







手把手刷二叉树算法2
归并排序
二叉搜索树(特性篇)
首先,BST 的特性大家应该都很熟悉了:
-
对于 BST 的每一个节点 node,左子树节点的值都比 node 的值要小,右子树节点的值都比 node 的值大。
-
对于 BST 的每一个节点 node,它的左侧子树和右侧子树都是 BST。
二叉搜索树并不算复杂,但我觉得它可以算是数据结构领域的半壁江山,直接基于 BST 的数据结构有 AVL 树,红黑树等等,拥有了自平衡性质,可以提供 logN 级别的增删查改效率;还有 B+ 树,线段树等结构都是基于 BST 的思想来设计的。
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序)。
寻找第 K 小的元素
链接: 寻找第 K 小的元素.
这个 ↓ 解法并不是最高效的解法,而是仅仅适用于这道题。
class Solution {
public:
int kthSmallest(TreeNode* root, int k) {
// 利用 BST 的中序遍历特性
traverse(root, k);
return res;
}
// 记录结果
int res = 0;
// 记录当前元素排名
int rank = 0;
void traverse(TreeNode* root, int k) {
if (root == nullptr) {
return;
}
traverse(root->left, k);
/* 中序遍历代码位置 */
rank++;
if (k == rank) {
res = root->val;
return;
}
traverse(root->right, k);
}
};
BST 转化累加树
链接: BST 转化累加树.
-
维护一个外部累加变量 sum,在遍历 BST 的过程中增加 sum,同时把 sum 赋值给 BST 中的每一个节点,就将 BST 转化成累加树了。
-
但是注意顺序,正常的中序遍历顺序是先左子树后右子树,这里需要反过来,先右子树后左子树。
class Solution {
public:
TreeNode* convertBST(TreeNode* root) {
traverse(root);
return root;
}
// 记录累加和
int sum = 0;
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
traverse(root->right);
// 维护累加和
sum += root->val;
//将BST转化成累加树
root->val = sum;
traverse(root->left);
}
};
二叉搜索树(基操篇)
在 BST 中搜索元素
链接: 在 BST 中搜索元素.
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == nullptr) {
return nullptr;
}
// 去左子树搜索
if (root->val > val) {
return searchBST(root->left, val);
}
// 去右子树搜索
if(root->val < val) {
return searchBST(root->right, val);
}
return root;
}
};
在 BST 中插入一个数
链接: 在 BST 中插入一个数.
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
// 找到空位置插入新节点
if (root == nullptr) {
return new TreeNode(val);
}
if (root->val < val) {
root->right = insertIntoBST(root->right, val);
}
if (root->val > val) {
root->left = insertIntoBST(root->left, val);
}
return root;
}
};
在 BST 中删除一个数
链接: 在 BST 中删除一个数.
删除比插入和搜索都要复杂一些,分三种情况:
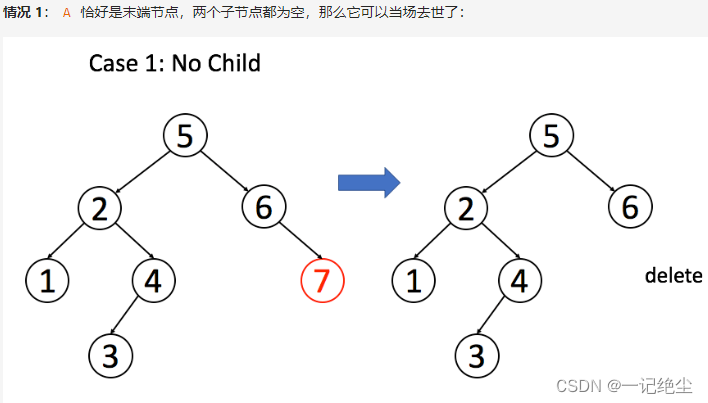
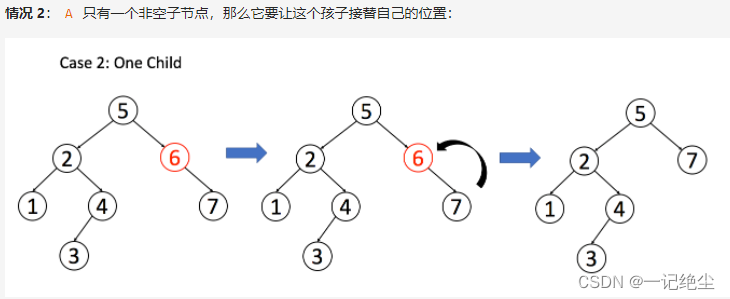
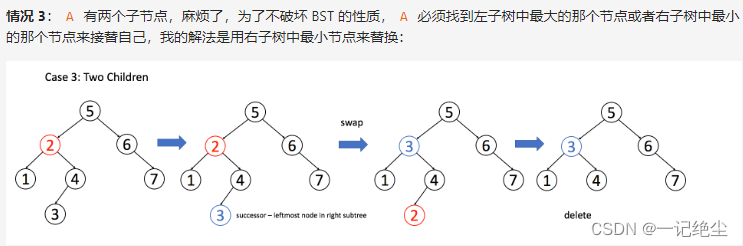
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) {
return nullptr;
}
if (root->val == key) {
// 这两个 if 把情况 1 和 2 都正确处理了
if (root->left == nullptr) {
return root->right;
}
if (root->right == nullptr) {
return root->left;
}
// 处理情况 3
// 获得右子树最小的节点
TreeNode* minNode = getMin(root->right);
// 删除右子树最小的节点
root->right = deleteNode(root->right, minNode->val);
