






 本文详细介绍了卷积神经网络(CNN)的基础知识,包括卷积核、padding和stride的概念,以及防止过拟合的方法如dropout和归一化。还讨论了激活函数的作用,如sigmoid、tanh和relu,并介绍了pooling、全连接层、参数初始化策略,如Xavier和He初始化。此外,文章还涵盖了学习率的调整策略、优化器的选择,如SGD和Adam,并提及了抗噪声处理的优化方法。
本文详细介绍了卷积神经网络(CNN)的基础知识,包括卷积核、padding和stride的概念,以及防止过拟合的方法如dropout和归一化。还讨论了激活函数的作用,如sigmoid、tanh和relu,并介绍了pooling、全连接层、参数初始化策略,如Xavier和He初始化。此外,文章还涵盖了学习率的调整策略、优化器的选择,如SGD和Adam,并提及了抗噪声处理的优化方法。
https://cs231n.github.io/assets/conv-demo/index.html
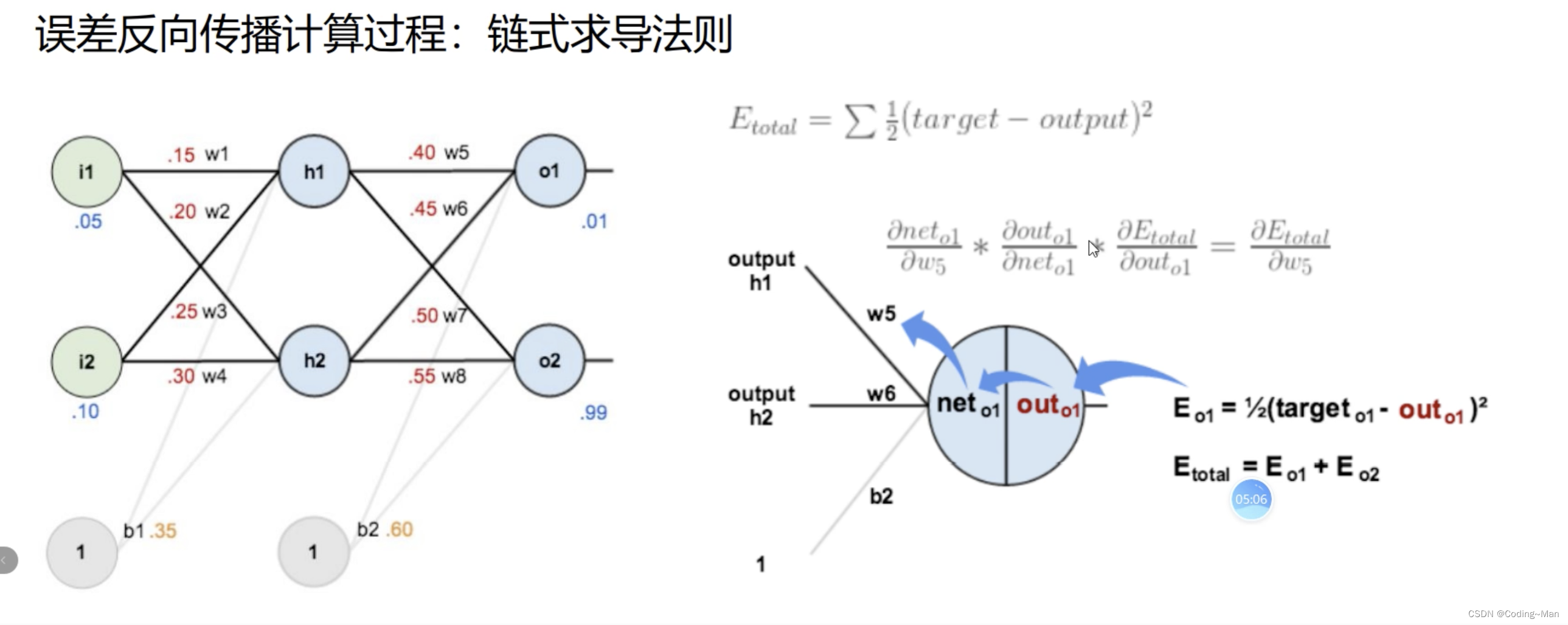
网络模型训练三剑客:归一化,dropout,以及激活函数。
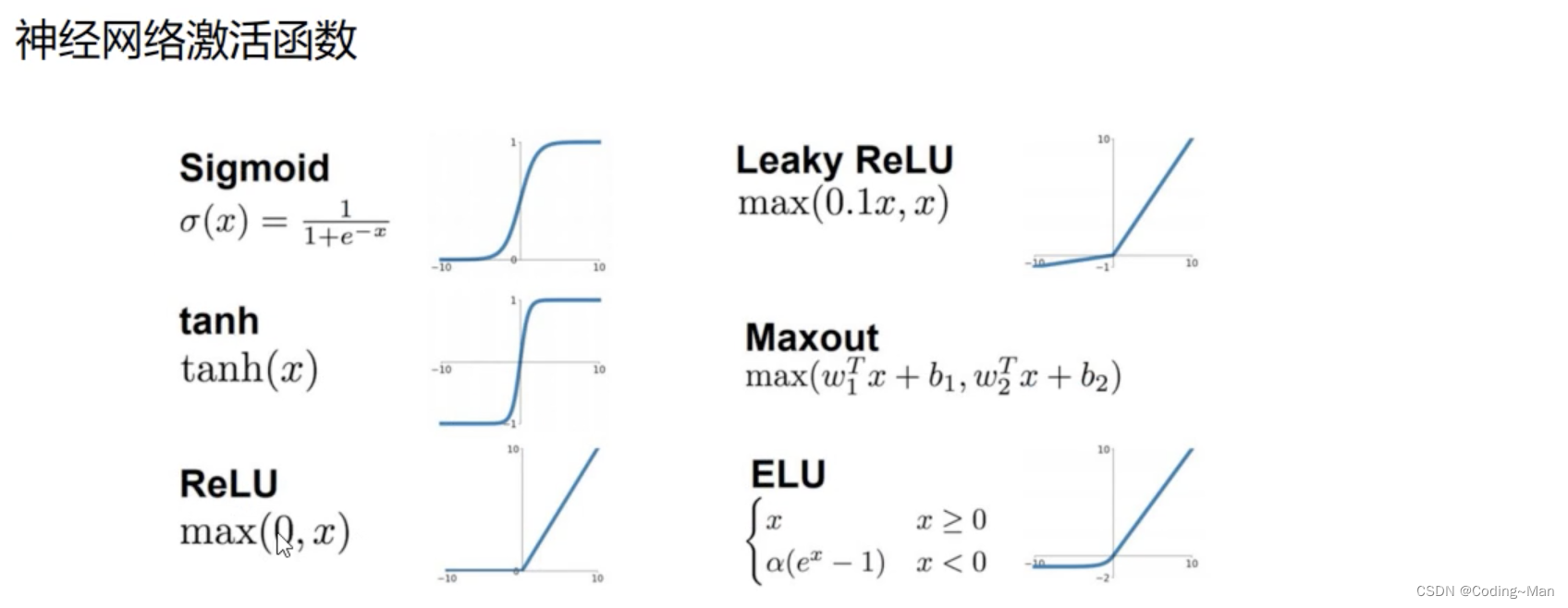
1:神经网络常见激活函数
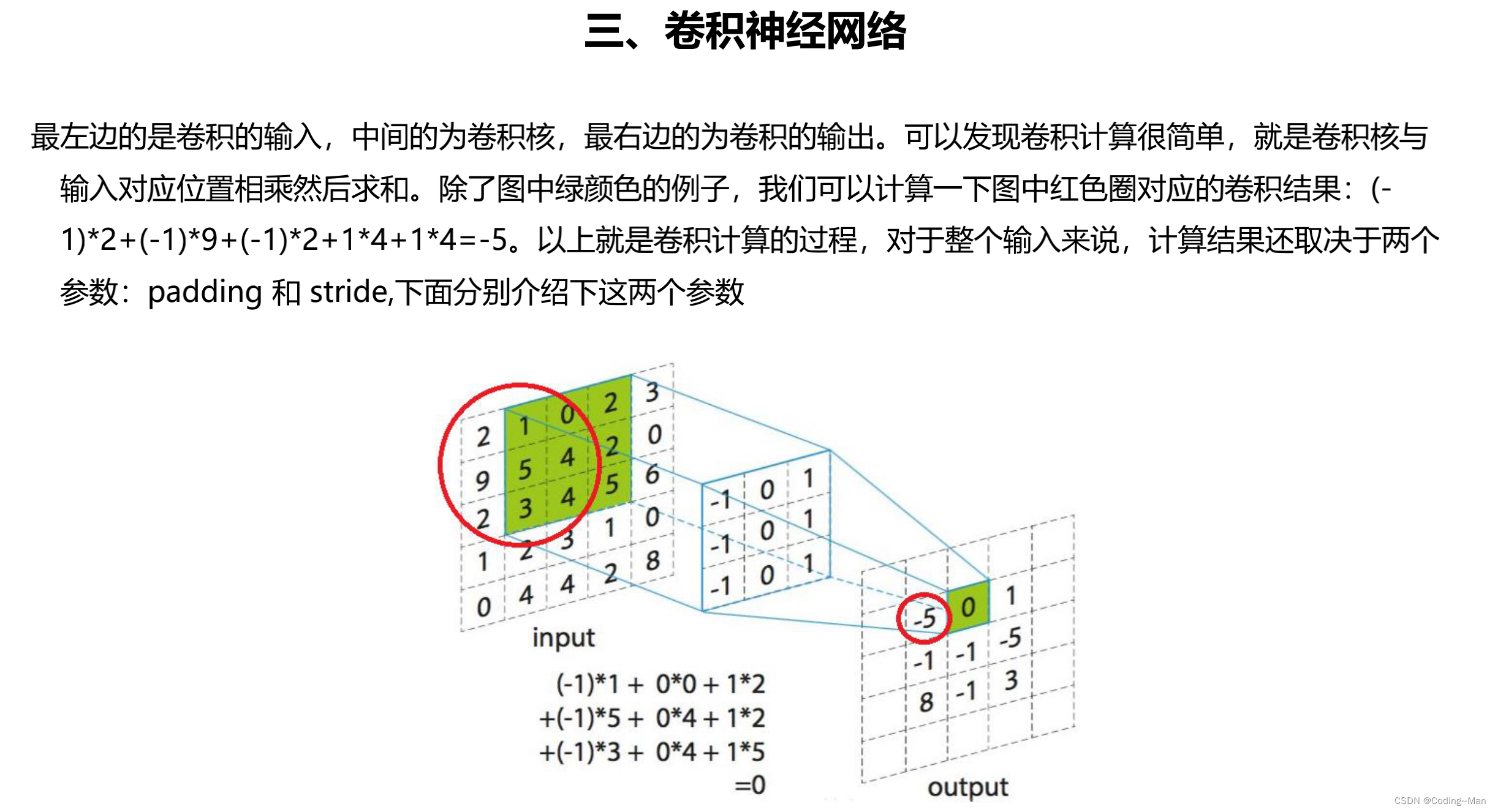
2: 卷积神经网络
卷积核,padding,和stride步长。
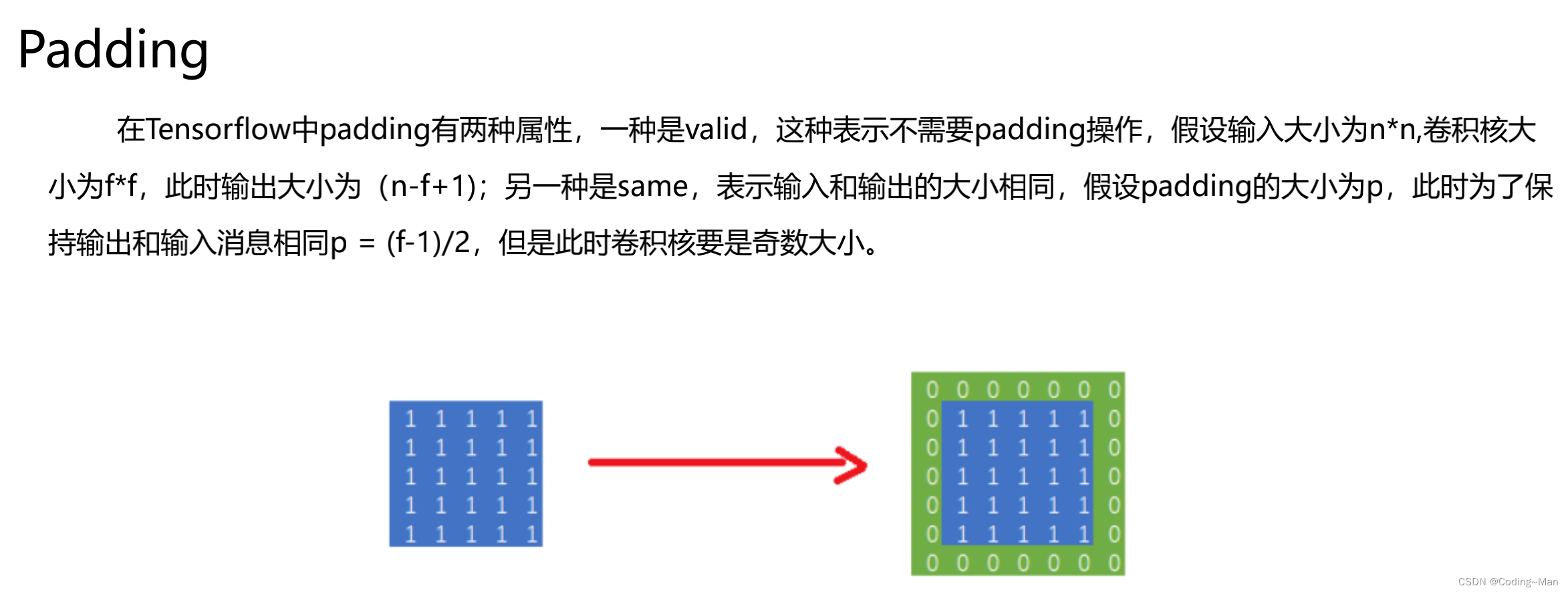
