







手把手刷二叉树算法
二叉树解题的思维模式:
- 是否可以通过遍历一遍二叉树得到答案? 如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
- 是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案? 如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
无论使用哪种思维模式,你都需要思考:
- 如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做? 其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
二叉树 (纲领篇)
二叉树解题的思维模式分两类:
-
是否可以通过遍历一遍二叉树得到答案? 如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
-
是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案? 如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
无论使用哪种思维模式,你都需要思考:
如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做? 其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
快速排序
用二叉树的视角讲一讲快速排序算法的原理以及运用。
链接: labuladong快速排序详解.
链接: B站快速排序详解.
链接: 力扣排序数组原题.
两种解题思路
二叉树题目的递归解法可以分两类思路,第一类是遍历一遍二叉树得出答案,第二类是通过分解问题计算出答案,这两类思路分别对应着 回溯算法核心框架 和 动态规划核心框架。
链接: 二叉树的最大深度.
所谓最大深度就是根节点到「最远」叶子节点的最长路径上的节点数,比如输入这棵二叉树,算法应该返回 3:
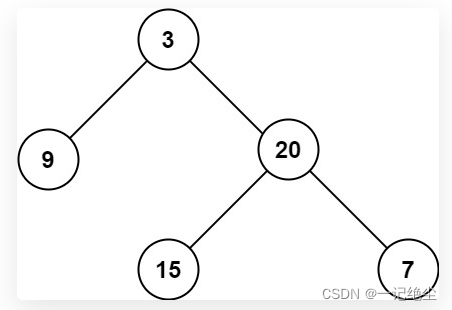
- 你做这题的思路是什么?显然遍历一遍二叉树,用一个外部变量记录每个节点所在的深度,取最大值就可以得到最大深度,这就是遍历二叉树计算答案的思路。
// 回溯算法思路
class Solution {
public:
// 记录最大深度
int res = 0;
// 记录遍历到的节点的深度
int depth = 0;
int maxDepth(TreeNode* root) {
traverse(root);
return res;
}
// 二叉树遍历框架
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
// 前序遍历位置
depth++; // 当前节点的深度
// 遍历的过程中记录最大深度
res = max(res, depth);
traverse(root->left);
traverse(root->right);
// 后序遍历位置
depth--; // 离开这个节点了,就要减1,depth只是当前节点的深度
}
};
- 当然,你也很容易发现一棵二叉树的最大深度可以通过子树的最大高度推导出来,这就是分解问题计算答案的思路。
// 动态规划
class Solution {
public:
// 定义:输入一个节点,返回以该节点为根的二叉树的最大深度
int maxDepth(TreeNode* root) {
if (root == nullptr) {
return 0;
}
int leftMax = maxDepth(root->left);
int rightMax = maxDepth(root->right);
// 根据左右子树的最大深度推出原二叉树的最大深度
return 1 + Math.max(leftMax, rightMax);
}
};
后序位置的特殊之处
DFS:深度优先遍历
二叉树的直径
链接: 二叉树的直径.
解决这题的关键在于,每一条二叉树的「直径」长度,就是一个节点的左右子树的最大深度之和。
- 现在让我求整棵树中的最长「直径」,那直截了当的思路就是遍历整棵树中的每个节点,然后通过每个节点的左右子树的最大深度算出每个节点的「直径」,最后把所有「直径」求个最大值即可。
class Solution {
public:
int maxDiameter = 0;
int diameterOfBinaryTree(TreeNode* root) {
maxDepth(root);
return maxDiameter;
}
int maxDepth(TreeNode* root) {
if (root == nullptr) {
return 0;
}
int leftMax = maxDepth(root->left);
int rightMax = maxDepth(root->right);
// 后序遍历位置顺便计算最大直径
maxDiameter = max(maxDiameter, leftMax + rightMax);
return 1 + max(leftMax, rightMax);
}
};
二叉树中的最大路径和
路径和 是路径中各节点值的总和。
链接: 二叉树中的最大路径和.
