




 DHSNet是一种端到端的深层次显著性检测网络,它能够从全局视角到局部内容,分层次地检测目标,从粗到细探索所有显著性线索,有效保存目标细节。模型由GV-CNN和HRCNN组成,前者捕捉全局结构显著性,后者融合局部上下文,通过递归卷积层逐步优化显著图。
DHSNet是一种端到端的深层次显著性检测网络,它能够从全局视角到局部内容,分层次地检测目标,从粗到细探索所有显著性线索,有效保存目标细节。模型由GV-CNN和HRCNN组成,前者捕捉全局结构显著性,后者融合局部上下文,通过递归卷积层逐步优化显著图。
DHSNet重要总结
1. 主要贡献
作者提出一个端到端的深层次显著性网络DHSNet,DHSNet把整个图片当作是输入,直接输出显著性图,DHSNet分层次地从全局视角到局部内容检测目标,从粗略的尺寸细化到细微的尺寸,探索潜在的所有显著性线索,并有效保存目标细节。
2. 模型介绍
1.简述
DHSNet由GV-CNN(在DHSNet中,前半部分实质是去掉了VGG16的最后一个池化层得到尺寸为[512, 28, 28]的Feature Map)和HRCNN两部分组成。GV-CNN网络可学习各种全局的结构显著性线索,HRCNN可融合局部的上下文内容,分层的渐进的调整显著图的细节,总体地说DHSNet是使用分层递进的优化整合的策略来学习从全局视角到局部内容。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J5a4tdmV-1586158146022)(https://s1.ax1x.com/2020/04/06/GsDJ3j.png)]
GV-CNN包含13层卷积层,4层池化层,一个全连接层和一个重塑层。对于大小为224x224的输入图像,通过卷积层提取深度特征,最后一个卷积层的大小为1214512,使用sigmiod激活函数的全连接层的输出结点为784个,然后重塑层使其大小变为28*28。
HRCNN由4层递归卷积层和4层下采样层组成。RCL通过下采样得到的较粗略的显著图与经过GV-CNN得到的较精细地显著图进行融合,来生成一个较精细的显著图,经过RCL的递归和逐步细化,一次一次为下一步
由几个递归卷积层(recurrent convolutional layers,RCL)和几个下采样层组成。其中,递归卷积层RCL将递归链接并入每一卷积层中,从而增强了模型如何上下文信息的能力
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dfaH09SE-1586158146026)(https://s1.ax1x.com/2020/04/06/GsDYgs.png)]
2.细节
RCL网络中,第k个特征图中坐标为(i,j)的单元,在时间t时的值为:
xijk(t)=g(f(zijk(t)))x_{i j k}(t)=g\left(f\left(z_{i j k}(t)\right)\right)xijk(t)=g(f(zijk(t)))
