







 本文介绍了如何在Excel中处理重复数据。首先对A列数据进行分列,因数据格式不一致可能导致问题。接着在B和D列添加数字1作为索引,以便进行匹配。通过对比A列和C列数据,使用数据筛选功能过滤掉C列的重复项。最终,保留处理后的A列数据,并在其他工作表中验证结果。该方法适用于需要清理和整理大量数据的场景。
本文介绍了如何在Excel中处理重复数据。首先对A列数据进行分列,因数据格式不一致可能导致问题。接着在B和D列添加数字1作为索引,以便进行匹配。通过对比A列和C列数据,使用数据筛选功能过滤掉C列的重复项。最终,保留处理后的A列数据,并在其他工作表中验证结果。该方法适用于需要清理和整理大量数据的场景。
需求:筛选重复数据,A列是1000条数据,C列是100条数据,删除重复的数据,只剩900条。
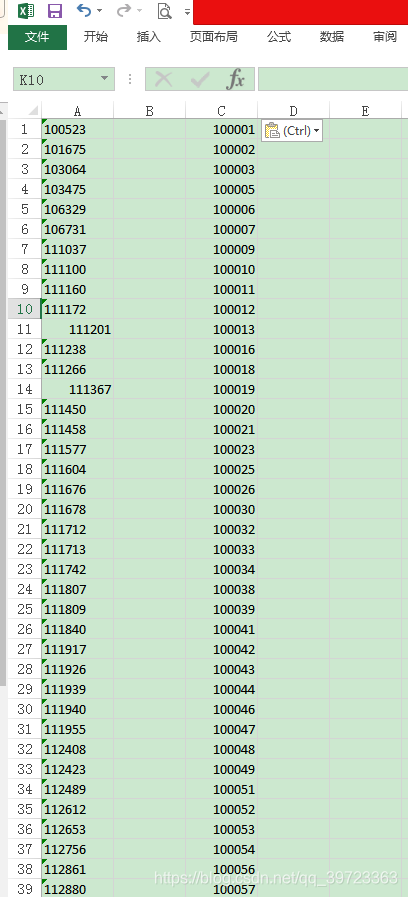
首先,A列数据要分列,因为数据格式不一样,会导致后面的问题,一直下一步到完成
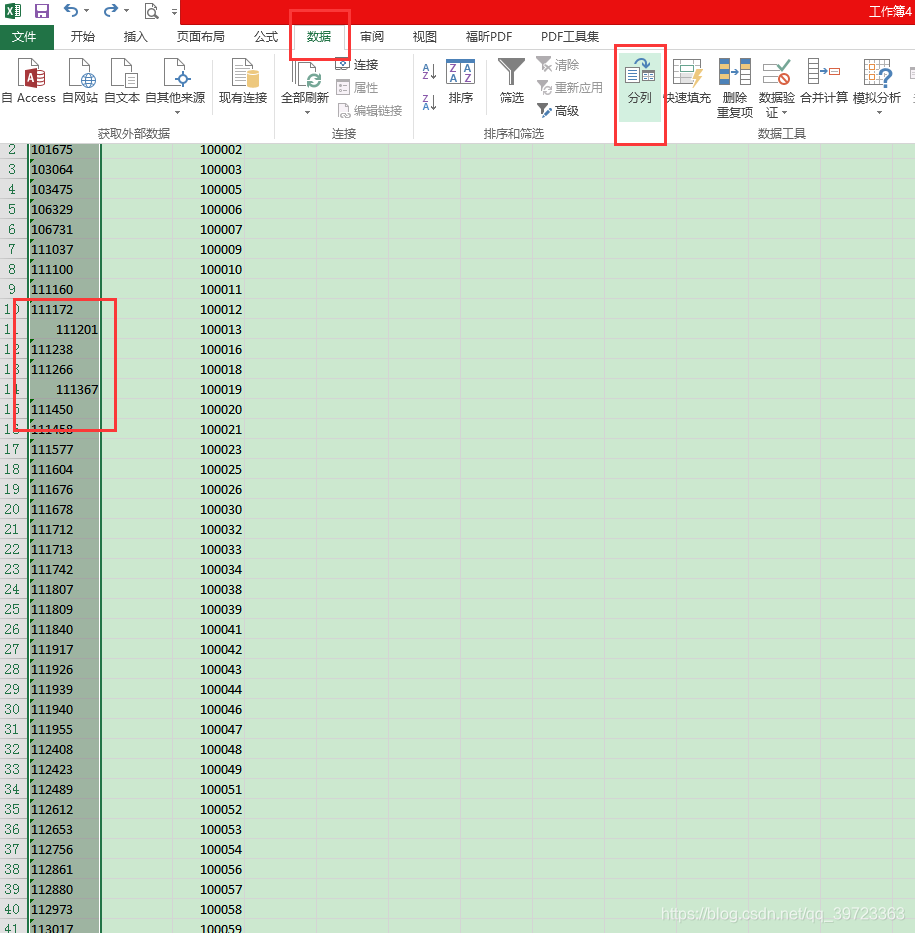
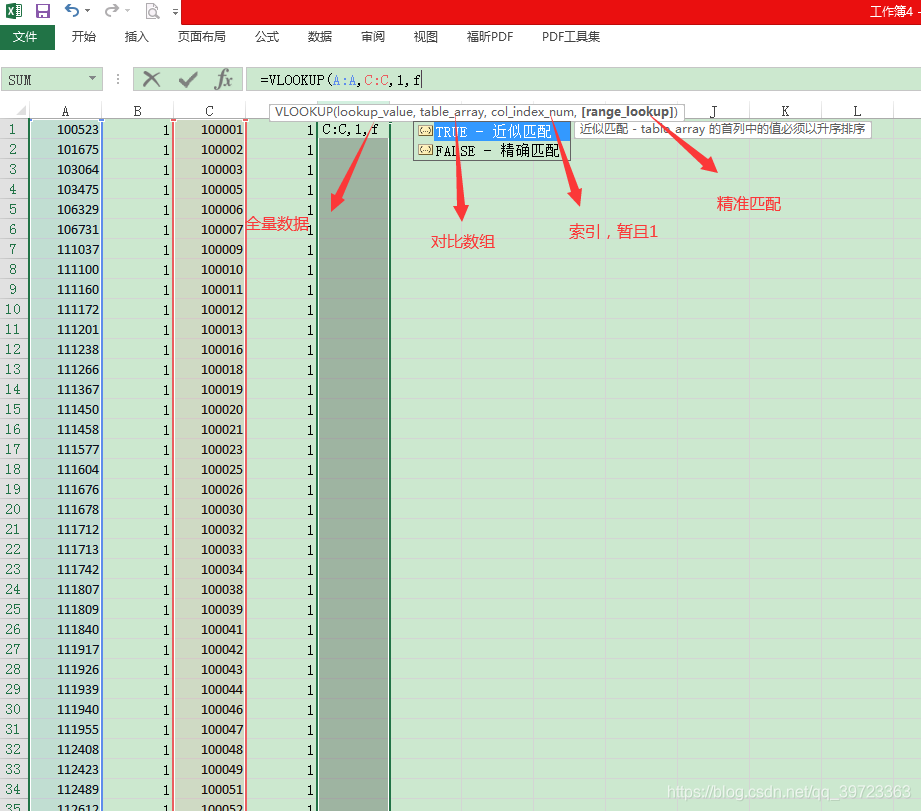
第二步,在B和D列加数字1,相当于索引,相同的数据长度,做匹配,下图A和C的数据取反了
