






集群搭建
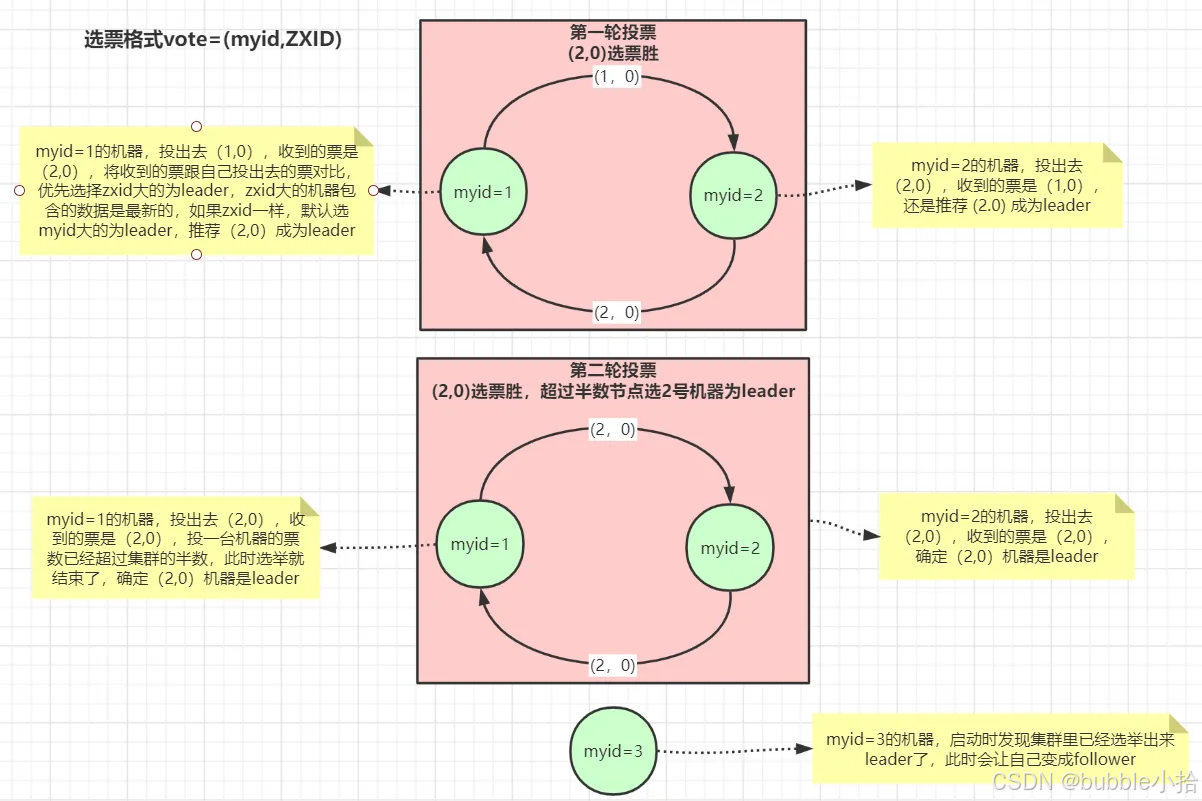
Leader选举原理
- Serverid:服务器ID。比如有三台服务器,编号分别是1,2,3.编号越大在选择算法中的权重越大。
- Zxid:数据ID。服务器中存放的最大数据ID,值越大说明数据越新,在选举算法中数据越新权重越大。
- 在Leader选举的过程中,如果某台Zookeeper获得了超过半数的选票,则此Zookeeper就可以成为Leader了。
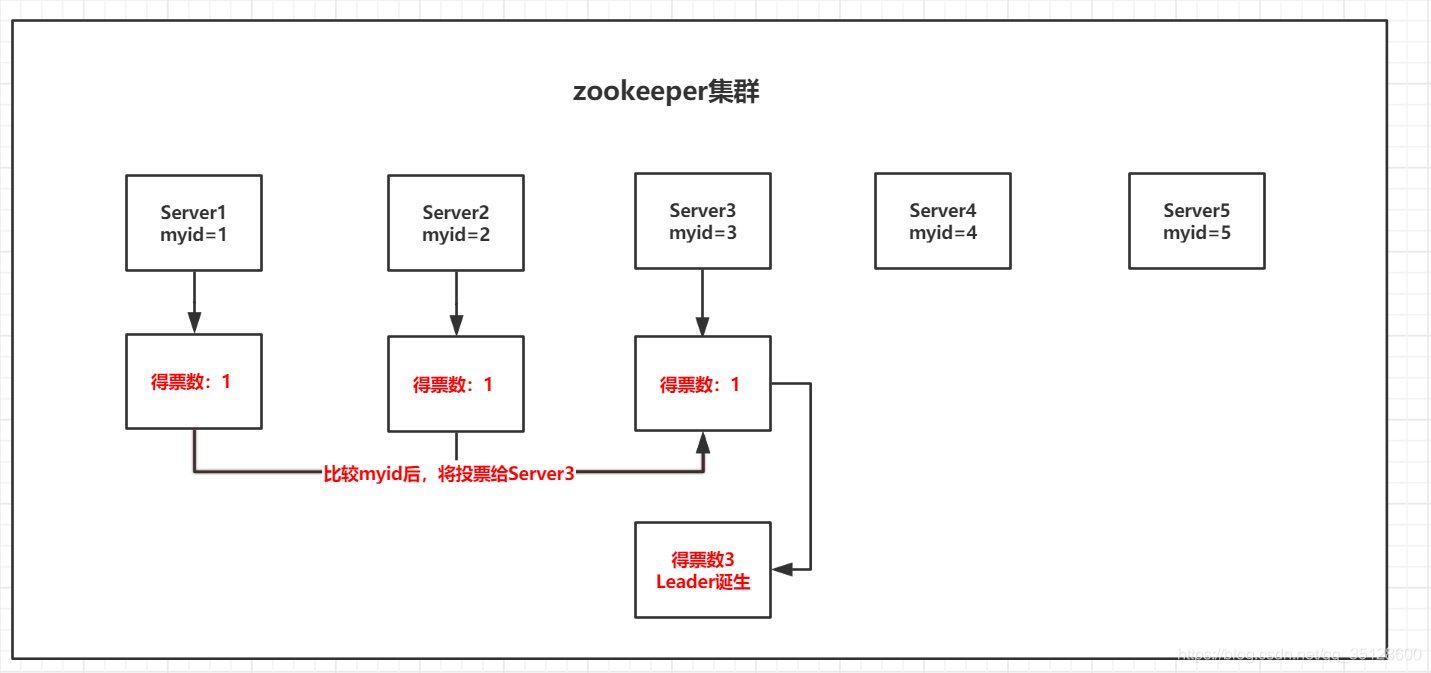
如果集群中有5台ZK,myid依次增大,先后启动,Server3得到3票支持后会成为Leader
Windows集群下搭建zk
- 复制下载的zk为三份

- 分别修改3个目录下-》conf-》zoo.cfg配置文件如下
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
clientPort=2181
dataDir=D://soft//apache-zookeeper-3.5.7-bin//data
dataLogDir=D://soft//apache-zookeeper-3.5.7-bin//log
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
clientPort=2182
dataDir=D://soft//apache-zookeeper-3.5.7-bin-2//data
dataLogDir=D://soft//apache-zookeeper-3.5.7-bin-2//log
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
clientPort=2183
dataDir=D://soft//apache-zookeeper-3.5.7-bin-3//data