// 用右子树最小的节点替换 root 节点
minNode->left = root->left;
minNode->right = root->right;
root = minNode;
} else if (root->val > key) {
root->left = deleteNode(root->left, key);
} else if (root->val < key) {
root->right = deleteNode(root->right, key);
}
return root;
}
TreeNode* getMin(TreeNode* node) {
// BST 最左边的就是最小的
while (node->left != nullptr) {
node = node->left;
}
return node;
}
};
二叉搜索树(构造篇)
不同的二叉搜索树
链接: 不同的二叉搜索树.
解法:官方解法.
class Solution {
public:
int numTrees(int n) {
vector<int> G(n + 1, 0);
G[0] = 1;
G[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j <= i; ++j) {
G[i] += G[j - 1] * G[i - j];
}
}
return G[n];
}
};
不同的二叉搜索树II
链接: 不同的二叉搜索树II.
想要构造出所有合法 BST,分以下三步:
-
穷举 root 节点的所有可能。
-
递归构造出左右子树的所有合法 BST。
-
给 root 节点穷举所有左右子树的组合。
class Solution {
public:
/* 主函数 */
vector<TreeNode*> generateTrees(int n) {
if (n == 0) {
return {};
}
// 构造闭区间 [1, n] 组成的 BST
return build(1, n);
}
/* 构造闭区间 [lo, hi] 组成的 BST */
vector<TreeNode*> build(int start, int end) {
// base case
if (start > end) {
return { nullptr };
}
vector<TreeNode*> allTrees;
// 枚举可行根节点
for (int i = start; i <= end; i++) {
// 获得所有可行的左子树集合
vector<TreeNode*> leftTrees = build(start, i - 1);
// 获得所有可行的右子树集合
vector<TreeNode*> rightTrees = build(i + 1, end);
// 从左子树集合中选出一棵左子树,从右子树集合中选出一棵右子树,拼接到根节点上
for (auto& left : leftTrees) {
for (auto& right : rightTrees) {
TreeNode* currTree = new TreeNode(i);
currTree->left = left;
currTree->right = right;
allTrees.emplace_back(currTree);
}
}
}
return allTrees;
}
};
快速排序
美团面试官:你对后序遍历一无所知
二叉搜索子树的最大键值和
链接: 二叉搜索子树的最大键值和.
class Solution {
private:
// 记录全局的最大键值和
int maxRes = 0;
// 返回值
// 0: 1是搜索树,0不是搜索树
// 1: 最小值
// 2: 最大值
// 3: 总和: 对于非搜索树,直接返回0
vector<int> dfs(TreeNode* curr)
{
if (curr == nullptr)
{
return {1, INT_MAX, INT_MIN, 0};
}
auto l = dfs(curr->left);
auto r = dfs(curr->right);
vector<int> res(4, 0);
// 只有满足二叉搜索树,才返回结果
// cout << l[0] << " " << r[0] << " " << l[2] << " " << r[1] << " : " << curr->val << endl;
if (l[0] == 1 && r[0] == 1 && l[2] < curr->val && r[1] > curr->val)
{
res[0] = 1;
res[1] = min(l[1], curr->val);
res[2] = max(r[2], curr->val);
res[3] = l[3] + r[3] + curr->val;
maxRes = max(maxRes, res[3]);
}
return res;
}
public:
int maxSumBST(TreeNode* root) {
dfs(root);
return maxRes;
}
};
扁平化嵌套列表迭代器
链接: 扁平化嵌套列表迭代器.
