






YOLOv4简介
YOLOv4 是一种目标检测算法,属于 YOLO(You Only Look Once)系列的第四代版本。它在目标检测领域有着重要地位,结合了许多先进的技术,在速度和精度上取得了较好的平衡。
- 主要特点
- 高效的检测速度:和传统的目标检测算法相比,YOLOv4 速度极快,能够实时处理视频流,这让它可以在对实时性要求较高的场景中使用,比如自动驾驶、视频监控等。
- 高检测精度:它通过采用一系列先进的技术和改进的网络结构,在目标检测精度上有了显著提升,能够较为准确地识别出图像或视频中的不同目标。
- 多尺度检测:支持多尺度检测,能够检测出不同大小的目标,不管是小目标还是大目标,都能有较好的检测效果。
- 丰富的特征提取:运用了强大的特征提取网络,能够提取出目标的丰富特征,增强了模型对目标的识别能力。
YOLOv4的网络结构
YOLOv4 的网络结构主要由骨干网络(Backbone)、颈部网络(Neck)和检测头(Head)三部分组成。



YOLOv4改进点
Bag of Freebies
“Bag of Freebies” 是机器学习和深度学习领域的一个术语,指的是一系列无需大幅增加模型复杂度或计算资源,就能显著提升模型性能的实用技巧或方法。这些技巧通常被称为 “免费赠品”,因为它们能以较低成本带来效果提升。
-
数据增强

-
Mosaic 数据增强:把四张不同图像进行拼接,形成一张新的训练图像。这样能增加训练数据的多样性,同时提升模型对不同尺度目标的检测能力。

-
CutMix:把一部分图像裁剪下来,贴到另一张图像上,同时调整标签。该方法能够提升模型的鲁棒性。
-
MixUp:将不同图像按一定比例混合,同时混合对应的标签。这种做法能增强模型的泛化能力。

- Self - Adversarial Training(自我对抗训练)是一种在机器学习领域,特别是深度学习中使用的训练技术,它结合了对抗训练的思想,并且模型自身生成对抗样本用于训练。

-
- 网络正则化
- dropout
- Dropout 是一种在深度学习中广泛使用的正则化技术,由 Geoffrey Hinton 等人在 2012 年提出,它能有效防止神经网络过拟合,提升模型的泛化能力。
- 原理
- Dropout 的核心思想是在训练过程中随机 “丢弃”(将神经元输出置为 0)一部分神经元,使得模型不会过度依赖某些特定的神经元,迫使网络学习到更具鲁棒性和泛化性的特征。
- 工作方式
-
训练阶段:在每次前向传播时,每个神经元都有一定概率(通常用p表示,如p = 0.5)被随机丢弃。被丢弃的神经元在本次训练中不参与计算和梯度更新。例如,在一个简单的全连接层中,若有 10 个神经元,以p = 0.5的概率应用 Dropout,那么在某次前向传播中可能会有大约 5 个神经元被丢弃。
-
测试阶段:在测试或推理阶段,通常会关闭 Dropout,或者将所有神经元的输出乘以(1 - p),以保证在训练和测试阶段神经元输出的期望一致。

-
- dropout
- bropblock
- DropBlock 是一种用于卷积神经网络(CNN)的正则化方法,它是对 Dropout 的改进,在处理 CNN 时能取得更好的效果。
- 原理
- 传统的 Dropout 是随机地将单个神经元的输出置为 0,在全连接层中效果较好。但在卷积层中,特征是空间相关的,随机丢弃单个元素对特征图的影响较小,无法有效防止过拟合。DropBlock 则是通过随机丢弃连续的区域(块),从而迫使模型学习到更具鲁棒性的特征。
- 与 Dropout 的对比
- Dropout:随机丢弃单个神经元,在全连接层中能打破神经元之间的共适应关系,但在卷积层中由于特征的空间相关性,效果不佳。
- DropBlock:丢弃连续的区域块,能更有效地破坏卷积层中特征的空间结构,使模型学习到更具泛化性的特征。
- 工作机制
- 定义块大小:确定要丢弃的块的大小,通常用block_size表示。
- 计算丢弃概率:根据设定的概率keep_prob(保留概率),在特征图上随机选择一些区域进行丢弃。
- 更新特征图:将选定区域内的所有元素置为 0。
- 优点
- 提升 CNN 的泛化能力:通过丢弃连续的区域块,能更有效地防止卷积层过拟合,提高模型在测试集上的性能。
- 简单易实现:可以很方便地集成到现有的 CNN 模型中。
- 缺点
- 超参数调整复杂:需要调整块大小block_size和保留概率keep_prob等超参数,不同的任务和数据集可能需要不同的参数组合。
- 计算开销增加:相比于 Dropout,DropBlock 在计算 mask 时会增加一定的计算开销

- 标签平滑

- 损失函数改进
- IOU损失

- GIOU
- GIOU(Generalized Intersection over Union)即广义交并比,是在目标检测领域中用于衡量预测框和真实框之间相似度的指标,是对 IoU(Intersection over Union)的扩展和改进。
- 定义

- 与 IoU 的对比

- 作用

- IOU损失

- DIOU
- DIOU(Distance - Intersection over Union)即距离交并比,是目标检测领域中用于衡量预测框和真实框之间相似度的指标,是对 IoU 和 GIOU 的进一步改进。
- 定义

