







 本文详细介绍了YOLOv5相较于YOLOv4的改进之处,包括Mosaic数据增强、自适应锚框计算、自适应图片缩放等训练策略,以及FOCUS结构、CSP网络和FPN_PAN结构在模型设计中的应用。此外,文章还探讨了GIoU_Loss在目标检测任务中的作用,强调了这些改进对提升模型性能和训练效率的影响。
本文详细介绍了YOLOv5相较于YOLOv4的改进之处,包括Mosaic数据增强、自适应锚框计算、自适应图片缩放等训练策略,以及FOCUS结构、CSP网络和FPN_PAN结构在模型设计中的应用。此外,文章还探讨了GIoU_Loss在目标检测任务中的作用,强调了这些改进对提升模型性能和训练效率的影响。
一、与yoloV4相比,yoloV5的改进
- 输入端:在模型训练阶段,使用了Mosaic数据增强、自适应锚框计算、自适应图片缩放
- 基准网络:使用了FOCUS结构和CSP结构
- Neck网络:在Backbone和最后的Head输出层之间插入FPN_PAN结构
- Head输出层:训练时的损失函数GIOU_Loss,预测筛选框的DIOU_nns
二、yoloV5结构框架
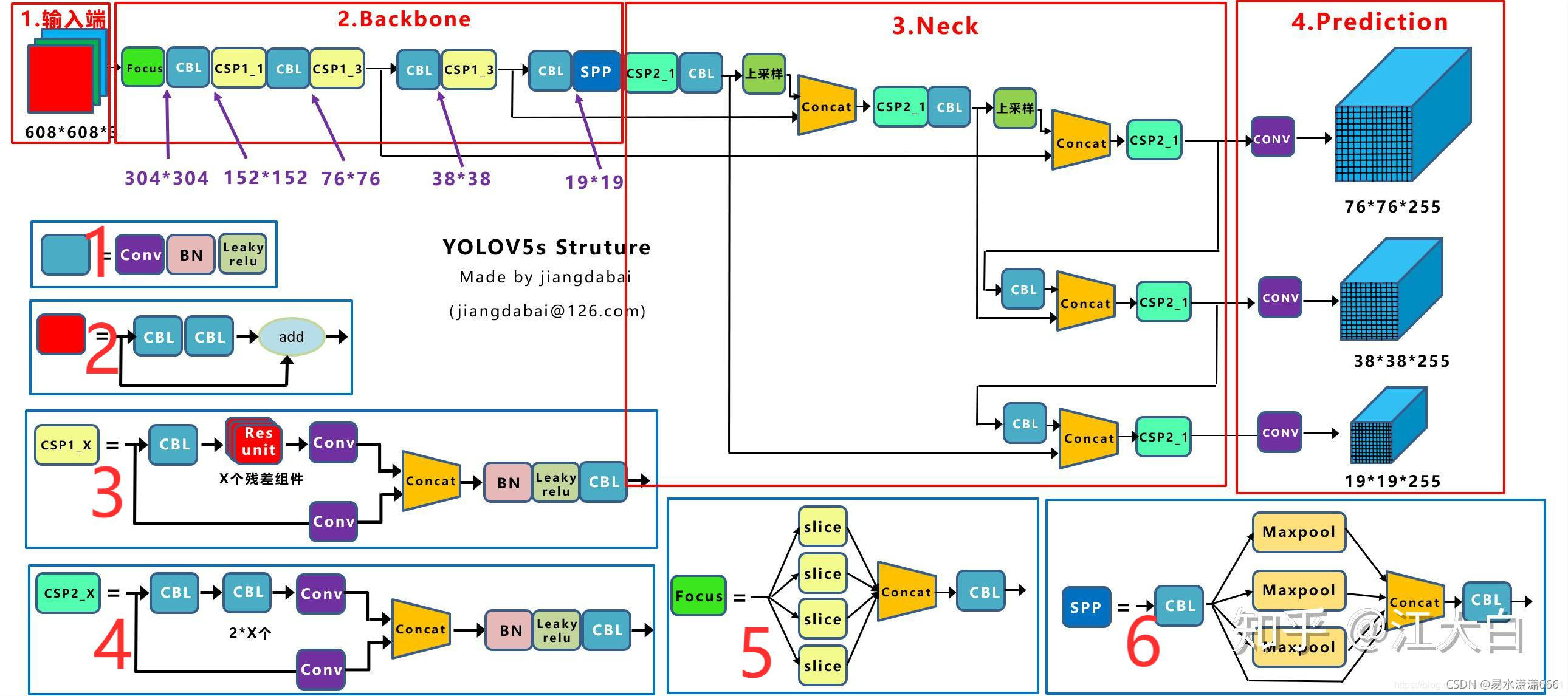 CBL:CBL模块是由Conv+BN+Leaky_relu激活函数组成
CBL:CBL模块是由Conv+BN+Leaky_relu激活函数组成
Res unit:借鉴ResNet中的残差结构,用来构建深层网络,CBM是残差模块中的子模块
CSP1_X:借鉴CSPNet网络结构,由CBL,Res unit,卷积层,Concate组成
CSP2_X:借鉴CSPNet网络结构,由卷积层积X个Res unit模块Concate组成
FOCUS:将多个slice结果Concate起来,将其送入CBL模块中
SPP:采用1x1,5x5,9x9和13x13的最大池化方式,进行多尺度融合
三、Mosaic数据增强
CutMix:将2张图进行拼接
Mosaic:在CutMix基础上进行改进,采用4张图片,按照随机缩放,随机裁剪和随机排布的方式进行拼
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4223
4223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









