




 本文介绍了Mybatis_plus的使用,包括建立utf8mb4编码的数据库,数据库连接配置,创建实体类模型,使用sql日志,Springboot测试类,自定义Mapper,服务层接口,tableName注解,雪花算法以及分布式处理Id的逻辑。详细讨论了各部分的配置和作用,如实体类的@Data注解,Mapper的继承,分页插件的应用等。
本文介绍了Mybatis_plus的使用,包括建立utf8mb4编码的数据库,数据库连接配置,创建实体类模型,使用sql日志,Springboot测试类,自定义Mapper,服务层接口,tableName注解,雪花算法以及分布式处理Id的逻辑。详细讨论了各部分的配置和作用,如实体类的@Data注解,Mapper的继承,分页插件的应用等。
这里写目录标题
建立数据库
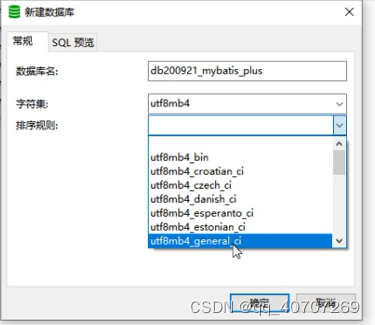
注意一下,这个表应该这么去建
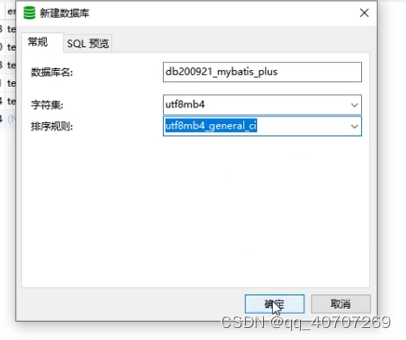
utf8mb4是什麽?为什么要用这个呢?
2.1 utf8
是针对Unicode的一种可变长度字符编码。
由于对可以用Ascll表示的字符,使用Unicode并不高效,因为Unicode比Ascll占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。
为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。
2.2 utf8mb4(mb4 = most bytes 4)
所以utf8是utf8mb4的子集,除了将编码改为utf8mb4外不需要做其他转换。