dataLogDir=D://soft//apache-zookeeper-3.5.7-bin-3//log
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
- 分别修改3个目录下-》data-》myid文件如下:
1
2
3
- 创建一个.bat文件一键启动3个zk:
echo -------------------zk集群启动-------------------
start /d "D:\soft\apache-zookeeper-3.5.7-bin\bin" zkServer.cmd
start /d "D:\soft\apache-zookeeper-3.5.7-bin-2\bin" zkServer.cmd
start /d "D:\soft\apache-zookeeper-3.5.7-bin-3\bin" zkServer.cmd
故障测试
当有3台zk节点,zk-2为Leader时
停止zk-3节点观察集群状态
停止掉zk-3节点后丝毫不会影响集群的使用,当前集群中还有一个Follower节点和一个Leader节点。
停止两个Follower节点观察集群状态
当集群中所有的Follower节点都挂掉后,集群将不可用,正常的Leader节点也会提示没有启动。(因为领导没有下属了)
恢复其中一个Follower节点观察集群状态
当有一个Follower节点恢复后,整个集群也会恢复。
停止Leader节点观察其他集群状态
当Leader节点挂掉后,其余Follower节点会再次进行选举,选举出新的节点为Leader,当原Leader启动后也不会在和新Leader去竞争,而是处于Follower节点。
集群角色
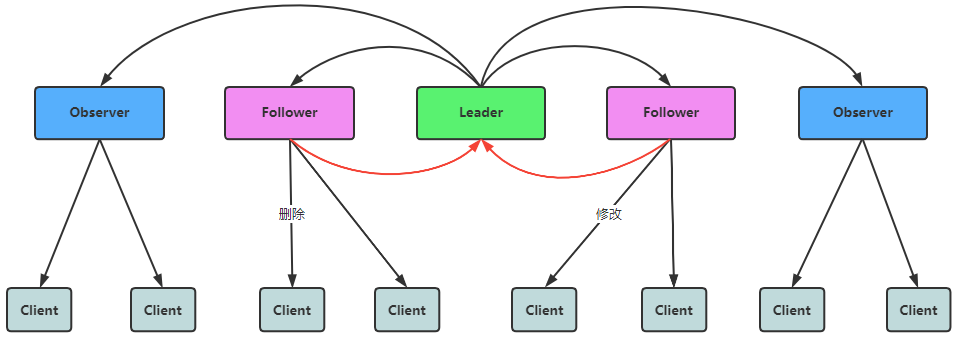
Leader: 领导者
事务请求(写操作)的唯一调度者和处理者,保证集群事务处理的顺序性;集群内部各个服务器的调度者。对于create、setData、delete等有写操作的请求,则要统一转发给leader处理,leader需要决定编号、执行操作,这个过程称为事务。
