




使用多种机器学习调参模型进行二分类建模的全流程教程
机器学习全流程分析各个模块用到的总的参数文件
0. 分析参数文件
参数文件名称:total_analysis_params_demo.xlsx ,很多分析模块都是这个总的参数文件,我的这个总的参数文件如果有更新的话,我就上传到百度网盘。包括机器学习建模和可视化的所有分析模块都是用的这一个参数文件
从百度网盘下载该参数文件,该参数文件在百度网盘的位置:
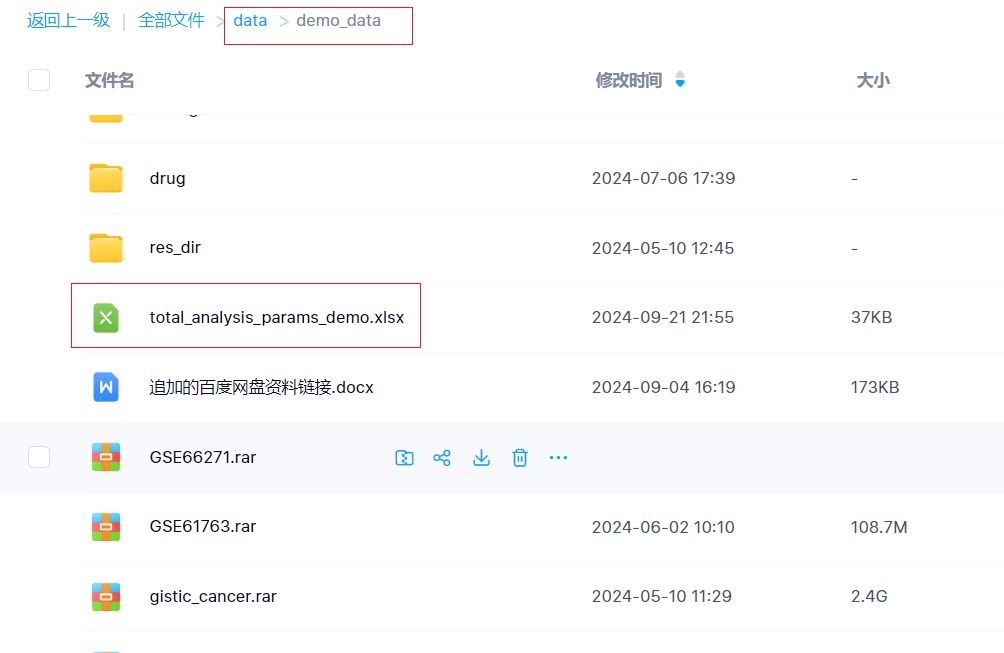
我们可以把这个参数文件下载到本地的:D:/omics_tools/demo_data这个目录下。下载后,在本地的文件为:
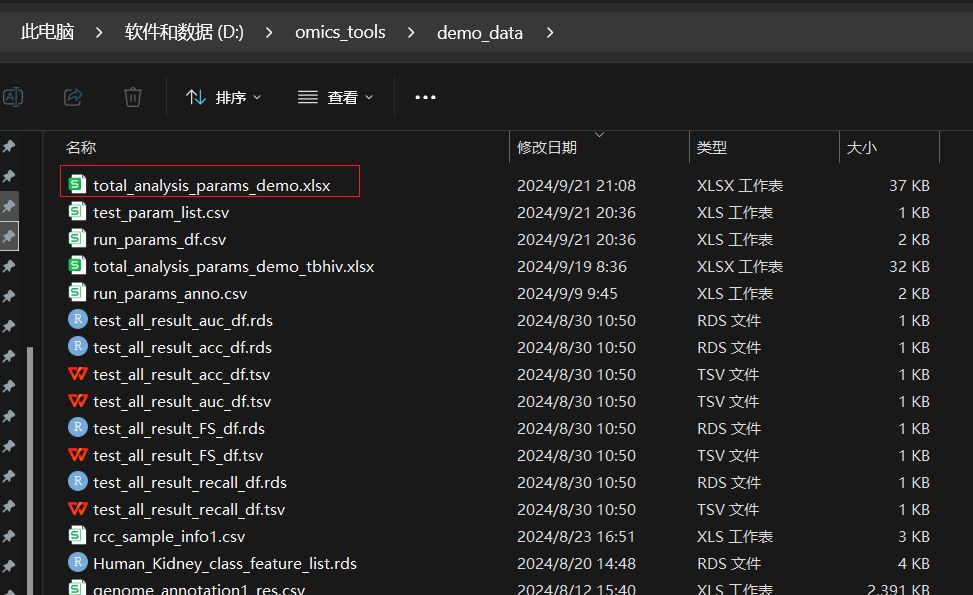
机器学习建模和可视化所有模块都用的这个总的参数文件的完整的文件路径就是:D:/omics_tools/demo_data/total_analysis_params_demo.xlsx
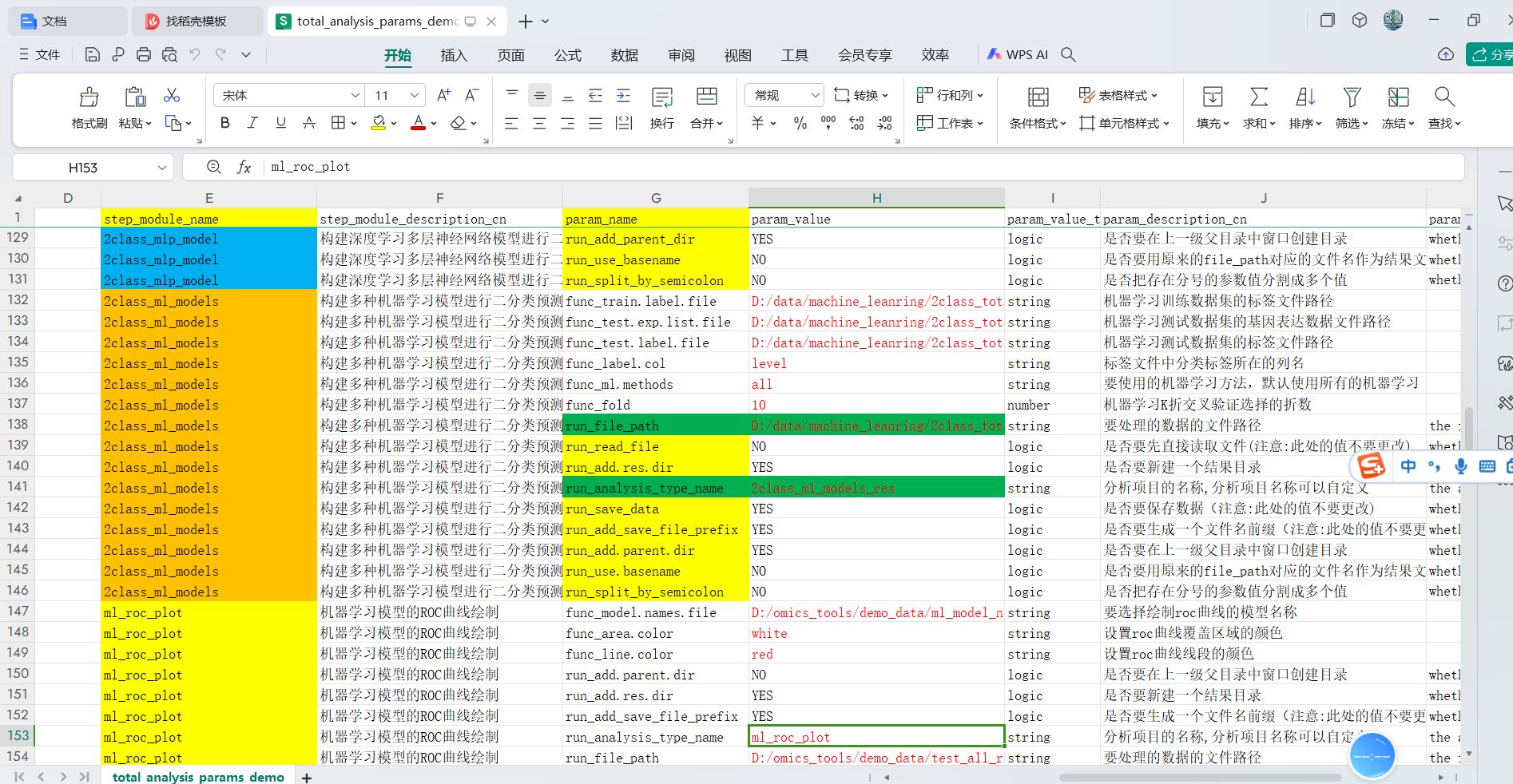
修改参数值的时候,只用改这个模块的参数值中我标红的那几个参数值,包括大家电脑中要分析的数据的文件路径和一些要调整和特别指定的重要参数值,没有标红的参数值,大家一律用默认的,不用修改。
机器学习的数据预处理和建模
对要进行机器学习或深度学习的数据进行整理和预处理
分析模块位置
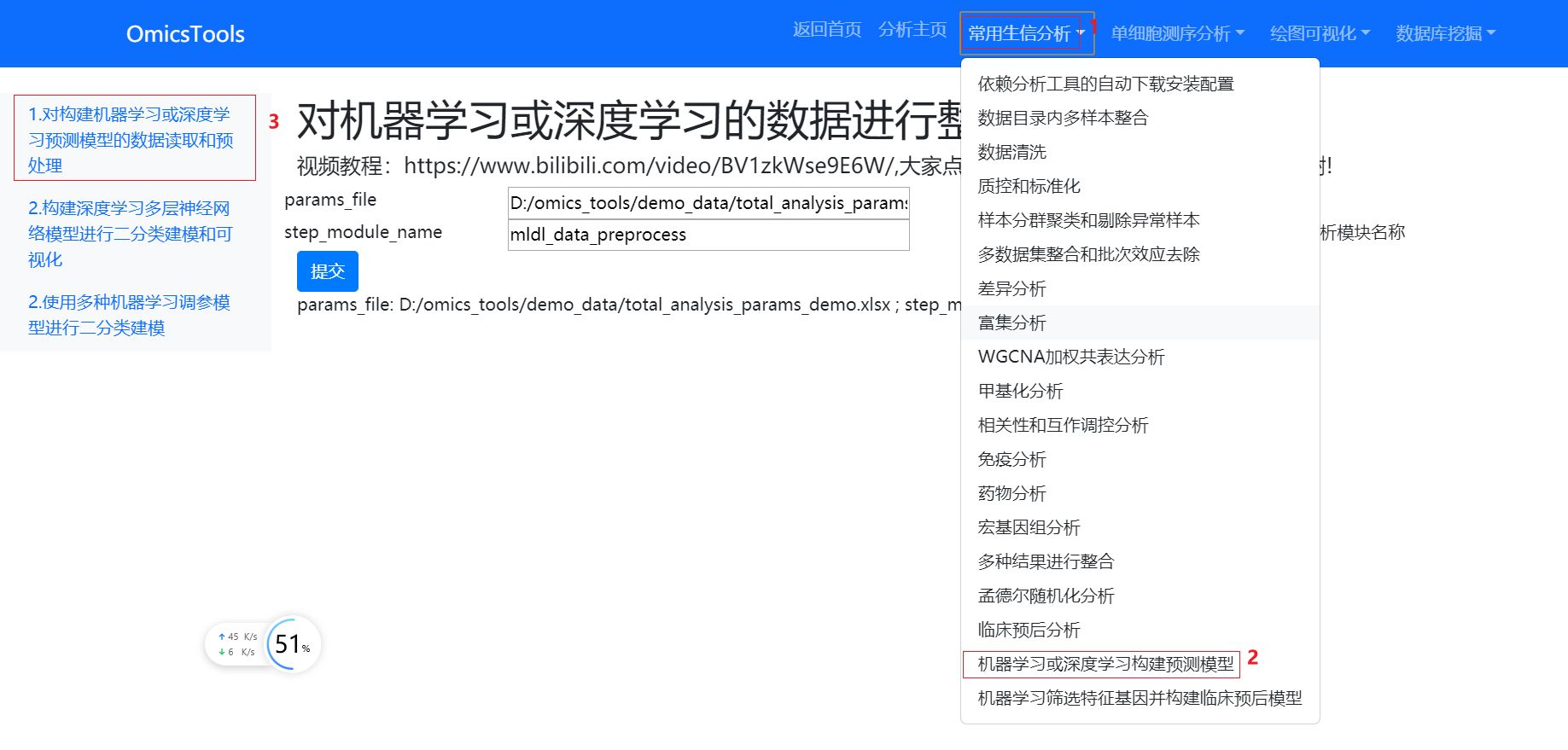