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
既然utf8应付日常使用完全没有问题,那为什么还要使用utf8mb4呢?
低版本的MySQL支持的utf8编码,最大字符长度为 3 字节,如果遇到 4 字节的字符就会出现错误了。
三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xFFFF,也就是 Unicode 中的基本多文平面(BMP)。
也就是说,任何不在基本多文平面的 Unicode字符,都无法使用MySQL原有的 utf8 字符集存储。
可以到以下的链接,看unicode编码区从1 ~ 126就属于传统utf8区,当然utf8mb4也兼容这个区,126行以下就是utf8mb4扩充区,什么时候你需要存储那些字符,你才用utf8mb4,否则只是浪费空间
————————————————
版权声明:本文为优快云博主「骑台风走」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/qq_52385631/article/details/123019036
utf8mb4_unicode_ci、utf8mb4_general_ci的区别总结
https://blog.youkuaiyun.com/weixin_45839894/article/details/128096805
数据库连接配置文件
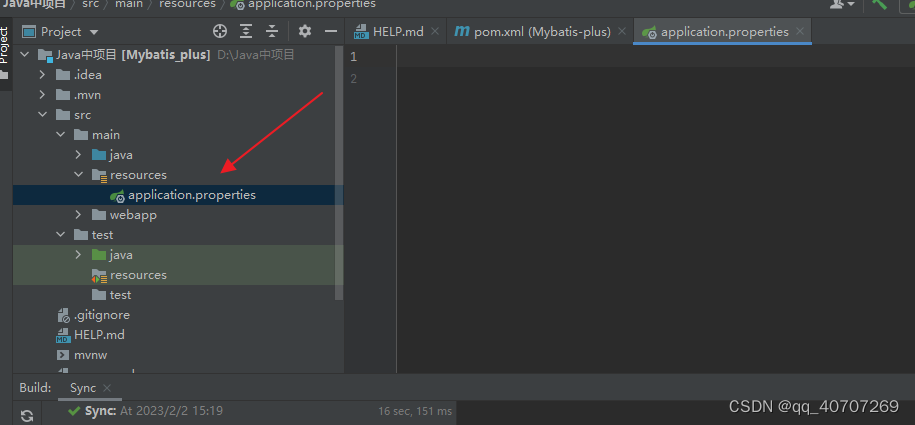
#mysql数据库连接