f为整流线性激活函数Relu,g为本地响应归一化函数LRN,LRN用于防止出现梯度爆炸,可得:
g(fijk(t))=fijk(t)(1+αN∑k′=max(0,k−N/2)min(K,k+N/2)(fijk′)2)βg\left(f_{i j k}(t)\right)=\frac{f_{i j k}(t)}{\left(1+\frac{\alpha}{N} \sum_{k^{\prime}=\max (0, k-N / 2)}^{\min (K, k+N / 2)}\left(f_{i j k^{\prime}}\right)^{2}\right)^{\beta}}g(fijk(t))=(1+Nα∑k′=max(0,k−N/2)min(K,k+N/2)(fijk′)2)βfijk(t)
zijk(t)z_{i j k}(t)zijk(t)融合一个前馈连接和
u(i,j)\mathbf{u}^{(i, j)}u(i,j)和x(i,j)(t−1)\mathbf { x } ^ { ( i , j ) } ( t - 1 )x(i,j)(t−1)是上一层RCL的正反馈,wkf\mathbf { w } _ { k } ^ { f }wkf和wkr\mathbf { w } _ { k } ^ { r
}wkr是前馈网络的参数和上一层RCL的参数。
zijk(t)=(wkf)Tu(i,j)+(wkr)Tx(i,j)(t−1)+bkz_{i j k}(t)=\left(\mathbf{w}_{k}^{f}\right)^{T} \mathbf{u}^{(i, j)}+\left(\mathbf{w}_{k}^{r}\right)^{T} \mathbf{x}^{(i, j)}(t-1)+b_{k}zijk(t)=(wkf)Tu(i,j)+(wkr)Tx(i,j)(t−1)+bk
3. 性能
模型质量对比图:
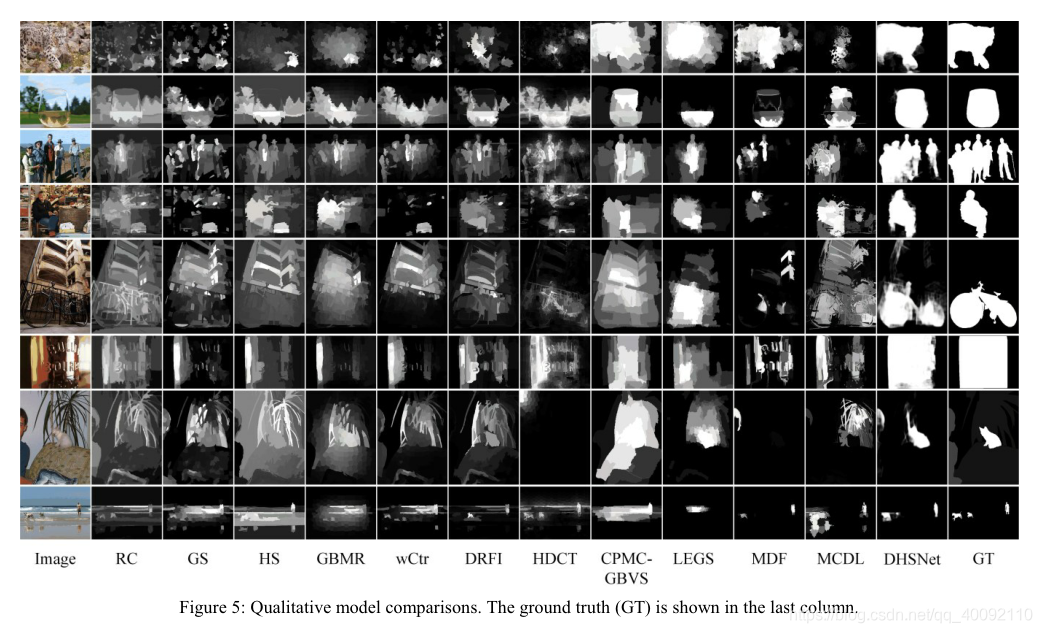
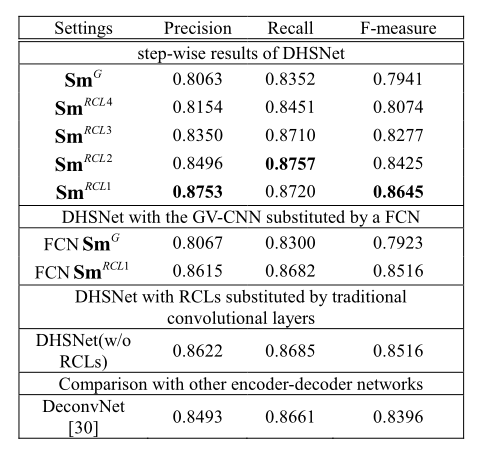
模型简化测试图:
- 模型质量比RC , GS , HS , GBMR,DRFI , wCtr , HDCT , CPMC-GBVS , LEGS , MDF和MCDL性能都要好。
- 证明GV-CNN的有效性,实验使用GV-CNN+RCL的组合比使用FCN+RCL的F-measure提升0.129,原因可能是FCN的误判被RCL放大了。
- 证明RCL的有效性,实验使用GV-CNN+RCL和GV-CNN+传统卷积层性能的F-measure提升0.129。

















 2737
2737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