- 与 IoU 和 GIOU 的对比
- IoU:只关注预测框和真实框的重叠部分,当两个框不重叠时,IoU 为 0,无法反映框之间的距离和相对位置关系,且在这种情况下梯度为 0,不利于模型训练。
- GIOU:引入了最小封闭凸区域,解决了 IoU 在框不重叠时的问题,但在一些情况下,GIOU 收敛速度较慢,因为它主要关注的是框的外包区域,对于框的中心点距离考虑不足。
- DIOU:直接考虑了预测框和真实框中心点之间的距离,能够更快地引导模型将预测框的中心点移动到真实框的中心点附近,收敛速度更快,定位精度更高。
- 作用


- CIOU
- CIOU(Complete - Intersection over Union)即完整交并比,是目标检测领域中用于衡量预测框和真实框之间相似度的指标,它是对 DIOU 的进一步改进。
- 定义

- 与其他指标的对比
- IoU:仅考虑了预测框和真实框的重叠部分,当两个框不重叠时,IoU 为 0,无法反映框之间的距离和相对位置关系,且在这种情况下梯度为 0,不利于模型训练。
- GIOU:引入了最小封闭凸区域,解决了 IoU 在框不重叠时的问题,但在一些情况下收敛速度较慢,因为它主要关注的是框的外包区域,对框的中心点距离和长宽比考虑不足。
- DIOU:考虑了预测框和真实框中心点之间的距离,收敛速度比 GIOU 快,但没有考虑框的长宽比一致性。
- CIOU:综合考虑了重叠面积、中心点距离和长宽比,在目标检测的定位精度上表现更优。
- 作用


- 非极大值抑制的改进


- 网络模型的改进

- spp-net网络

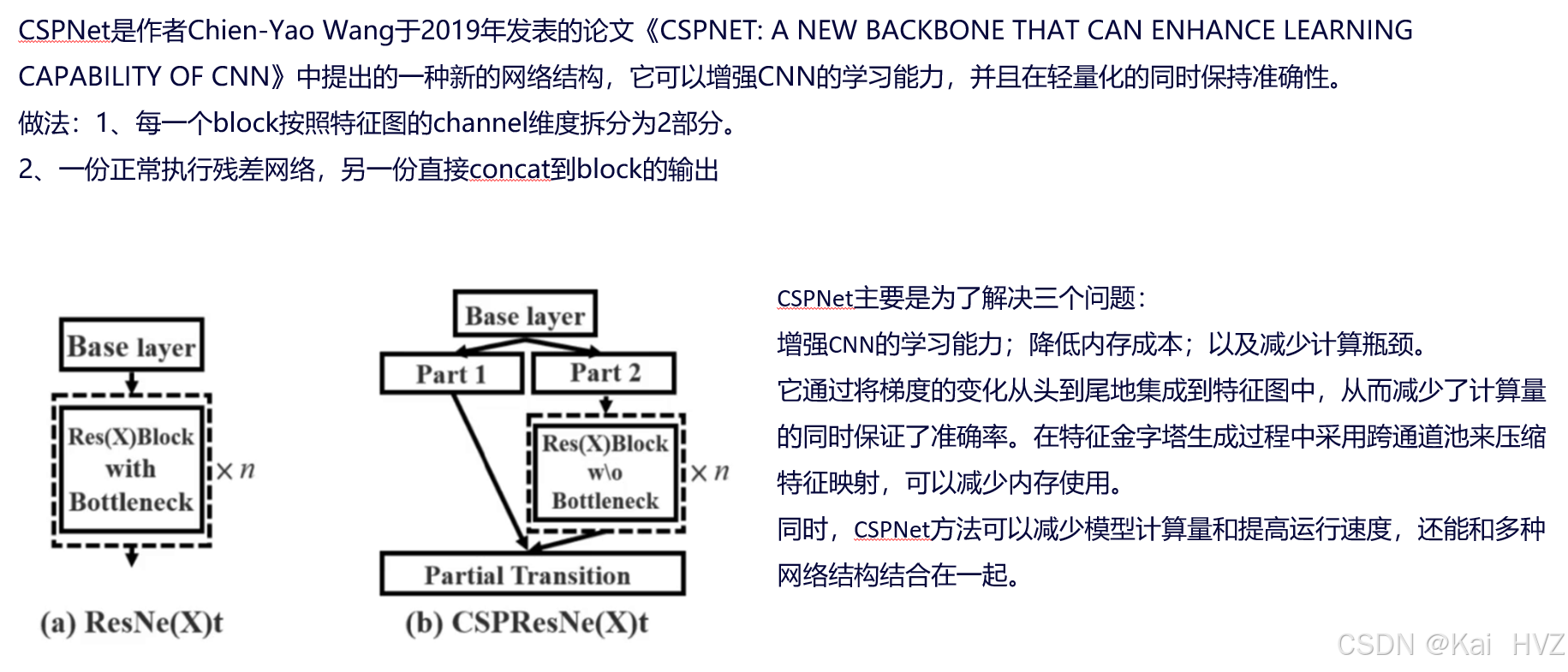
- CSP-Net网络
- 注意力机制
Spatial attention module(空间注意力模块)是深度学习中用于增强模型对输入数据空间位置敏感能力的关键组件。它通过动态调整不同空间区域的权重,使模型更关注重要区域,从而提升视觉任务的性能。

- PNA



- spp-net网络
- 激活函数
- mish激活函数
- Mish 是一种新型的激活函数,在深度学习领域有着重要的应用。


- mish激活函数
- 网格


















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