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis_plus?serverTimezone=GMT%2B8&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=123456
数据库连接这个别自己瞎写了。
创建实体类模型
实体类模型,用于接收数据库中的数据情况
所以
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
必须要一一对应,小数据,要用包装类,ID可能会很长,所以要用长整型。
@Data这个是干嘛呢的呢,就是你装上Lombok插件之后,可以自动生成Getter和Setter方法,或者重写hashcode等方法。
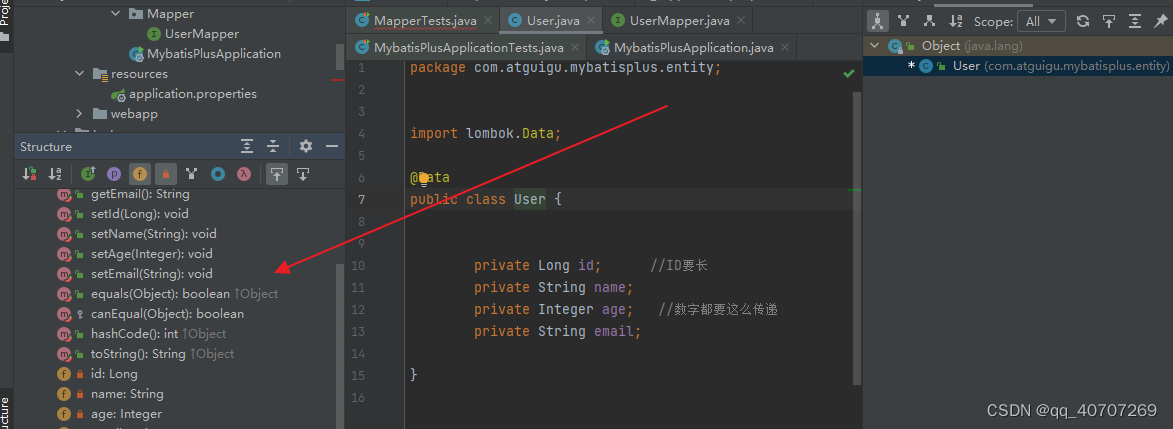
這個可以看类的结构。
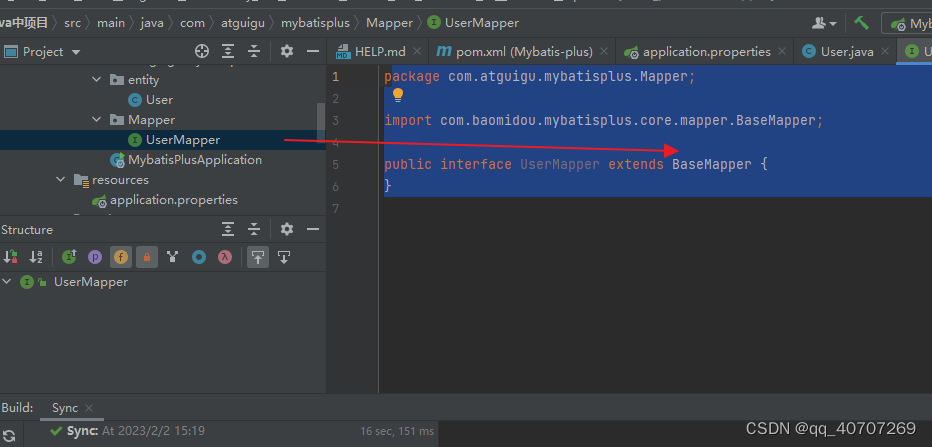
package com.atguigu.mybatisplus.Mapper;
import com.atguigu.mybatisplus.entity.User;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
public interface UserMapper extends BaseMapper<User> {
//你必须告诉电脑,你需要输入的泛型是啥
}
注意这里头有泛型的。
一个实体类,对应一个Mapper
Mapper应该去继承BASEMAPPER
BASEMAPPER中,所有曾删改查的方法,都被USERMAPPER给继承了,相当于省去了我们自己写增删改查。
