







文章目录
speech2speech
- 端到端集成之后的大脑思考能力
- 多口音/方言输入的理解(speech 数据)
- 生成的精细控制(情感,副语言)
评测工具
step-audio360
- 137条数据
- 评测数据集:覆盖singing, creativity, role-playing, logical reasoning, voice understanding(包括唤醒), voice instruction following, gaming, speech emotion control, and language ability
EmergentTTS-Eval
step-audio2 [2025.6]
abstract
- 增强副语言的理解能力;和step-audio相比模型size 更小,引入CoT和RL 改进效果,引入RAG改善幻觉问题
- 6800 亿个 token 的文本数据和 800 万小时的真实和合成音频数据上训练
- 补充了 speech2speech translation的任务;
related work
Step-audio [2025.2]
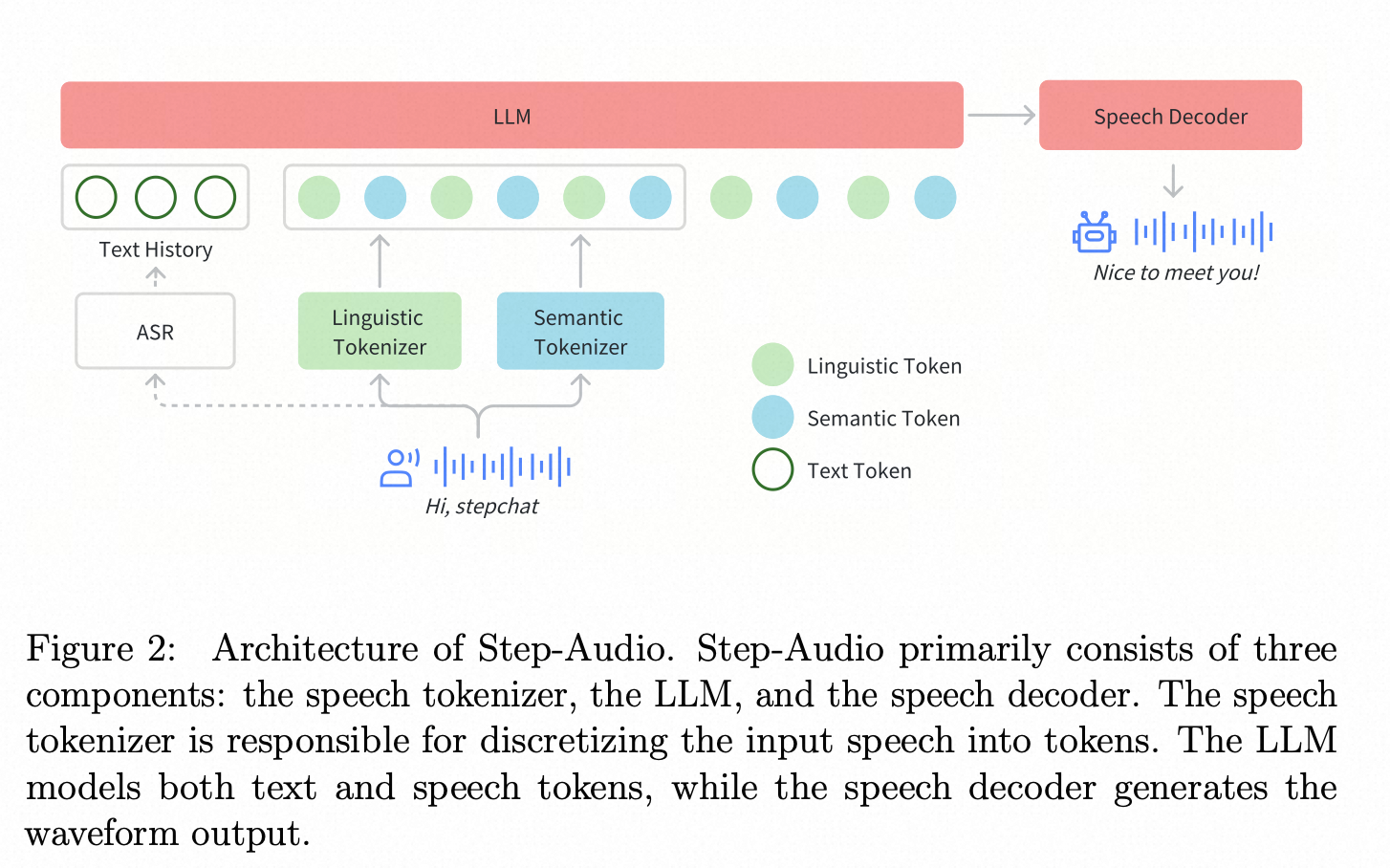
abstract
- 训练130B的模型
- model_arch : 用130B的模型,生成数据,用于3B 模型的蒸馏训练,小模型具有很强的指令跟随能力;
- 模型能力:
- 指令控制:情感,方言(粤语,四川话),(RAP/Singing、无伴奏合唱)
- 增强智能:agent 配合
- 两种音频token
- parallel linguistic (16.7Hz, 1024-codebook): 音素和语言特征,Paraformer encoder + VQ
- semantic (25Hz, 4096-codebook) :语义和粗粒的声学特征。cosyvoice2 25hz token
related work
- Llama-Omni
- Freeze-Omni
- MinMo
- Moshi
- GLM4-Voice
- LUCY 基于mini-omini 的架构,针对LLM 输出冗长的回复,不适配对话场景进行优化
method
架构:AQTA(音频输入、文本输出)+ TTS 框架
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1822
1822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