链接: 题解.
Git原理之最近公共祖先
链接: 题解.
二叉树的最近公共祖先
链接: 二叉树的最近公共祖先.

class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
// base case
if (root == nullptr) return nullptr;
if (root == p || root == q) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
//情况1
if (left != nullptr && right != nullptr) return root;
//情况2
if (left == nullptr && right == nullptr) return nullptr;
//情况3
return left == nullptr ? right : left;
}
};
二叉搜索树的最近公共祖先
链接: 二叉搜索树的最近公共祖先.
但对于 BST 来说,根本不需要老老实实去遍历子树,由于 BST 左小右大的性质,将当前节点的值与val1和val2作对比即可判断当前节点是不是LCA:
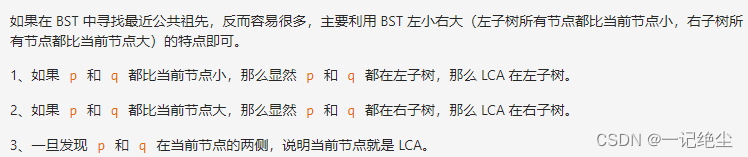
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == nullptr) return nullptr;
if (p->val > q->val) {
// 保证 p.val <= q.val,便于后续情况讨论
return lowestCommonAncestor(root, q, p);
}
if (root->val >= p->val && root->val <= q->val) {
// p <= root <= q
// 即 p 和 q 分别在 root 的左右子树,那么 root 就是 LCA
return root;
}
if (root->val > q->val) {
return lowestCommonAncestor(root->left, p, q);
} else {
// p 和 q 都在 root 的右子树,那么 LCA 在右子树
return lowestCommonAncestor(root->right, p, q);
}
}
};
如何计算完全二叉树的节点数
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^h 个节点。
完全二叉树的节点个数
链接: 完全二叉树的节点个数.
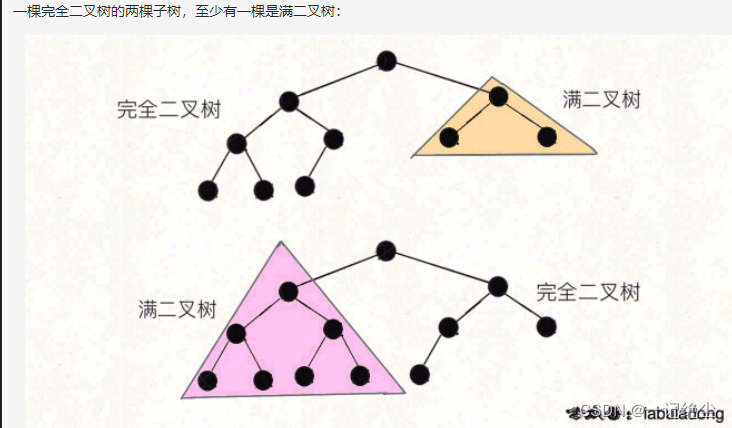
关键点在于,这两个递归只有一个会真的递归下去,另一个一定会触发 hl == hr 而立即返回,不会递归下去。
class Solution {
public:
int countNodes(TreeNode* root) {
TreeNode* l = root, *r = root;
int hl = 0, hr = 0;
while (l != nullptr) {
l = l->left;
hl++;
}
while (r != nullptr) {
r = r->right;
hr++;
}
// 如果左右子树的高度相同,则是一棵满二叉树
if (hl == hr) {
return (int)pow(2, hl) - 1;
}
// 如果左右高度不同,则按照普通二叉树的逻辑计算
return 1 + countNodes(root->left) + countNodes(root->right);
}
};


















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