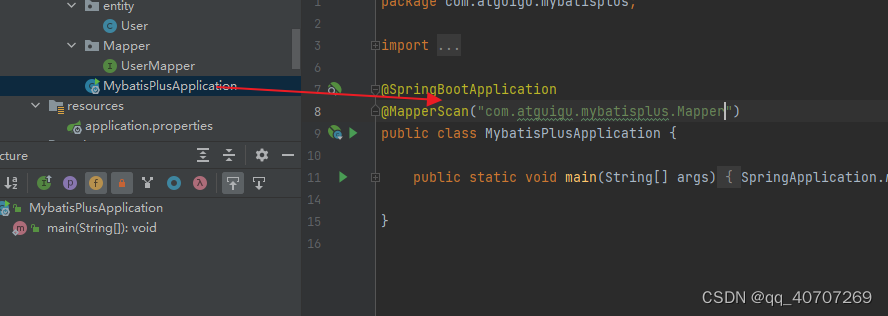
加一個扫描注解,把Mapper这个包扫描进入
springboot天然給安排了一個测试类,主要是需要這個注解
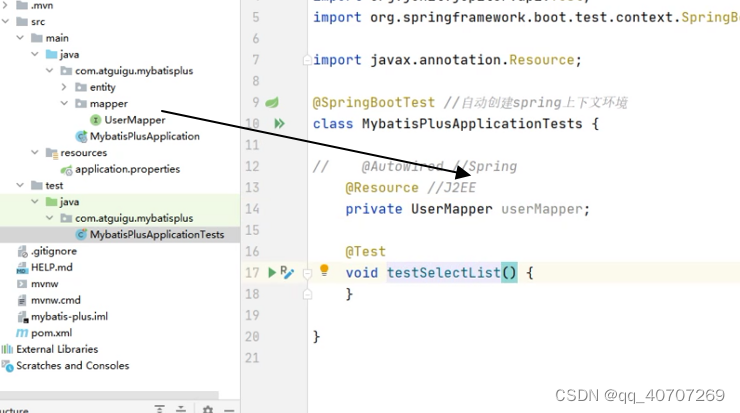
在测试里创建接口类,然后对接口类进行注入。
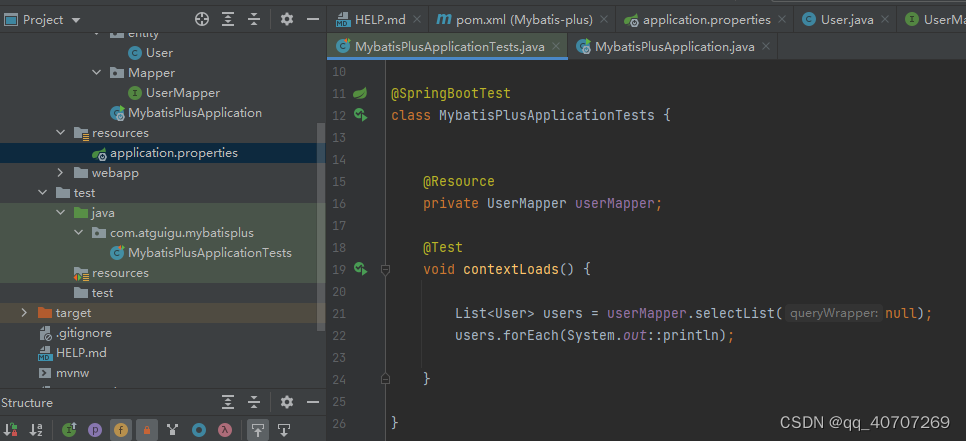
把数据库的东西打印一下,看看,连接没连接上
sql日志的输出
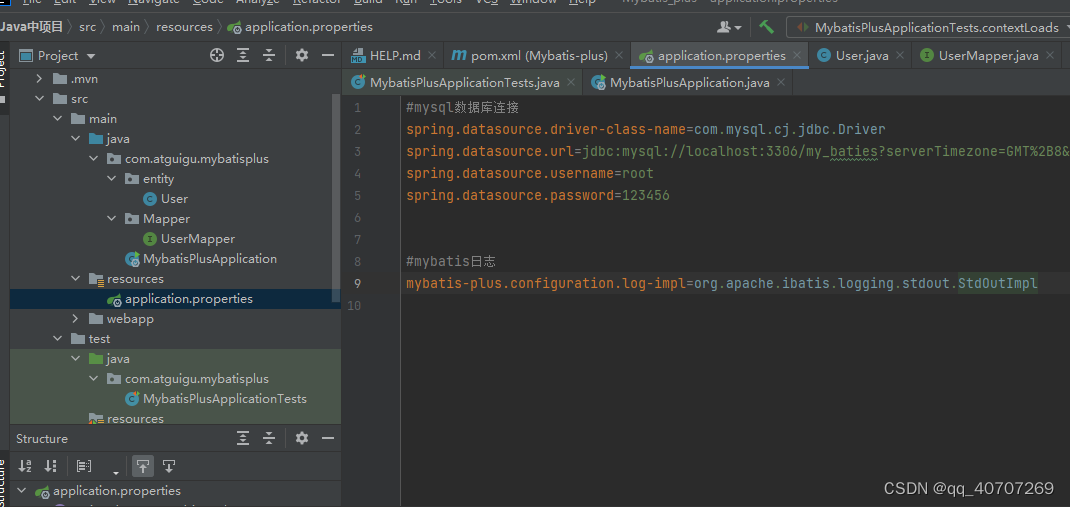
往配置文件裏加一句話就行。
创建springboot的测试类
CTRL + H可以看到类的结构
批量查询

我们可以根据,我们可以往里面放个List,list里面的都是id
自定义Mapper
1.先创建接口

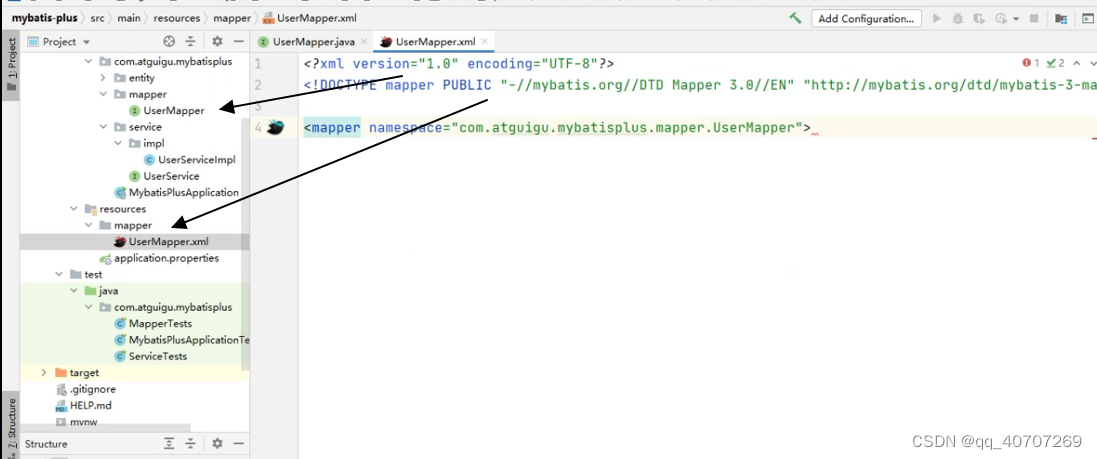
这个配置文件下的mapper基本就相当于一个实现类了
里面的xml写法:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.mybatisplus.mapper.UserMapper">
<sql id="Base_Column_List">
id, name, age, email
</sql>
<select id="selectAllByName" resultType="com.atguigu.mybatisplus.entity.User">
select
<include refid="Base_Column_List"/>