class Solution {
int res = INT_MIN;
public:
int maxPathSum(TreeNode* root) {
if (root == nullptr) {
return 0;
}
// 计算单边路径和时顺便计算最大路径和
oneSideMax(root);
return res;
}
// 定义:计算从根节点 root 为起点的最大单边路径和
int oneSideMax(TreeNode* root) {
if (root == nullptr) {
return 0;
}
int leftMaxSum = max(0, oneSideMax(root->left));
int rightMaxSum = max(0, oneSideMax(root->right));
// 后序遍历位置,顺便更新最大路径和
int pathMaxSum = root->val + leftMaxSum + rightMaxSum;
res = max(res, pathMaxSum);
// 实现函数定义,左右子树的最大单边路径和加上根节点的值
// 就是从根节点 root 为起点的最大单边路径和
return max(leftMaxSum, rightMaxSum) + root->val;
}
};
层序遍历
BFS:广度优先遍历
二叉树题型主要是用来培养递归思维的,而层序遍历属于迭代遍历
在每个树行中找最大值
链接: 在每个树行中找最大值.
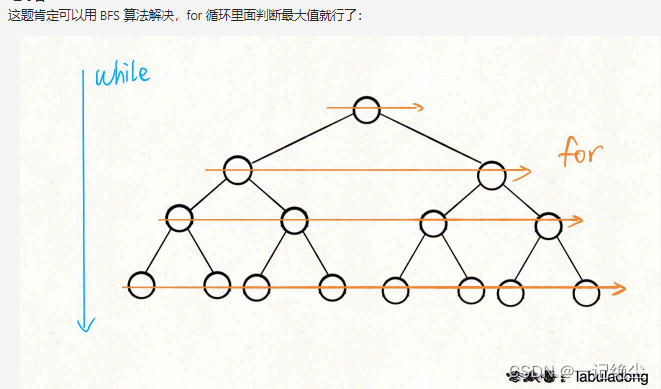
class Solution {
public:
vector<int> largestValues(TreeNode* root) {
vector<int> res;
if (root == nullptr) {
return res;
}
queue<TreeNode*> que;
que.push(root);
// while 循环控制从上向下一层层遍历
while (!que.empty()) {
int size = que.size();
// 记录这一层的最大值
int levelMax = INT_MIN;
// for 循环控制每一层从左向右遍历
for (int i = 0; i < size; i++) {
TreeNode* cur = que.front();
que.pop();
levelMax = max(levelMax, cur->val);
if (cur->left != nullptr) {
que.push(cur->left);
}
if (cur->right != nullptr) {
que.push(cur->right);
}
}
res.push_back(levelMax);
}
return res;
}
};
二叉树(思路篇)
翻转二叉树
只要把二叉树上的每一个节点的左右子节点进行交换,最后的结果就是完全翻转之后的二叉树。
链接: 翻转二叉树.
遍历的思路
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
// 遍历二叉树,交换每个节点的子节点
traverse(root);
return root;
}
// 二叉树遍历函数
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
/**** 前序位置 ****/
// 每一个节点需要做的事就是交换它的左右子节点
TreeNode* temp = root->left;
root->left = root->right;
root->right = temp;
// 遍历框架,去遍历左右子树的节点
traverse(root->left);
traverse(root->right);
}
};
分解问题的思路
我可以用 invertTree(x.left) 先把 x 的左子树翻转,再用 invertTree(x.right) 把 x 的右子树翻转,最后把 x 的左右子树交换,这恰好完成了以 x 为根的整棵二叉树的翻转,即完成了 invertTree(x) 的定义。
- 这种「分解问题」的思路,核心在于你要给递归函数一个合适的定义,然后用函数的定义来解释你的代码;如果你的逻辑成功自恰,那么说明你这个算法是正确的。
class Solution {
public:
// 定义:将以 root 为根的这棵二叉树翻转,返回翻转后的二叉树的根节点
TreeNode* invertTree(TreeNode* root) {
if (root == nullptr) {
return nullptr;
}
// 利用函数定义,先翻转左右子树
TreeNode* left = invertTree(root->left);
TreeNode* right = invertTree(root->right);
// 然后交换左右子节点
root->right = left;
root->left = right;
// 和定义逻辑自恰:以 root 为根的这棵二叉树已经被翻转,返回 root
return root;
}
};
填充节点的右侧指针
链接: 填充节点的右侧指针.
