






万般的努力只为出人头地,低头弯腰只为爬的更高。
终有一日:会当凌绝顶,一览众山小。
低级的欲望放纵即可获得,高级的欲望克制才能达到。
一本男儿行四方,何惧世俗历沧桑。
莫愁前路无知己,天下谁人不识君。
无人扶我青云志,我自踏雪至山巅。
若是命中无此运,亦可孤身登昆仑。

css解析数据的模板
import parsel
import requests
response = requests.get(url=url,headers=headers)
# 实例化selector对象,注意parsel后面的Selector首字母大写
selector = parsel.Selector(response.text)
content = selector.css('css语法')
css格式总结
. 代表class
# 代表id
::text 表示输出文本(即尖括号里面的内容)
nth-child(page) 表示匹配第page项
举例说明
- div 返回的是全部的div标签
- div.content 返回的是class="content"的整个div标签
- div.content #su 返回的是class='content'的整个div标签下id='su'的标签
- div.content li 返回的是class='content'的整个div标签下的li标签
- div.content li:nth-child(1) 返回的是class='content'的整个div标签下的li标签中的第一个li标签
- div.content li:nth-child(1)::text 返回的是class='content'的整个div标签下的li标签中的第一个li标签中的文本数据
- div.content li:nth-child(1)::attr(href) 返回的是class='content'的整个div标签下的li标签中的第一个li标签,其中href是所对应的属性值
- selector.css('css样式').get() 获取第一个匹配的
- selector.css('css样式').getall() 获取多个匹配的
Demo展示
在开发者工具中论证,定位要爬取的数据,在element中ctrl+f查找
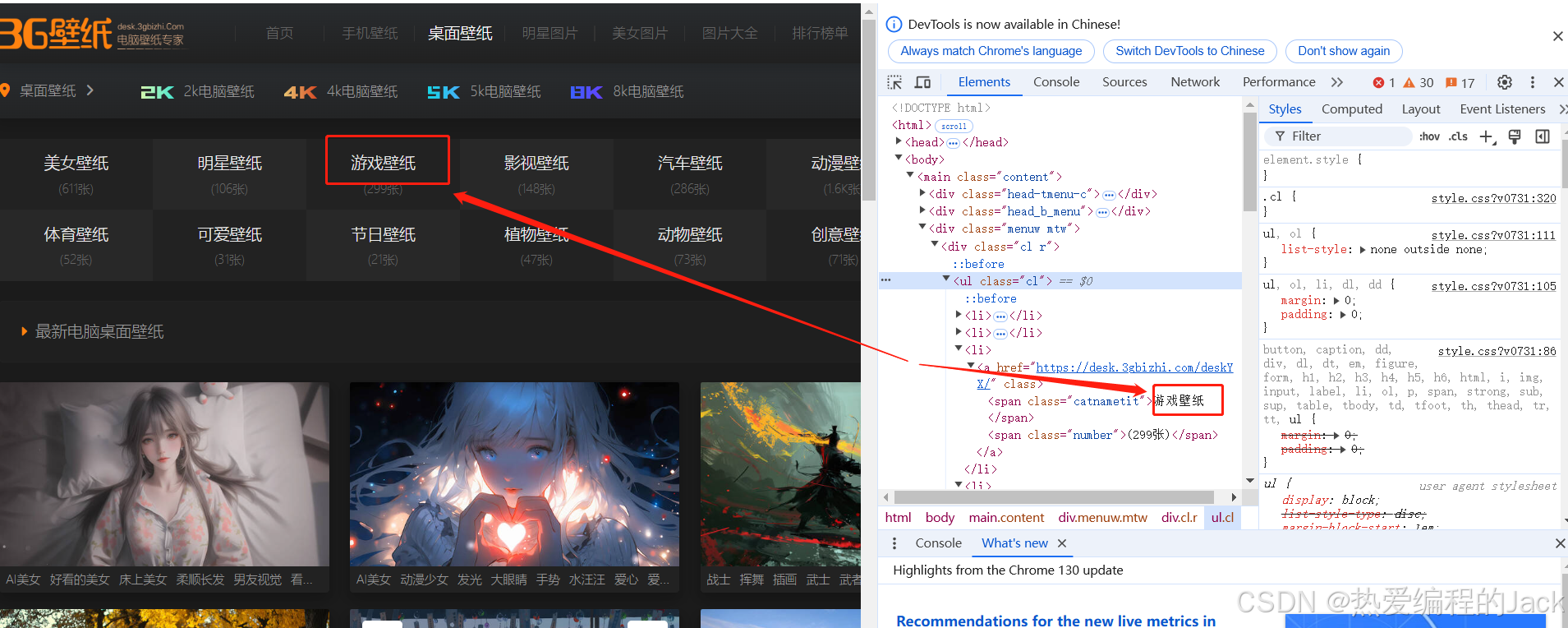
- 你比如说:爬取壁纸的名称(游戏壁纸)
'''
Author: Jack
Time: 2024/11/12 下午8:24
'''
import requests
import parsel
url = "https://desk.3gbizhi.com/"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
selector = parsel.Selector(response.text)
name = selector.css('.cl li:nth-child(3) a span.catnametit::text').get()
print(name)
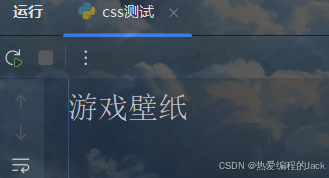
学废了的童鞋可以动手尝试一下,怎么获取别的名字,甚至是别的元素都可以。旨在学废!!!
注意:若是出现乱码,则可以添加一下代码
# 自动识别乱码,并纠正
response.encoding = response.apparent_encoding注意:编写css时,要像剥洋葱一样,一层一层拨开你的心,不能跳的太多,否则会出错!!!

















 4470
4470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