from user
where
name = #{name}
</select>
</mapper>
service
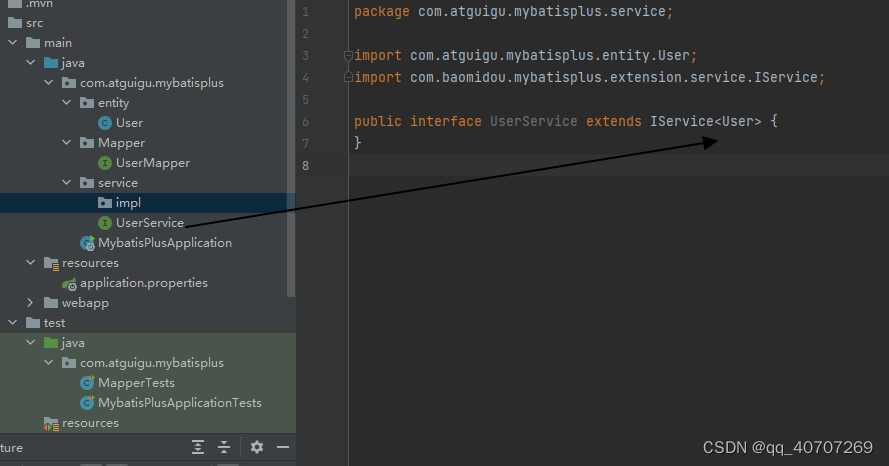
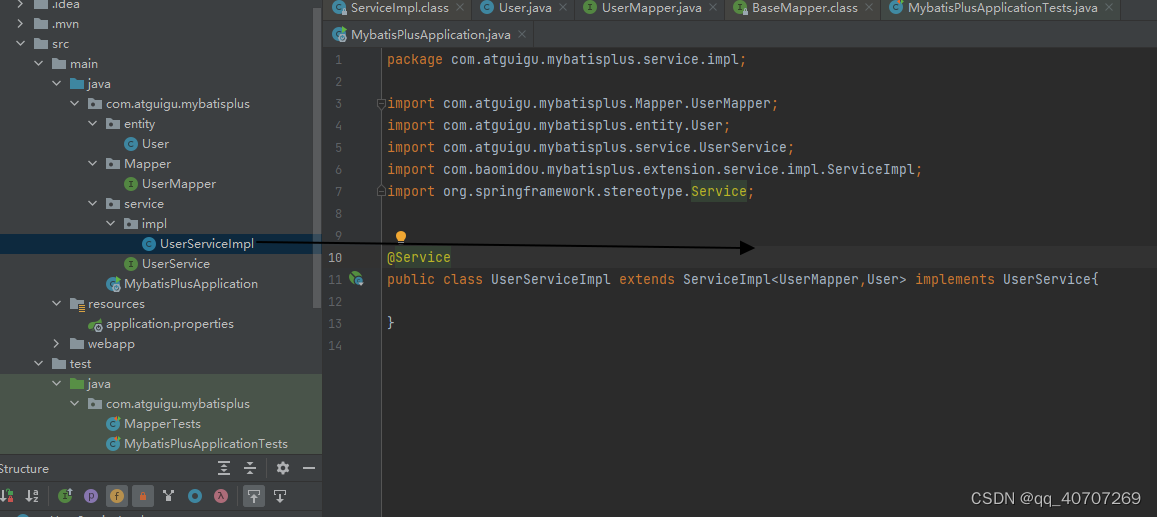
父类本身具有泛型,那么子类继承父类后,就不用写泛型了。

比如後續用到UserService之后,就不用泛型了
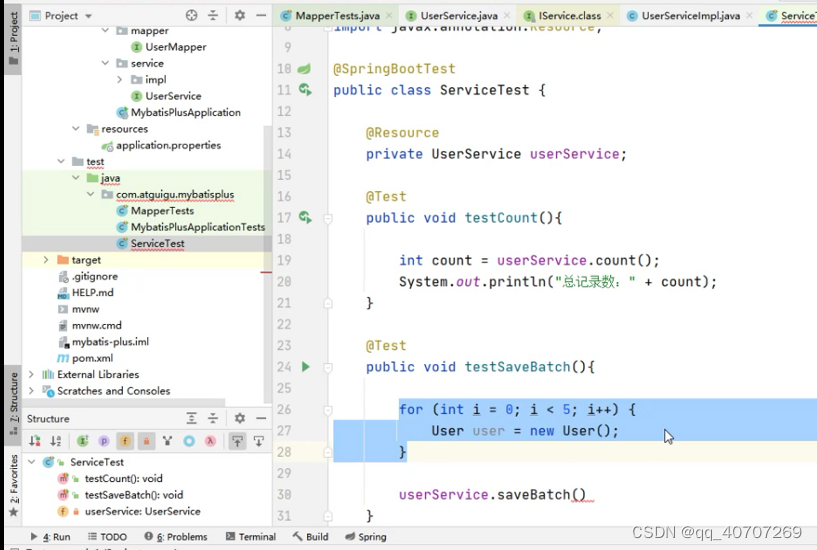
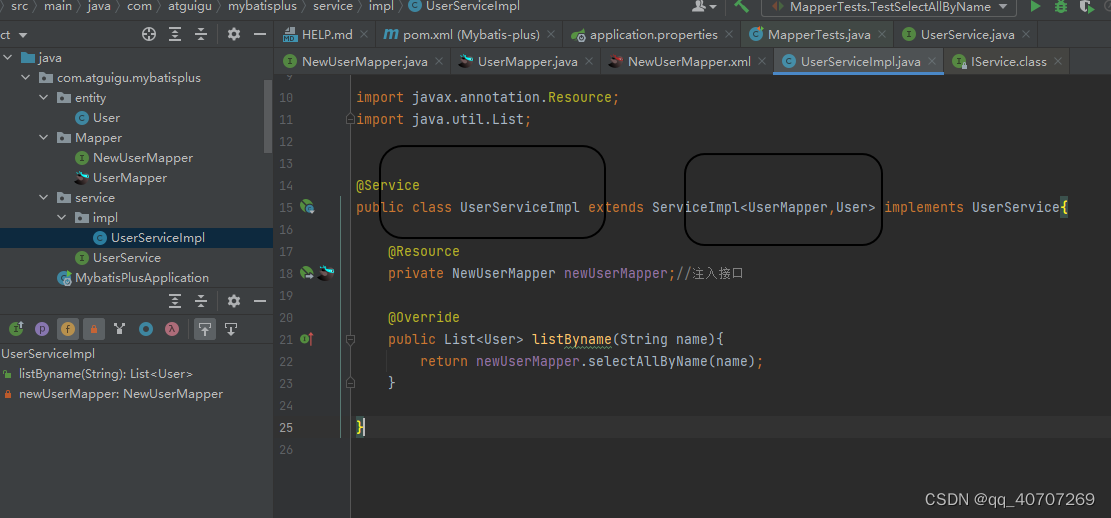
服務端接口实现类,直接点那个小鸟,就能去实现类。
tableName注解
简单的来说,你的类名,叫User,但是实际开发中,会有好多张表,一张表理论上应该对应一个实体类作为模型去接收
但是,问题在于,我们很多好多表
比如管理员表
t_User
商人表
bu_User
老板股东表
bo_User
我们不好一一建立类,对吧??那就用这个注解
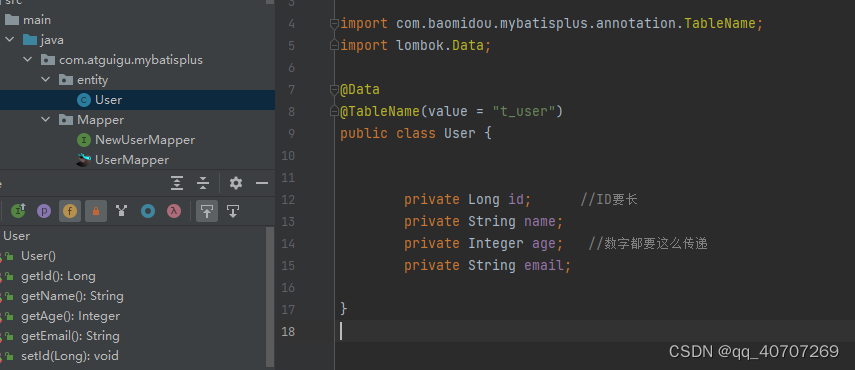
參考一下TableName去生成数据库表名。
雪花算法

为了提高数据库效率,我们可以用分表的方式,解决
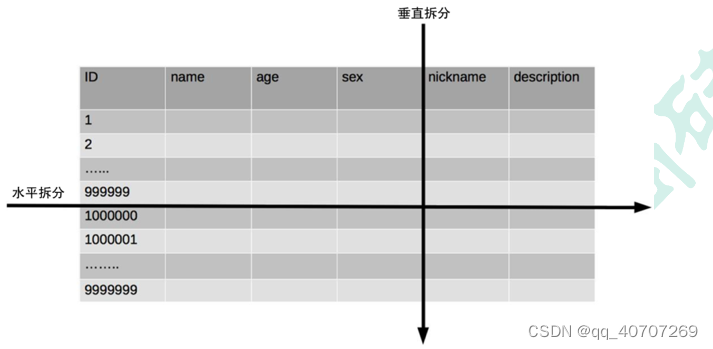
垂直分表:
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
例如,前面示意图中的 nickname 和 description 字段,假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询**,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。**
