







代码:
import requests
import os
url = "https://gss0.baidu.com/-Po3dSag_xI4khGko9WTAnF6hhy/zhidao/wh%3D600%2C800/sign=bc75fc5640a7d933bffdec759d7bfd2b/d009b3de9c82d1587f799ff3820a19d8bd3e42fd.jpg"
root = "D://pics//"
path = root +url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
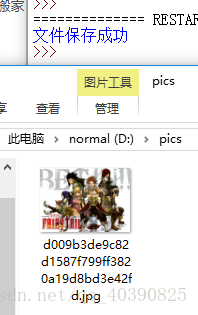
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬去失败")
输出:

















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