分析模块界面
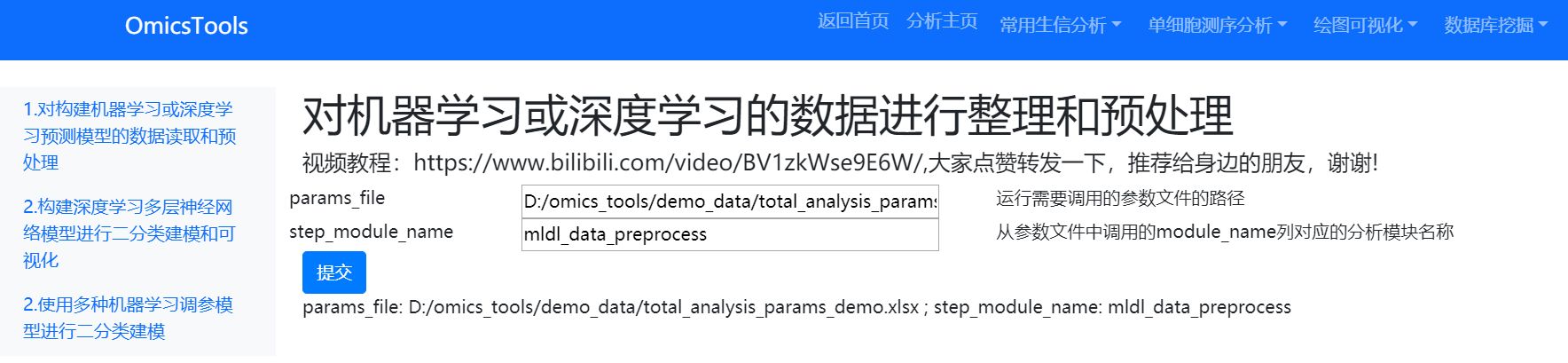
参数文件下载和使用
该模块的parms_file 需要给一个excel表的表格格式的参数文件,该参数文件可以在我的百度网盘中下载。

只需要在分析参数的这个xlsx的excel文件中修改一下mldl_data_preprocess分析模块下对应的在param_value列我标红的参数值,改成你自己的训练集和测试集文件所在的列名和文件中的基因id列名和样本id列名,样本分组列名即可,具体可以参考该模块下我的那个详细的教学视频,该视频观看链接已经放在了分析模块的内部了。
用到的训练集和测试集文件
文件目录下的所有文件