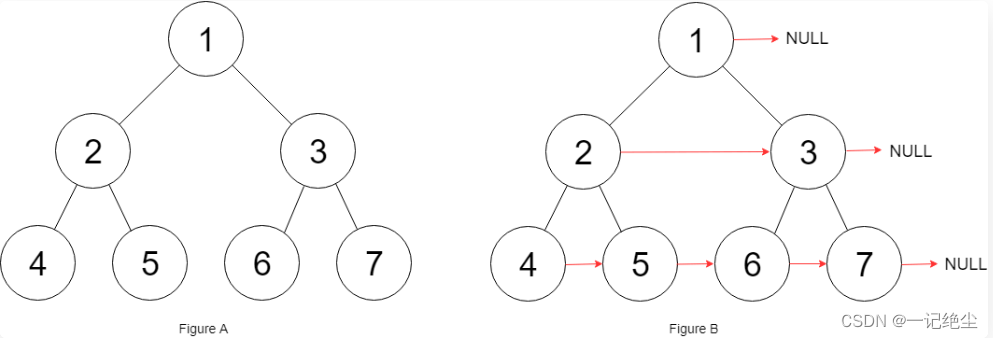
- 你可以把二叉树的相邻节点抽象成一个「三叉树节点」,这样二叉树就变成了一棵「三叉树」,然后你去遍历这棵三叉树,把每个「三叉树节点」中的两个节点连接就行了:
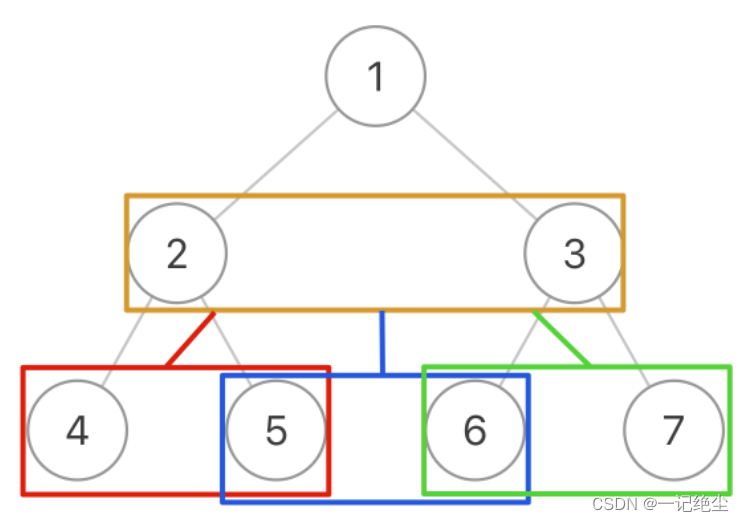
class Solution {
public:
Node* connect(Node* root) {
if (root == nullptr) {
return nullptr;
}
// 遍历「三叉树」,连接相邻节点
traverse(root.left, root.right);
return root;
}
// 三叉树遍历框架
void traverse(Node* node1, Node node2) {
if (node1 == nullptr || node2 == nullptr) {
return;
}
/**** 前序位置 ****/
// 将传入的两个节点穿起来
node1->next = node2;
// 连接相同父节点的两个子节点
traverse(node1->left, node1->right);
traverse(node2->left, node2->right);
// 连接跨越父节点的两个子节点
traverse(node1->right, node2->left);
}
};
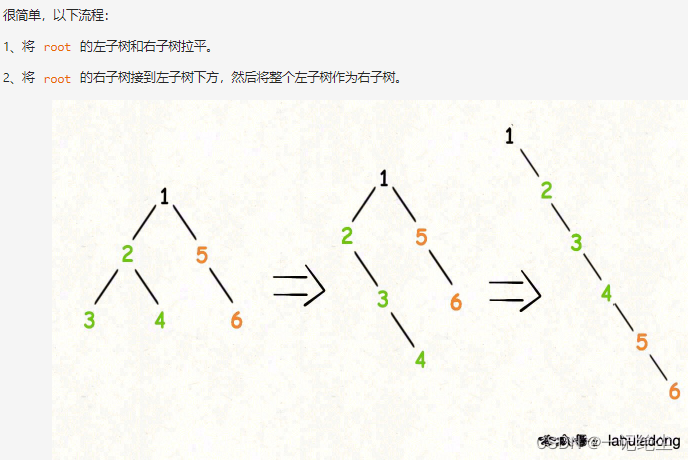
将二叉树展开为链表
链接: 将二叉树展开为链表.