简单来说就是User是一张表
User_info是一张表,User上存储主要检索信息,User_info上存细节
有点像身份证和在电脑上数据
如果我们把身份证上存太多信息,身份证就很大,很难带。
垂直分表
水平分表适合表行数特别大的表,有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过 1000 万就要分表了;而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。
但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患
简单来说,就是数据量太大了,行太多了
分布式算法
雪花算法:
解决分表后,或者多个表一起处理时候,应该怎么做。
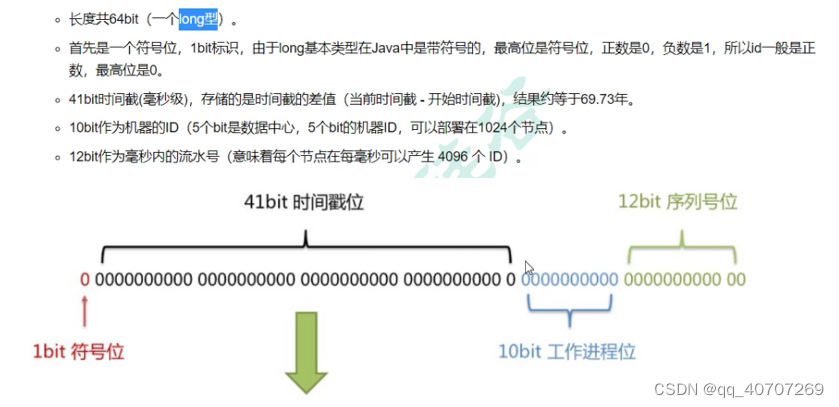
雪花算法,分布式处理Id
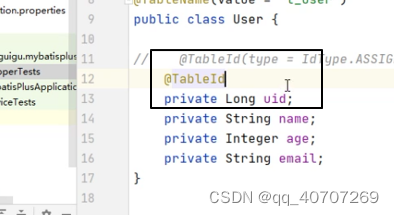
想讓ID应用雪花算法,就在ID上加入这个注解。
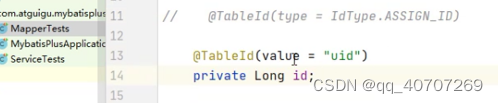
这样可以告诉数据库,我所有的IDEA程序中id,都映射的是你数据库中的那个uid
这种情况是为了解决一个问题,什么问题呢,就是本来我模型和业务,都是做的id对应你表中那个uid,结果好家伙,你就跟我说id这个名字,我看着不顺眼,强制把数据库中那个改成uid了,那我总不到到程序中去一个个改吧???