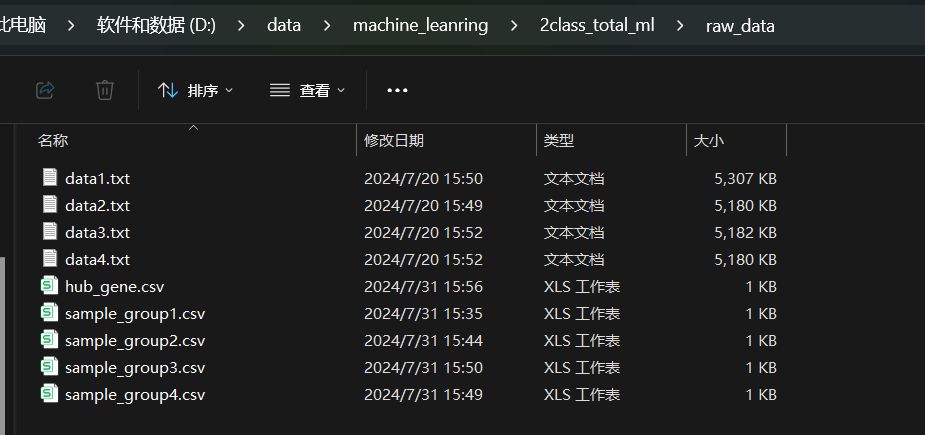
这是分析用到的所有数据文件存放的目录路径,其中:
- data1.txt是训练数据集文件,sample_group1.txt是该data1.txt对应的样本分组分类标签文件
- data2.txt, data3.txt, data4.txt是三个测试数据集文件,sample_group2.csv,sample_group3.csv,sample_group4.csv是这三个测试数据集分别对应的样本分组分类标签文件。当前这里是用了3个测试数据集文件和分类标签文件,大家也可以用更少或更多的测试数据集文件和分类标签文件