class Solution {
public:
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode* root) {
// base case
if (root == nullptr) {
return;
}
// 先递归拉平左右子树
flatten(root->left);
flatten(root->right);
/****后序遍历位置****/
// 1、左右子树已经被拉平成一条链表
TreeNode* left = root->left;
TreeNode* right = root->right;
// 2、将左子树作为右子树
root->left = nullptr;
root->right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode* p = root;
while (p->right != nullptr) {
p = p->right;
}
p->right = right;
}
};
二叉树(构造篇)
二叉树的构造问题一般都是使用「分解问题」的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树。
构造最大二叉树
链接: 构造最大二叉树.
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return build(nums,0, nums.size() - 1);
}
/* 定义:将 nums[lo..hi] 构造成符合条件的树,返回根节点 */
TreeNode* build(vector<int>& nums, int lo, int hi){
// base case
if (lo > hi) {
return nullptr;
}
// 找到数组中的最大值和对应的索引
int index = -1, maxVal = INT_MIN;
for (int i = lo; i <= hi; i++) {
if (maxVal < nums[i]) {
index = i;
maxVal = nums[i];
}
}
TreeNode* root = new TreeNode(maxVal);
root->left = build(nums, lo, index - 1);
root->right = build(nums, index + 1, hi);
return root;
}
};
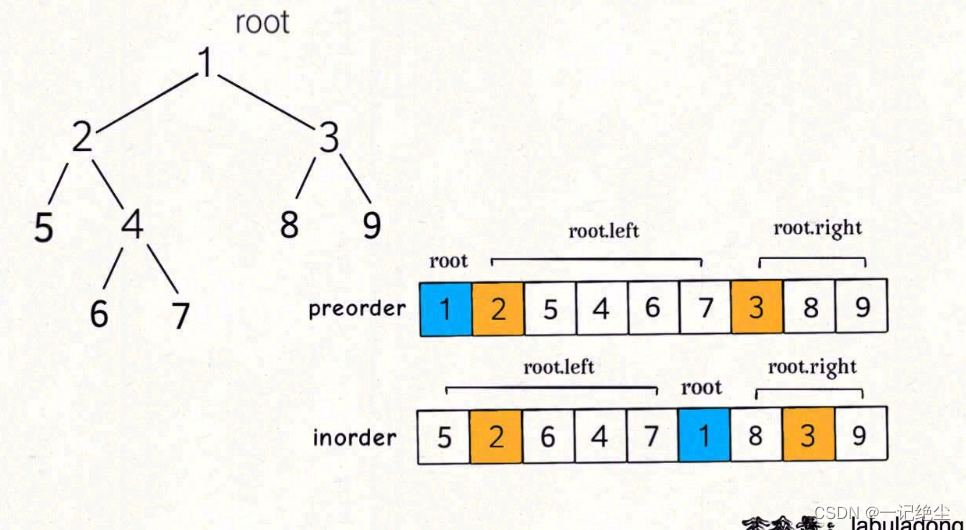
通过前序和中序遍历结果构造二叉树
链接: 通过前序和中序遍历结果构造二叉树.
