







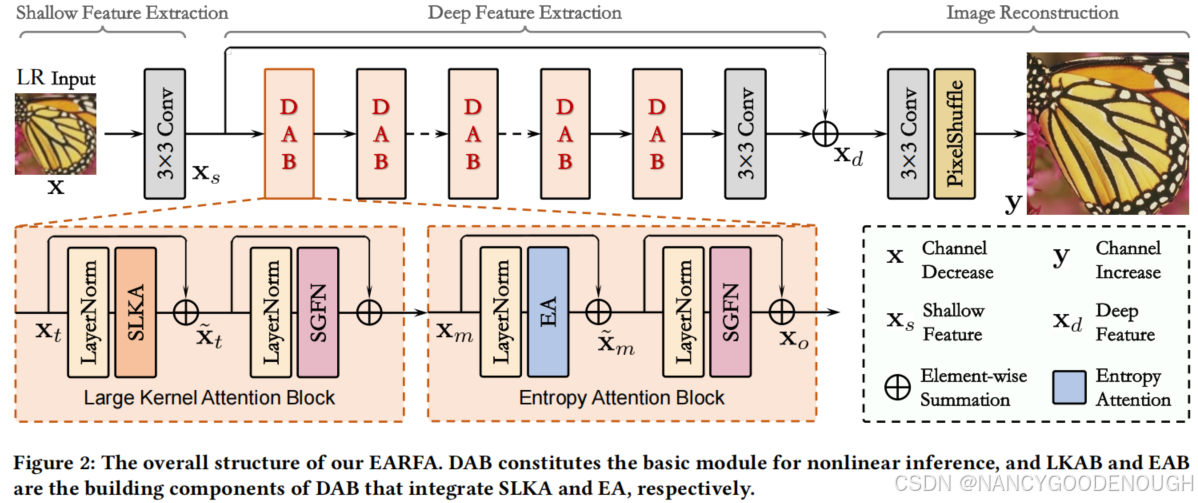
we present an efficient SR model to mitigate the dilemma between model efficiency and SR per
formance, which is dubbed Entropy Attention and Receptive Field Augmentation network (EARFA), and composed of a novel entropy attention (EA) and a shifting large kernel attention (SLKA).
From the perspective of
information theory
,
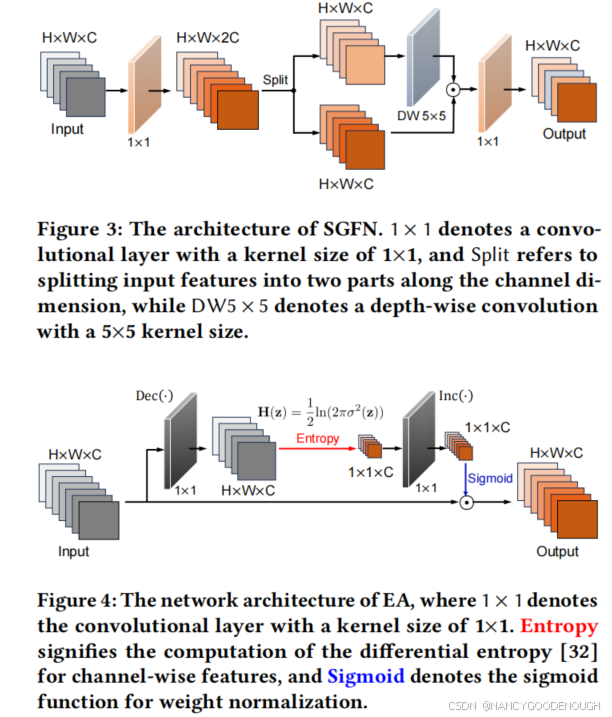
EA is introduced into the model to elevate the entropy of intermediate features conditioned on a Gaussian distribution, and thus increase the input information for subsequent inference. Specifically, it computes the
differential entropy
[
32] for channel-wise features, which is used to measure the information amount in randomly distributed data. And the attention weights are obtained by driving the features approaching to a Gaussian distribution.
[32]
Claude Elwood Shannon. 1948. A mathematical theory of communication.
The
Bell System Technical Journal
27, 3 (1948), 379–423
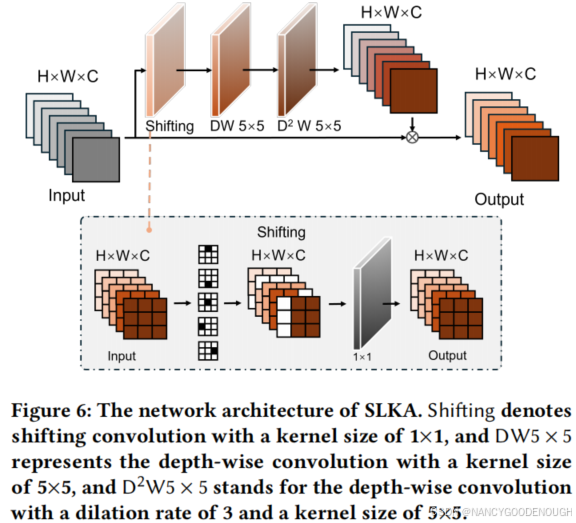
SLKA is an improved version of lager kernel attention (LKA) [
10
] aimed at further augmenting the
effective receptive field of the model with negligible overhead. This is implemented by simply shifting partial channels of a intermediate feature [42].
[10]
Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, and Shi-Min
Hu. 2023. Visual attention network.
Computational Visual Media
9, 4 (2023),
733–752.
[42]
Xiaoming Zhang, Tianrui Li, and Xiaole Zhao. 2023. Boosting Single Image
Super-Resolution via Partial Channel Shifting. In
Proceedings of the IEEE/CVF
International Conference on Computer Vision
. IEEE, 13223–13232.

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