那直接用这种注解,去一个个做映射就行了。我告诉你我这里头的id和你那个里的uid是一一对应的。
TableField
做映射的,告訴數據庫,我这个对象,对应的是你那个里面的,username

数据库中时间戳
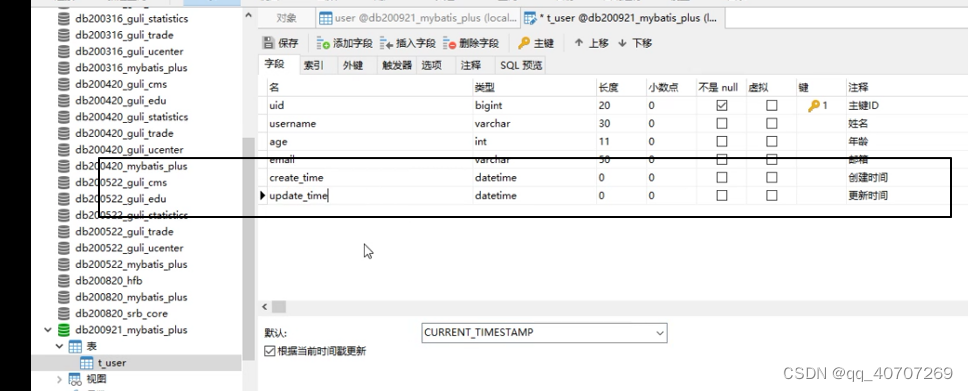
經常性去更新这两个时间太麻烦了,一个简单办法
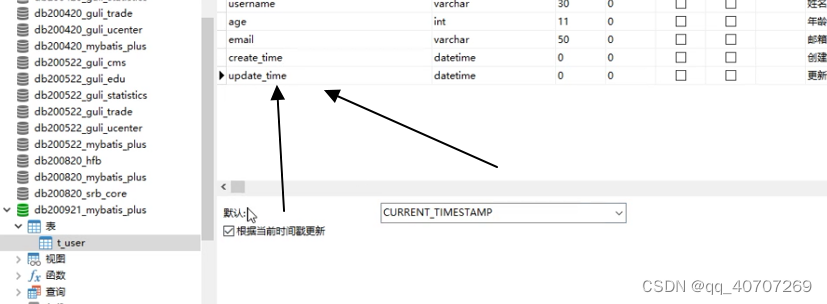
Update時間戳這樣处理,可以保证每次添加或者更新自动更新时间
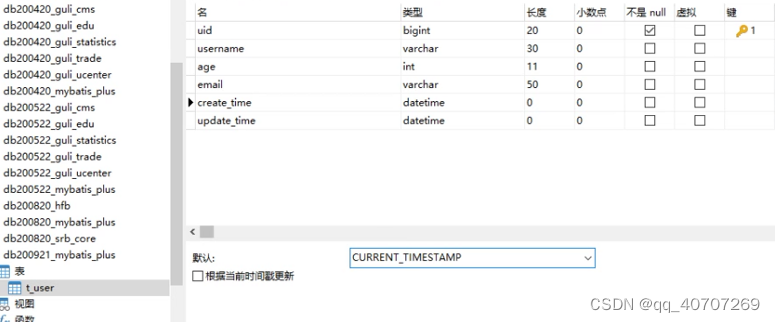
創建的时间只要这个一个就行了,只会在创建的时候,有数据更新。
@TableLogic
1、逻辑删除
物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除的数据
逻辑删除:假删除,将对应数据中代表是否被删除字段的状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录