class Solution {
private:
// 存储 inorder 中值到索引的映射
unordered_map<int, int> valToIndex;
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
for (int i = 0; i < inorder.size(); i++) {
valToIndex[inorder[i]] = i;
}
return build(preorder, 0, preorder.size() - 1,
inorder, 0, inorder.size() - 1);
}
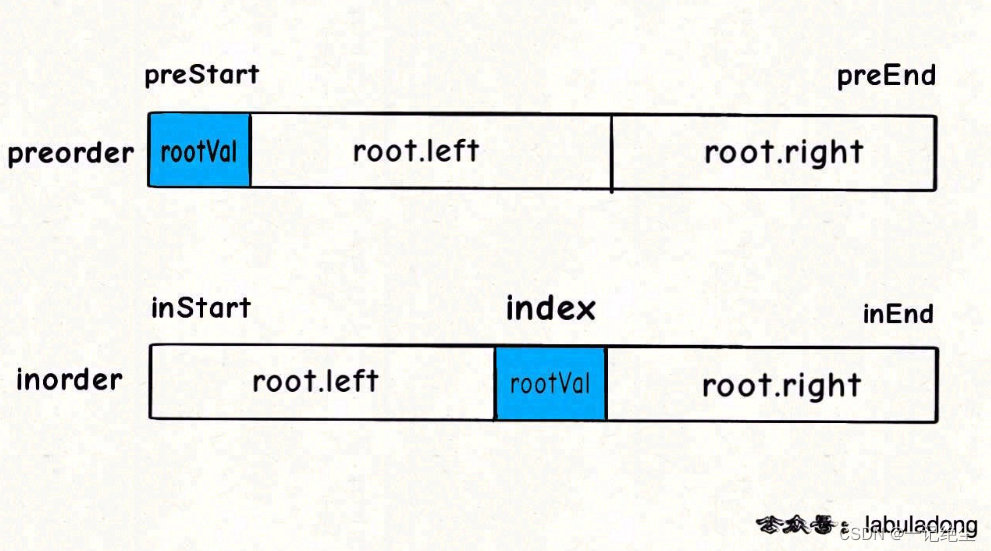
/*
定义:前序遍历数组为 preorder[preStart..preEnd],
中序遍历数组为 inorder[inStart..inEnd],
构造这个二叉树并返回该二叉树的根节点
*/
TreeNode* build(vector<int>& preorder, int preStart, int preEnd,
vector<int>& inorder, int inStart, int inEnd) {
if (preStart > preEnd) {
return nullptr;
}
// base case也可以换成中序
