







 本文主要介绍了Jmeter的正则表达式提取器。详细说明了Apply to的不同作用范围,如作用于父节点取样器及子节点取样器等;还介绍了要检查的响应字段、引用名称、正则表达式、模板、匹配数字和缺省值等参数的含义及使用方法。
本文主要介绍了Jmeter的正则表达式提取器。详细说明了Apply to的不同作用范围,如作用于父节点取样器及子节点取样器等;还介绍了要检查的响应字段、引用名称、正则表达式、模板、匹配数字和缺省值等参数的含义及使用方法。
1.jmeter的【正则表达式提取器】界面如下:
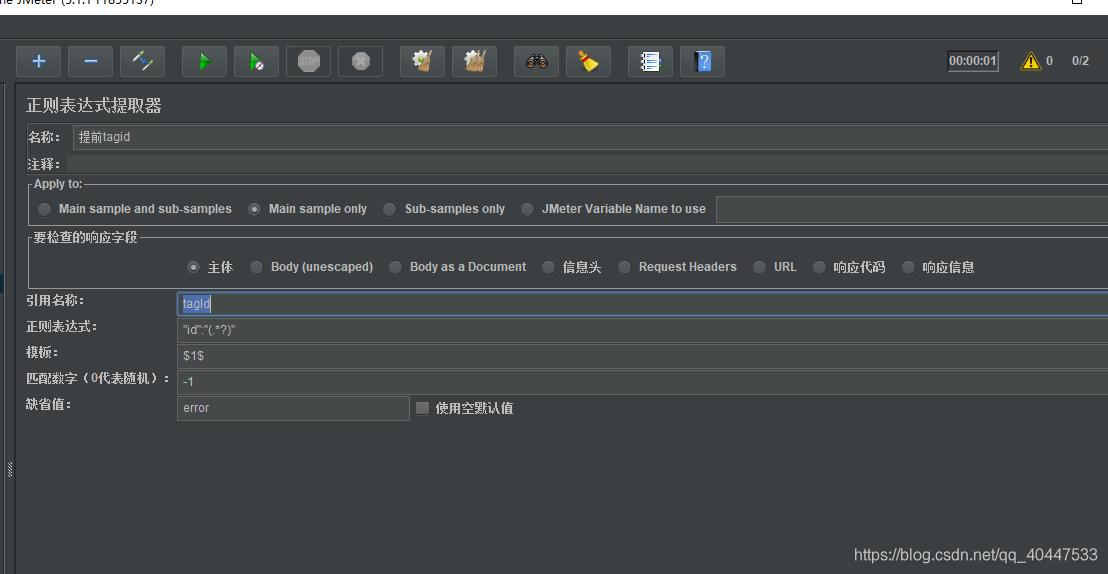 参数说明:
参数说明:
APPly to:
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
要检查的响应字段:需要检查的响应报文的范围
主体:响应报文的主体
Body(unescaped):主体,响应的主体内容且替换了所有的html转义符,注意html转义符处理时不考虑上下文,因此可能有 不正确的转换,不太建议使用
Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
Response Headers:响应信息头
Request Headers:请求信息头
URL:统一资源定位符,即Internet上用来描述信息资源的字符串
Response Code:响应状态码,比如200、404等
Response Message:响应信息
引用名称(Reference Name):Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名(例子中我提取的是tagID)
引用方法:引用方法:${引用名称}
正则表达式(Regular Expression):使用正则表达式解析响应结果,“()”表示提取字符串中的部分值,请不要使用“||”,除非你本身需要匹配这个字符。
模板(Template):从匹配的结果中创建一个字符串,这是通过正则表达式匹配出来的一组值,意为使用提取到的第几个值(可能有多个值匹配,因此使用模板);从1开始匹配,以此类推.对应正则表达式提取器类型,样式为:$n$
参数可以在取值模板组合使用,例如:“11-22”作为模板得到的值是使用“-”连接的第一个待匹配内容与第二个待匹配内容组合而成的字符串。
匹配数字(Match No):正则表达式匹配数据的结果可以看做一个数组,表示如何取值:0代表随机取值,正数n则表示取第n个值(比如1代表取第一个值),任意负数则表示提取所有符合条件的值。
缺省值:匹配失败时候的默认值;通常用于后续的逻辑判断,一般通常为特定含义的英文大写组合,比如:ERROR

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