- hub_gene.csv 是机器学习或深度学习用到的一组关键基因列表,后面只会从data1.txt, data2.txt, data3.txt, data4.txt这些训练数据集和测试数据集中提取出这一组基因对应的表达数据进行建模和预测。
文件的具体内容
data1.txt, data2.txt, data3.txt, data4.txt这些基因表达数据集的文件内容
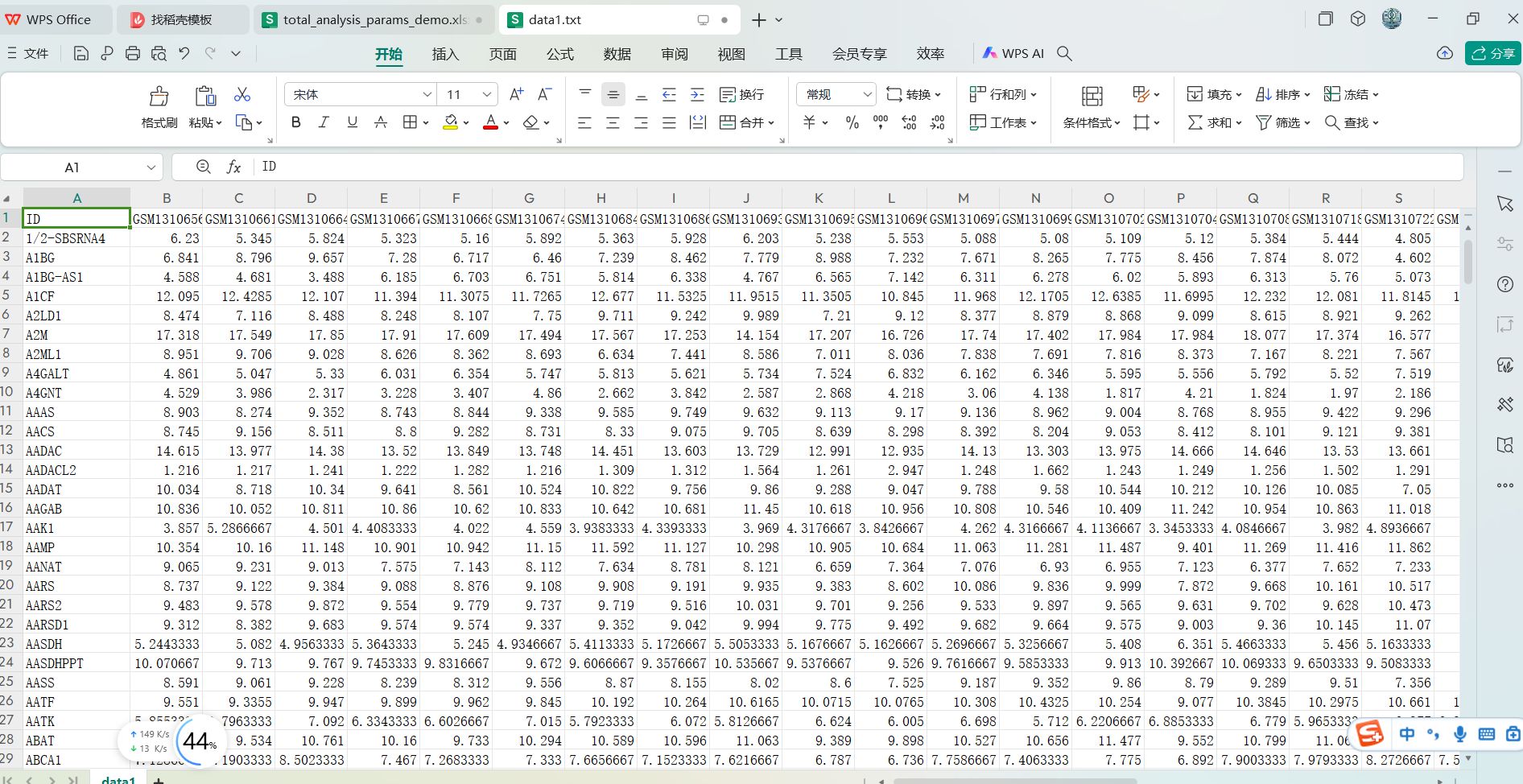
这些文件基本上都是第1列为基因名列,其它列都是样本列的这样的数据格式,即是一个行名为基因名,列名为样本编号的基因表达矩阵。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