//if (inStart > inEnd) {
// return nullptr;
// }
// root 节点对应的值就是前序遍历数组的第一个元素
int rootVal = preorder[preStart];
// rootVal 在中序遍历数组中的索引
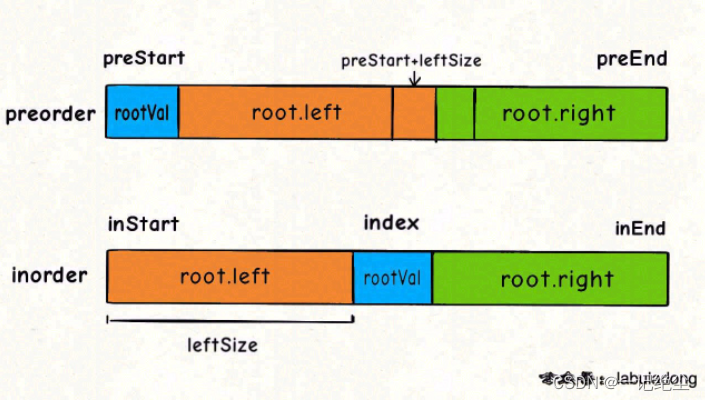
int index = valToIndex[rootVal];
int leftSize = index - inStart;
// 先构造出当前根节点
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
root->left = build(preorder, preStart + 1, preStart + leftSize,
inorder, inStart, index - 1);
root->right = build(preorder, preStart + leftSize + 1, preEnd,
inorder, index + 1, inEnd);
return root;
}
};
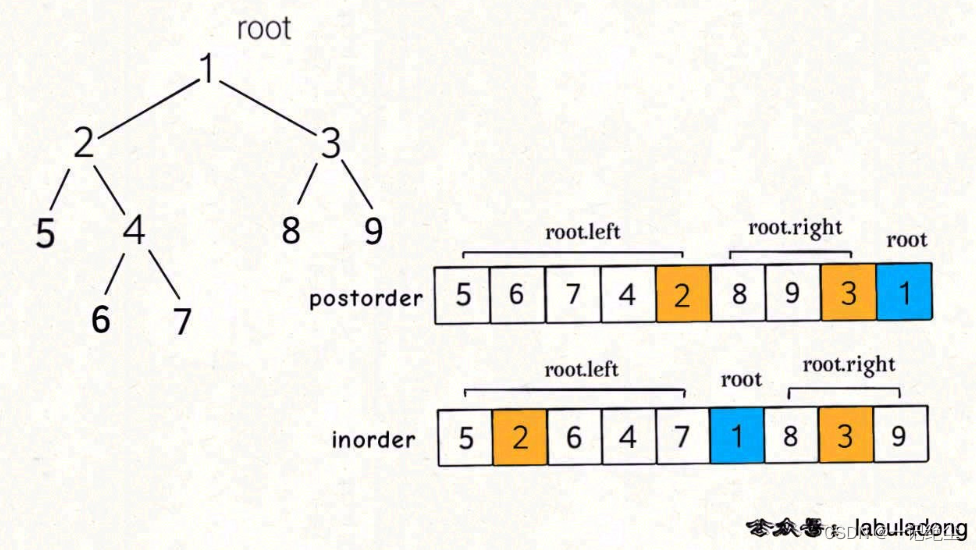
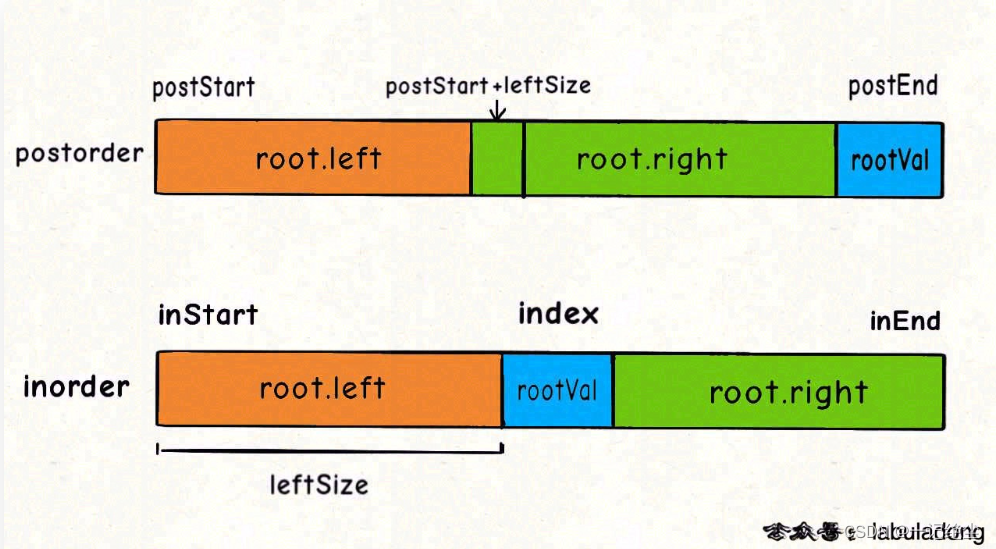
通过后序和中序遍历结果构造二叉树
链接: 通过后序和中序遍历结果构造二叉树.
