









可见性
常见现象
main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
分析:
【从Java内存模型的角度出发进行分析,Java内存模型就是把Java内存划分为主存和工作内存,主存就是所有共享信息存储的位置,工作内存就是每个线程私有的信息存储位置】
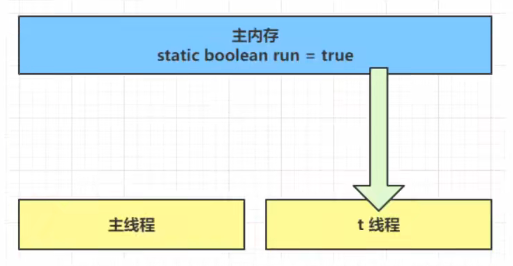
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
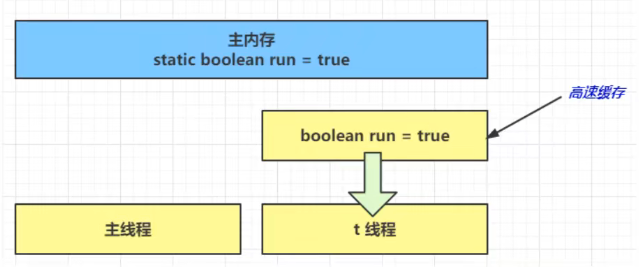
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中, 减少对主存中 run 的访问,提高效率
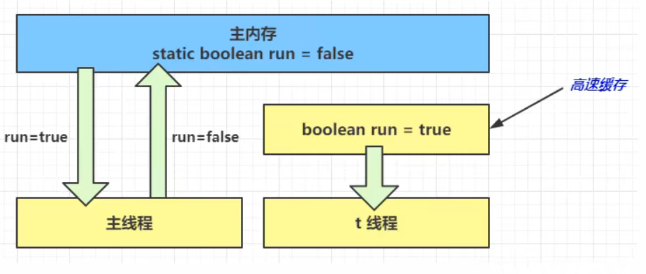
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 线程是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
解决办法
- volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
修改后:volatile static boolean run = true;
- synchronized
修改后:
static boolean run = true;
final static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
synchronized(lock){
if(!run){
break;
}
}
}
});
t.start();
sleep(1);
synchronized(lock){
run = false;
}
}
synchronized 和 volatile 都能保证共享变量的可见性,但是synchronized 会创建monitor,属于重量级的操作,volatile更轻量
可见性 vs 原子性
上述例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可见,不能保证原子性,仅用在一个写线程,多个读线程的情况
上例从字节码理解是这样的:
getstatic run // 线程 t 获取 run true
getstatic run // 线程 t 获取 run true
getstatic run // 线程 t 获取 run true
getstatic run // 线程 t 获取 run true
putstatic run // 线程 main 修改 run 为 false, 仅此一次
getstatic run // 线程 t 获取 run false
比较一下:两个线程一个 i++ 一个 i-- ,对同一个共享变量做修改,此时能用volatile 吗?不行,因为 volatile 只能保证看到最新值,不能解决指令交错的问题。i++ ,i–底层对应4条指令,这4条指令可能会发现交错,volatile只能保证再 getstatic 时读到最新的值
i++,i–指令交错时,下述最终结果为-1
// 假设i的初始值为0
getstatic i // 线程2-获取静态变量i的值 线程内i=0
getstatic i // 线程1-获取静态变量i的值 线程内i=0
iconst_1 // 线程1-准备常量1
iadd // 线程1-自增 线程内i=1
putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=1
iconst_1 // 线程2-准备常量1
isub // 线程2-自减 线程内i=-1
putstatic i // 线程2-将修改后的值存入静态变量i 静态变量i=-1
synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是 synchronized 是属于重量级操作,性能相对更低
有序性
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序
static int i;
static int j;
// 在某个线程内执行如下赋值操作
i = ...;
j = ...;
可以看到,至于是先执行 i 还是 先执行 j ,对最终的结果不会产生影响。所以,上面代码真正执行时,既可以是
i = ...;
j = ...;
也可以是
j = ...;
i = ...;
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。
为什么要有重排指令这项优化呢?
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理器,就可以称之为五级指令流水线。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了 指令地吞吐率。(这是CPU层面,Java层面的指令重排序优化是一样的道理)
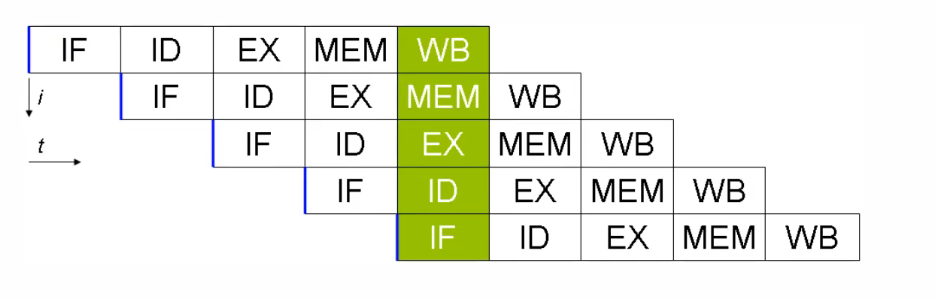
在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行,这一技术在 80’s 中 叶到 90’s 中叶占据了计算架构的重要地位
另外,Java指令重排的前提是,重排指令不能影响结果,例如
// 可以重排的例子
int a = 10; // 指令1
int b = 20; // 指令2
System.out.println( a + b );
// 不能重排的例子
int a = 10; // 指令1
int b = a - 5; // 指令2
常见场景
多线程下『指令重排』导致影响结果正确性
int num = 0;
boolean ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
I_Result 是一个对象,有一个属性 r1 用来保存结果,问,可能的结果有几种?
答案:1、4、和0
分析:
- 情况1:线程1 先执行,这时 ready = false,所以进入 else 分支结果为 1
- 情况2:线程2 先执行 num = 2,但没来得及执行 ready = true,线程1 执行,还是进入 else 分支,结果为1
- 情况3:线程2 执行到 ready = true,线程1 执行,这回进入 if 分支,结果为 4(因为 num 已经执行过了)
- 情况4:线程2 执行 ready = true,切换到线程1,进入 if 分支,相加为 0,再切回线程2 执行 num = 2
这种现象叫做指令重排,是 JIT 编译器在运行时的一些优化,这个现象需要通过大量测试才能复现结果为0的情况
解决办法
volatile 修饰的变量,可以禁用指令重排
修改后:
int num = 0;
volatile boolean ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
在 ready 上加 volatile 会防止在它之前的代码被指令重排序,所以 num 不用加,加一个就行



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









