46.0 13683.0 172.83 19 A 172.83 65.550000 23.0 13768.0 154.63 22 A 154.63 49.170000 35.0 14559.0 165.55 24 A 165.55 58.996972 66.0 19890.0 164.43 26 A 164.43 57.990000 34.0 19899.0 183.73 30 A 183.73 75.360000 58.0 8270.0 196.67 34 A 196.67 87.000000 NaN NaN
data_B= data. loc[ data[ '地区' ] == 'B' ]
data_B. index= data_B[ '身高' ]
data_B
编号 地区 身高 体重 年龄 工资 身高 202.00 2 B 202.00 91.80 25.0 NaN 185.19 5 B 185.19 NaN 62.0 4242.0 179.67 9 B 179.67 71.70 65.0 8608.0 163.41 11 B 163.41 57.07 NaN 6495.0 175.99 14 B 175.99 68.39 NaN 13130.0 166.48 17 B 166.48 59.83 31.0 17673.0 156.99 20 B 156.99 51.29 62.0 3054.0 157.87 23 B 157.87 52.08 67.0 7398.0 158.28 27 B 158.28 NaN 51.0 NaN 162.12 29 B 162.12 55.91 NaN 13362.0 167.28 32 B 167.28 60.55 64.0 18317.0 170.12 35 B 170.12 63.11 77.0 7398.0
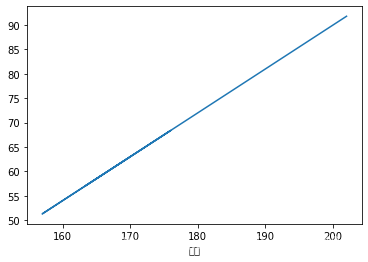
data_B[ '体重' ] . interpolate( method= 'index' ) . plot( )
data_B[ '体重' ] . interpolate( method= 'index' , inplace= True )
H:\aanaconda3\lib\site-packages\pandas\core\generic.py:7023: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._update_inplace(new_data)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 36523 missing from current font.
font.set_text(s, 0.0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 39640 missing from current font.
font.set_text(s, 0.0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:183: RuntimeWarning: Glyph 36523 missing from current font.
font.set_text(s, 0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:183: RuntimeWarning: Glyph 39640 missing from current font.
font.set_text(s, 0, flags=flags)
data_B
编号 地区 身高 体重 年龄 工资 身高 202.00 2 B 202.00 91.800000 25.0 NaN 185.19 5 B 185.19 76.668742 62.0 4242.0 179.67 9 B 179.67 71.700000 65.0 8608.0 163.41 11 B 163.41 57.070000 NaN 6495.0 175.99 14 B 175.99 68.390000 NaN 13130.0 166.48 17 B 166.48 59.830000 31.0 17673.0 156.99 20 B 156.99 51.290000 62.0 3054.0 157.87 23 B 157.87 52.080000 67.0 7398.0 158.28 27 B 158.28 52.449482 51.0 NaN 162.12 29 B 162.12 55.910000 NaN 13362.0 167.28 32 B 167.28 60.550000 64.0 18317.0 170.12 35 B 170.12 63.110000 77.0 7398.0
data_C= data. loc[ data[ '地区' ] == 'C' ]
data_C. index= data_C[ '身高' ]
data_C
编号 地区 身高 体重 年龄 工资 身高 169.09 3 C 169.09 62.18 NaN NaN 163.81 7 C 163.81 57.43 43.0 6533.0 186.08 10 C 186.08 77.47 65.0 12433.0 177.37 13 C 177.37 NaN 79.0 NaN 199.11 15 C 199.11 89.20 NaN NaN 191.62 18 C 191.62 82.46 NaN 12447.0 200.22 21 C 200.22 90.20 41.0 NaN 181.78 25 C 181.78 73.60 63.0 11383.0 172.39 28 C 172.39 65.15 43.0 10362.0 181.19 31 C 181.19 NaN 41.0 12616.0 181.01 33 C 181.01 NaN NaN 13021.0 180.47 36 C 180.47 72.42 78.0 9554.0
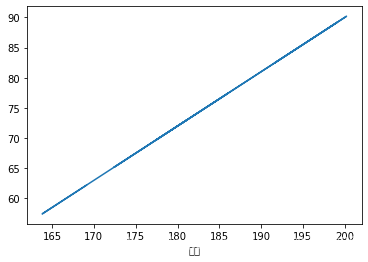
data_C[ '体重' ] . interpolate( method= 'index' ) . plot( )
data_C[ '体重' ] . interpolate( method= 'index' , inplace= True )
H:\aanaconda3\lib\site-packages\pandas\core\generic.py:7023: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._update_inplace(new_data)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 36523 missing from current font.
font.set_text(s, 0.0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:214: RuntimeWarning: Glyph 39640 missing from current font.
font.set_text(s, 0.0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:183: RuntimeWarning: Glyph 36523 missing from current font.
font.set_text(s, 0, flags=flags)
H:\aanaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:183: RuntimeWarning: Glyph 39640 missing from current font.
font.set_text(s, 0, flags=flags)
data_C
编号 地区 身高 体重 年龄 工资 身高 169.09 3 C 169.09 62.180000 NaN NaN 163.81 7 C 163.81 57.430000 43.0 6533.0 186.08 10 C 186.08 77.470000 65.0 12433.0 177.37 13 C 177.37 69.630767 79.0 NaN 199.11 15 C 199.11 89.200000 NaN NaN 191.62 18 C 191.62 82.460000 NaN 12447.0 200.22 21 C 200.22 90.200000 41.0 NaN 181.78 25 C 181.78 73.600000 63.0 11383.0 172.39 28 C 172.39 65.150000 43.0 10362.0 181.19 31 C 181.19 73.068550 41.0 12616.0 181.01 33 C 181.01 72.906412 NaN 13021.0 180.47 36 C 180.47 72.420000 78.0 9554.0




 本文深入探讨Pandas 1.0中缺失数据的处理,包括了解缺失信息、三种缺失符号(np.nan, None, NaT)及其特性、Nullable类型与NA符号的引入,以及填充、剔除、插值等方法。还介绍了如何通过convert_dtypes方法转换数据类型,以及在缺失数据的运算与分组中的处理策略。"
131657543,19419959,模拟退火算法解决流水车间调度问题,"['算法', '机器学习', '优化', '模拟退火']
本文深入探讨Pandas 1.0中缺失数据的处理,包括了解缺失信息、三种缺失符号(np.nan, None, NaT)及其特性、Nullable类型与NA符号的引入,以及填充、剔除、插值等方法。还介绍了如何通过convert_dtypes方法转换数据类型,以及在缺失数据的运算与分组中的处理策略。"
131657543,19419959,模拟退火算法解决流水车间调度问题,"['算法', '机器学习', '优化', '模拟退火']


















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