Follower: 跟随者
处理客户端非事务(读操作)请求(可以直接响应),转发事务请求给Leader;参与集群Leader选举投票。
Observer: 观察者
对于非事务请求可以独立处理(读操作),对于事务性请求会转发给leader处理。Observer节点接收来自leader的inform信息,更新自己的本地存储,不参与提交和选举投票。通常在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
#配置一个ID为3的观察者节点:
server.3=192.168.0.3:2888:3888:observer
Observer应用场景:
- 提升集群的读性能。因为Observer和不参与提交和选举的投票过程,所以可以通过往集群里面添加observer节点来提高整个集群的读性能。
- 跨数据中心部署。 比如需要部署一个北京和香港两地都可以使用的zookeeper集群服务,并且要求北京和香港客户的读请求延迟都很低。解决方案就是把北京和香港的节点都设置为observer。
Zookeeper数据一致性保证:
- 全局可线性化(Linearizable )写入∶先到达leader的写请求会被先处理,leader决定写请求的执行顺序。
- 客户端FIFO顺序∶来自给定客户端的请求按照发送顺序执行。
参考博客:
https://blog.youkuaiyun.com/weixin_38997187/article/details/102980505
https://blog.youkuaiyun.com/qq_45061342/article/details/141233928
https://blog.youkuaiyun.com/qq_44501429/article/details/137410955



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









