




 本文介绍了HTML5中的attribute和property的概念,包括attribute是HTML自定义或预定义属性,而property是JavaScript中对象的直接属性。每个预定义的attribute都有对应的property。接着讨论了布尔值属性和非布尔值属性的差异,以及attribute与property的同步关系,特别是用户操作实际上是在操作property。最后,建议在jQuery中,对于布尔值属性使用prop方法,而非布尔值属性则使用attr方法。
本文介绍了HTML5中的attribute和property的概念,包括attribute是HTML自定义或预定义属性,而property是JavaScript中对象的直接属性。每个预定义的attribute都有对应的property。接着讨论了布尔值属性和非布尔值属性的差异,以及attribute与property的同步关系,特别是用户操作实际上是在操作property。最后,建议在jQuery中,对于布尔值属性使用prop方法,而非布尔值属性则使用attr方法。
1.什么是attribute,什么是property属性?
attribute: html自定义属性 和预定义属性
property: js原生对象的直接属性
每一个预定义的attribute都会有一个property与之对应
2.什么是布尔值属性,什么是非布尔值属性?
property所对应的值是否为布尔值类型
3.attribute和property同步关系
非布尔值属性: 实时同步
布尔值属性:
没有动过property,attribute会同步property,property不会同步attribute
动过property,都不会同步
4.用户操作的是property
浏览器认property
5.Jquery中两个方法attr() prop()
布尔值属性最好使用prop方法
非布尔值属性attr方法
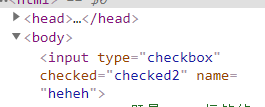
<input type="checkbox" checked="checked" name="lyp" /> <!--checked既是input标签的attribute(对于html),又是input节点的property(对于js)-->
<script type="text/javascript">
var l= document.querySelector("input[type=checkbox]")
//布尔值属性:你的property是布尔值类型 checked就是布尔值属性 改变property不会同步attribute
debugger
l.setAttribute("checked","checked1") //操作标签的attribute
l.setAttribute("checked","checked2")
l.checked = true
l.checked = "checked3" //操作节点的property
l.checked = "checked4"
debugger
//非布尔值属性:你的property是非布尔值类型 name就是非布尔值属性 在非布尔值属性里面,property和attribute会实时同步
l.setAttribute("name",'lalala')
l.name = "heheh"
//浏览器只认property
</script>

















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