class Solution {
private:
// 存储 inorder 中值到索引的映射
unordered_map<int, int> valToIndex;
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
for (int i = 0; i < inorder.size(); i++) {
valToIndex[inorder[i]] = i;
}
return build(inorder, 0, inorder.size() - 1,
postorder, 0, postorder.size() - 1);
}
TreeNode* build(vector<int>& inorder, int inStart, int inEnd,
vector<int>& postorder, int postStart, int postEnd) {
if (inStart > inEnd) {
return nullptr;
}
/// base case也可以换成后序的
// if (postStart > postEnd) {
// return nullptr;
// }
// root 节点对应的值就是后序遍历数组的最后一个元素
int rootVal = postorder[postEnd];
// rootVal 在中序遍历数组中的索引
int index = valToIndex[rootVal];
// 左子树的节点个数
int leftSize = index - inStart;
// 先构造出当前根节点
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
root->left = build(inorder, inStart, index - 1,
postorder, postStart, postStart + leftSize - 1);
root->right = build(inorder, index + 1, inEnd,
postorder, postStart + leftSize, postEnd - 1);
return root;
}
};
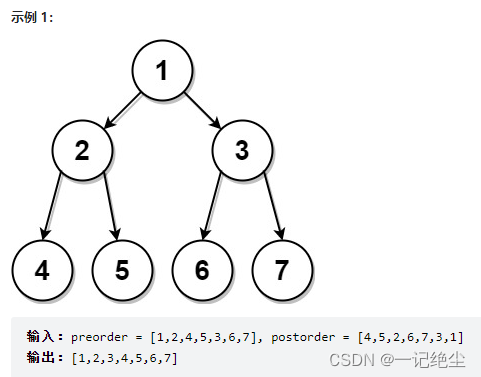
通过后序和前序遍历结果构造二叉树
链接: 通过后序和前序遍历结果构造二叉树.
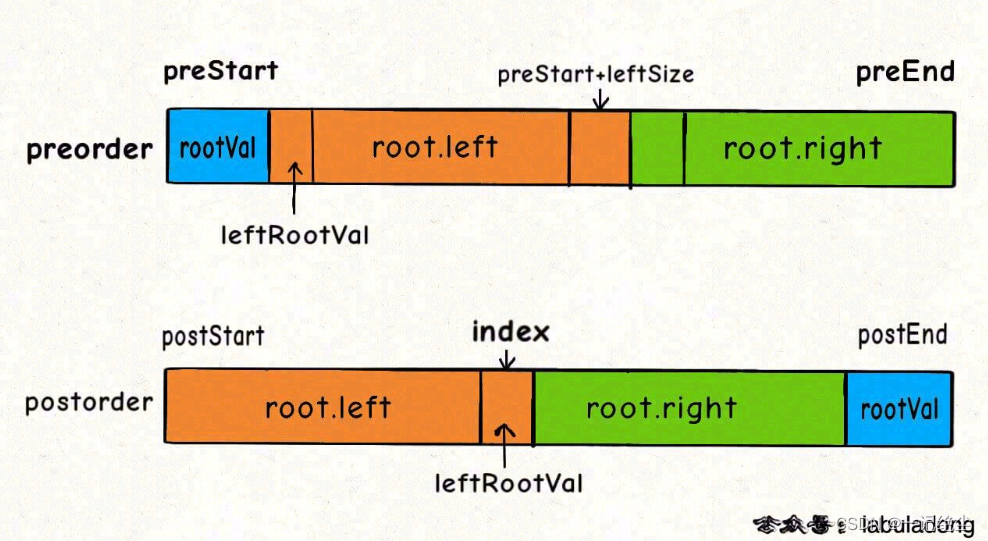
这道题和前两道题有一个本质的区别:通过前序中序,或者后序中序遍历结果可以确定一棵原始二叉树,但是通过前序后序遍历结果无法确定原始二叉树。题目也说了,如果有多种可能的还原结果,你可以返回任意一种。为什么呢?我们说过,构建二叉树的套路很简单,先找到根节点,然后找到并递归构造左右子树即可。前两道题,可以通过前序或者后序遍历结果找到根节点,然后根据中序遍历结果确定左右子树(题目说了树中没有 val 相同的节点)。这道题,你可以确定根节点,但是无法确切的知道左右子树有哪些节点
1、首先把前序遍历结果的第一个元素或者后序遍历结果的最后一个元素确定为根节点的值。
2、然后把前序遍历结果的第二个元素作为左子树的根节点的值。
3、在后序遍历结果中寻找左子树根节点的值,从而确定了左子树的索引边界,进而确定右子树的索引边界,递归构造左右子树即可。
class Solution {
private:
// 存储 postorder 中值到索引的映射
unordered_map<int, int> valToIndex;
public:
TreeNode* constructFromPrePost(vector<int>& preorder, vector<int>& postorder) {
for (int i = 0; i < postorder.size(); i++) {
valToIndex[postorder[i]] = i;
}
return build(preorder, 0, preorder.size() - 1,