Padding的作用,为了保证输入输出矩阵的形状不变。
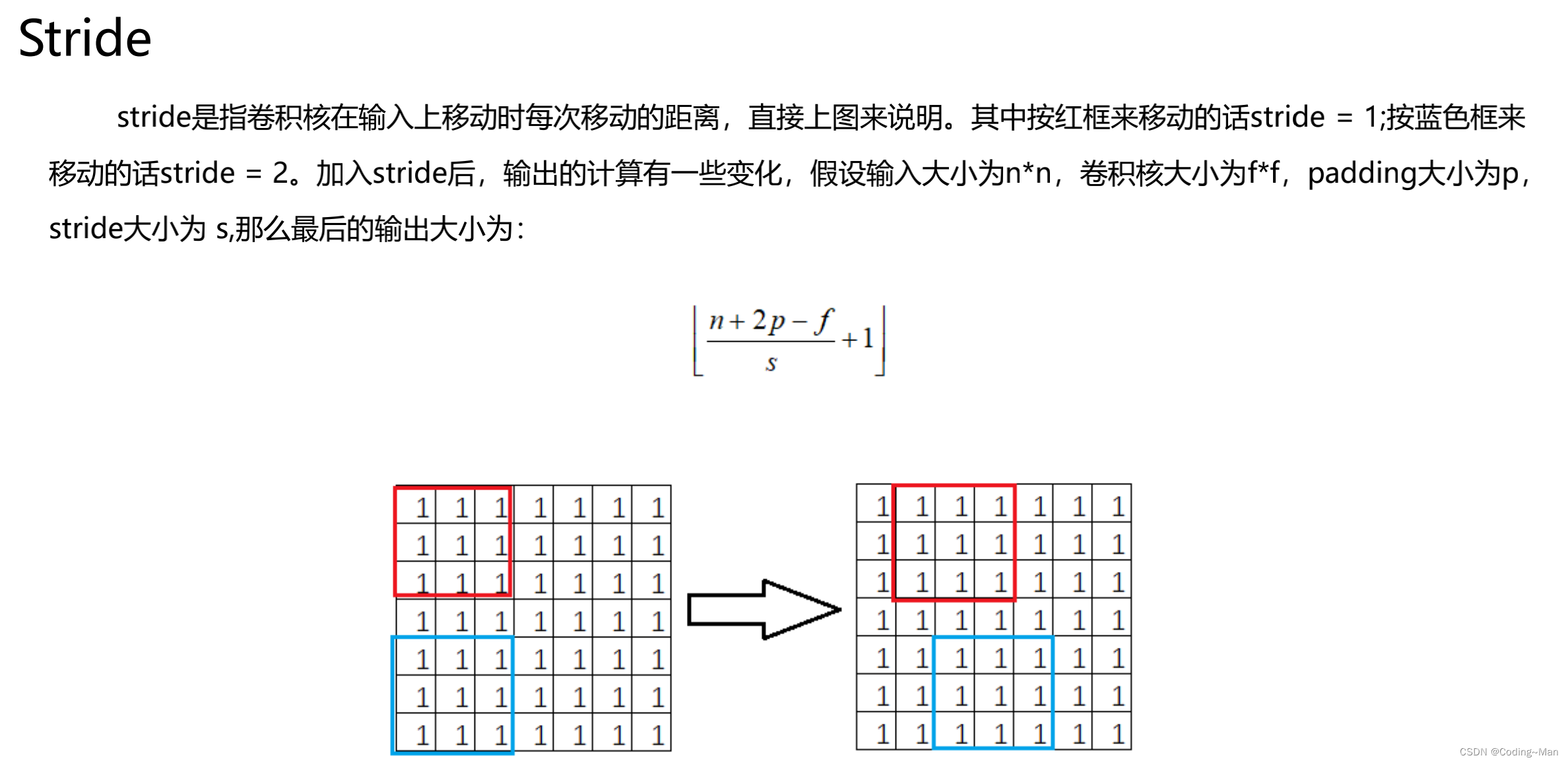
Stride是步长。
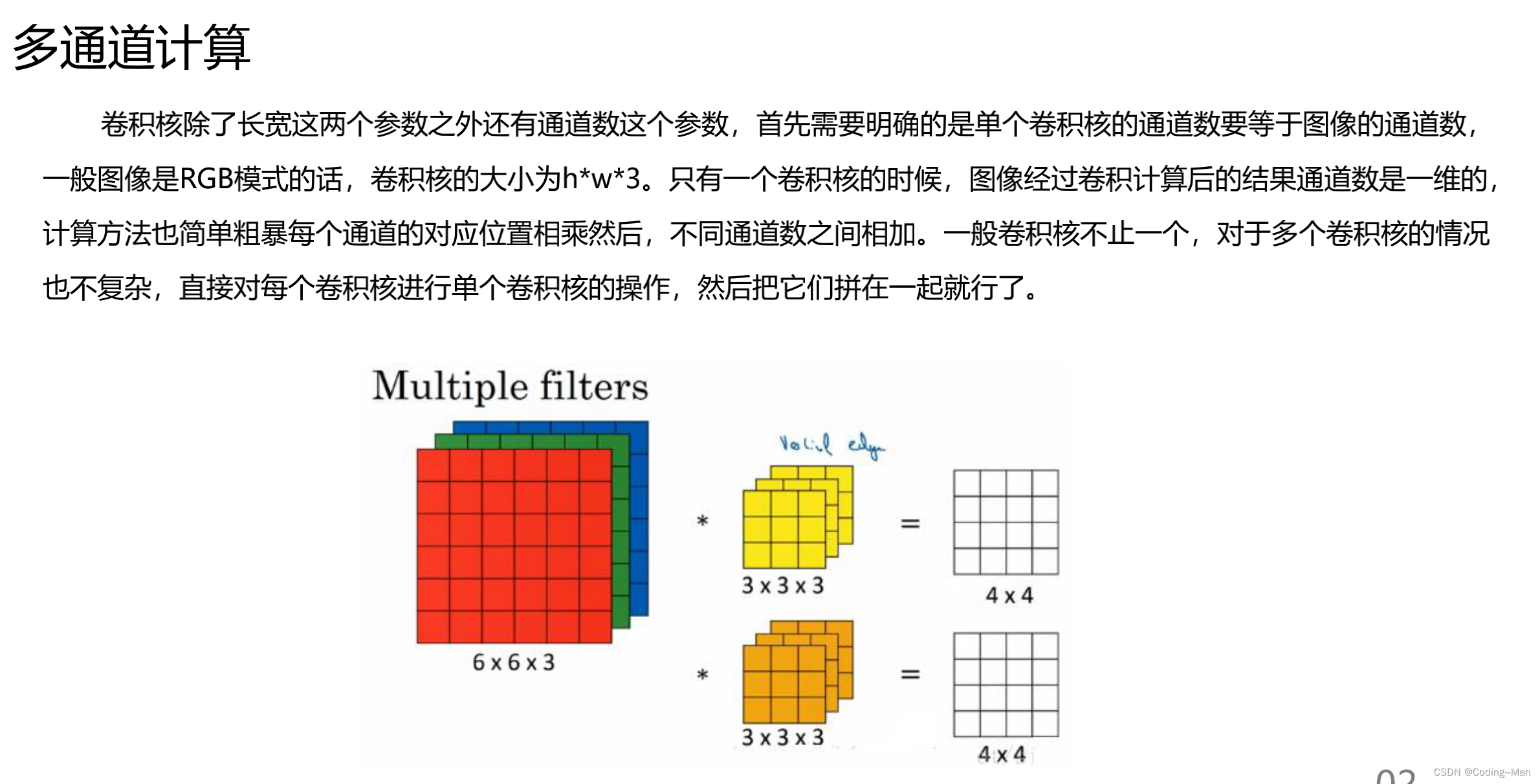
多通道卷积:
3: 防止过拟合的方法
1:DropOut随机将节点的输出变成0。
2:DropConnect随机

https://cs231n.github.io/assets/conv-demo/index.html
网络模型训练三剑客:归一化,dropout,以及激活函数。
1:神经网络常见激活函数
2: 卷积神经网络
卷积核,padding,和stride步长。
Padding的作用,为了保证输入输出矩阵的形状不变。
Stride是步长。
多通道卷积:
3: 防止过拟合的方法
1:DropOut随机将节点的输出变成0。
2:DropConnect随机

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1272
1272