使用场景:可以进行数据恢复
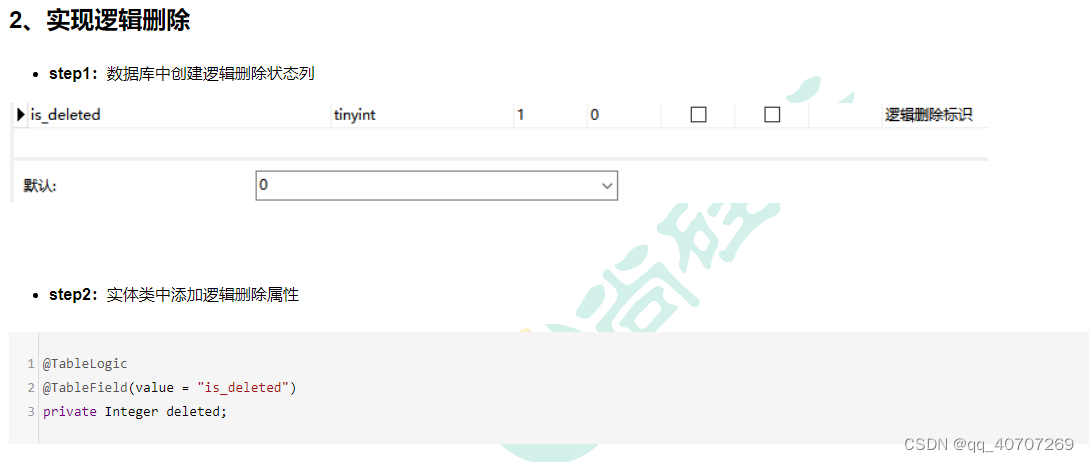
其实就是做一个假性删除,我们在检索时候普遍都带上Is_deleted =0
这样所有被删除的数据都不会被检索了。
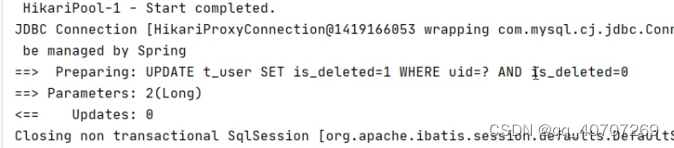
帶上這個标记后,我们执行的就是update语句了,把那个数据改成了1状态,假性删除。
这里我们强调的,全部都是BaseMapper里头的数据。
分页插件
先建立好一個配置類
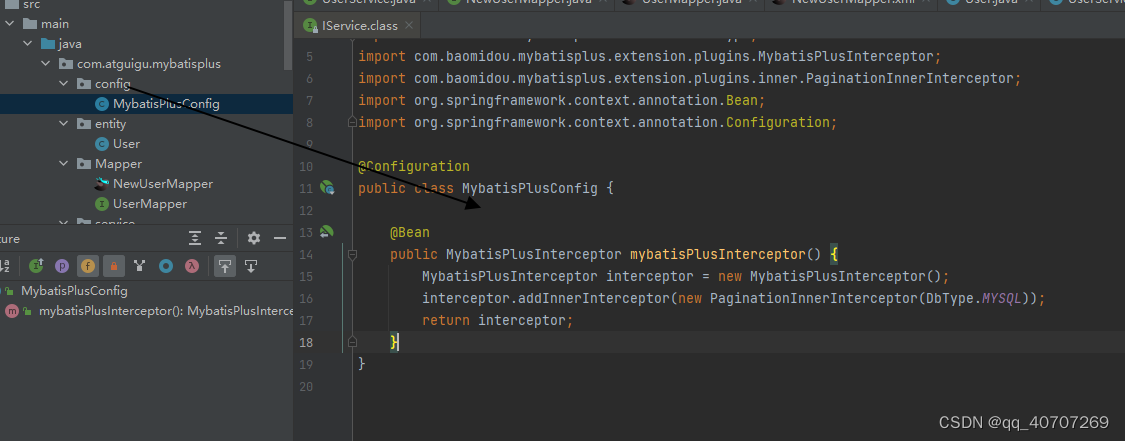
package com.atguigu.mybatisplus.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
然然後做測試

















 3473
3473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