postorder, 0, postorder.size() - 1);
}
// 定义:根据 preorder[preStart..preEnd] 和 postorder[postStart..postEnd]
// 构建二叉树,并返回根节点。
TreeNode* build(vector<int>& preorder, int preStart, int preEnd,
vector<int>& postorder, int postStart, int postEnd) {
if (preStart > preEnd) {
return nullptr;
}
if (preStart == preEnd) {
return new TreeNode(preorder[preStart]);
}
// root 节点对应的值就是前序遍历数组的第一个元素
int rootVal = preorder[preStart];
// root->left 的值是前序遍历第二个元素
// 通过前序和后序遍历构造二叉树的关键在于通过左子树的根节点
// 确定 preorder 和 postorder 中左右子树的元素区间
int leftRootVal = preorder[preStart + 1];
// leftRootVal 在后序遍历数组中的索引
int index = valToIndex[leftRootVal];
// 左子树的元素个数
int leftSize = index - postStart + 1;
// 先构造出当前根节点
TreeNode* root = new TreeNode(rootVal);
// 递归构造左右子树
// 根据左子树的根节点索引和元素个数推导左右子树的索引边界
root->left = build(preorder, preStart + 1, preStart + leftSize,
postorder, postStart, index);
root->right = build(preorder, preStart + leftSize + 1, preEnd,
postorder, index + 1, postEnd);
return root;
}
};
二叉树(序列化篇)
「序列化」和「反序列化」的目的,以某种固定格式组织字符串,使得数据可以独立于编程语言
- 那么假设现在有一棵用 Java 实现的二叉树,我想把它序列化字符串,然后用 C++ 读取这棵并还原这棵二叉树的结构,怎么办?这就需要对二叉树进行「序列化」和「反序列化」了。
二叉树的序列化与反序列化
链接: 二叉树的序列化与反序列化.
前序遍历解法
二叉树(后序篇)
寻找重复的子树
链接: 寻找重复的子树.
class Solution {
// 记录所有子树以及出现的次数
unordered_map<string, int> memo;
// 记录重复的子树根节点
vector<TreeNode*> res;
public:
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
traverse(root);
return res;
}
string traverse(TreeNode* root) {
if (root == nullptr) {
return "#";
}
string left = traverse(root->left);
string right = traverse(root->right);
string subTree = left + "," + right + "," + to_string(root->val);
if (memo[subTree] == 1) {
res.push_back(root);
}
memo[subTree]++;
return subTree;
}
};


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