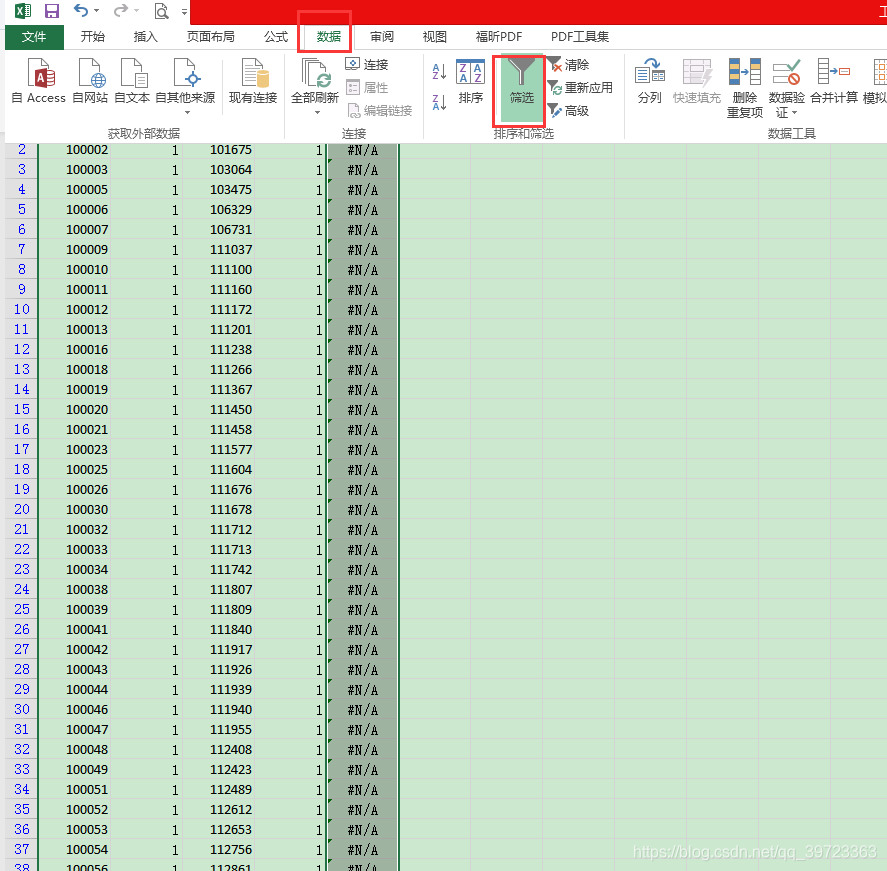
第三步,数据--筛选,然后过滤掉C列数据
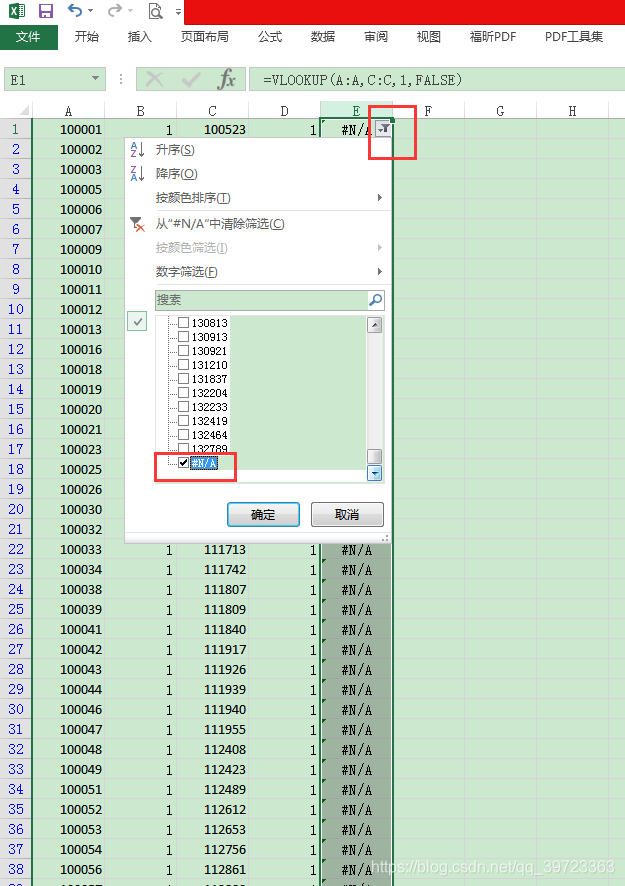
最后复制A列的数据,已经处理好的数据,到其他页面,验证完成
需求:筛选重复数据,A列是1000条数据,C列是100条数据,删除重复的数据,只剩900条。
首先,A列数据要分列,因为数据格式不一样,会导致后面的问题,一直下一步到完成
第二步,在B和D列加数字1,相当于索引,相同的数据长度,做匹配,下图A和C的数据取反了
第三步,数据--筛选,然后过滤掉C列数据
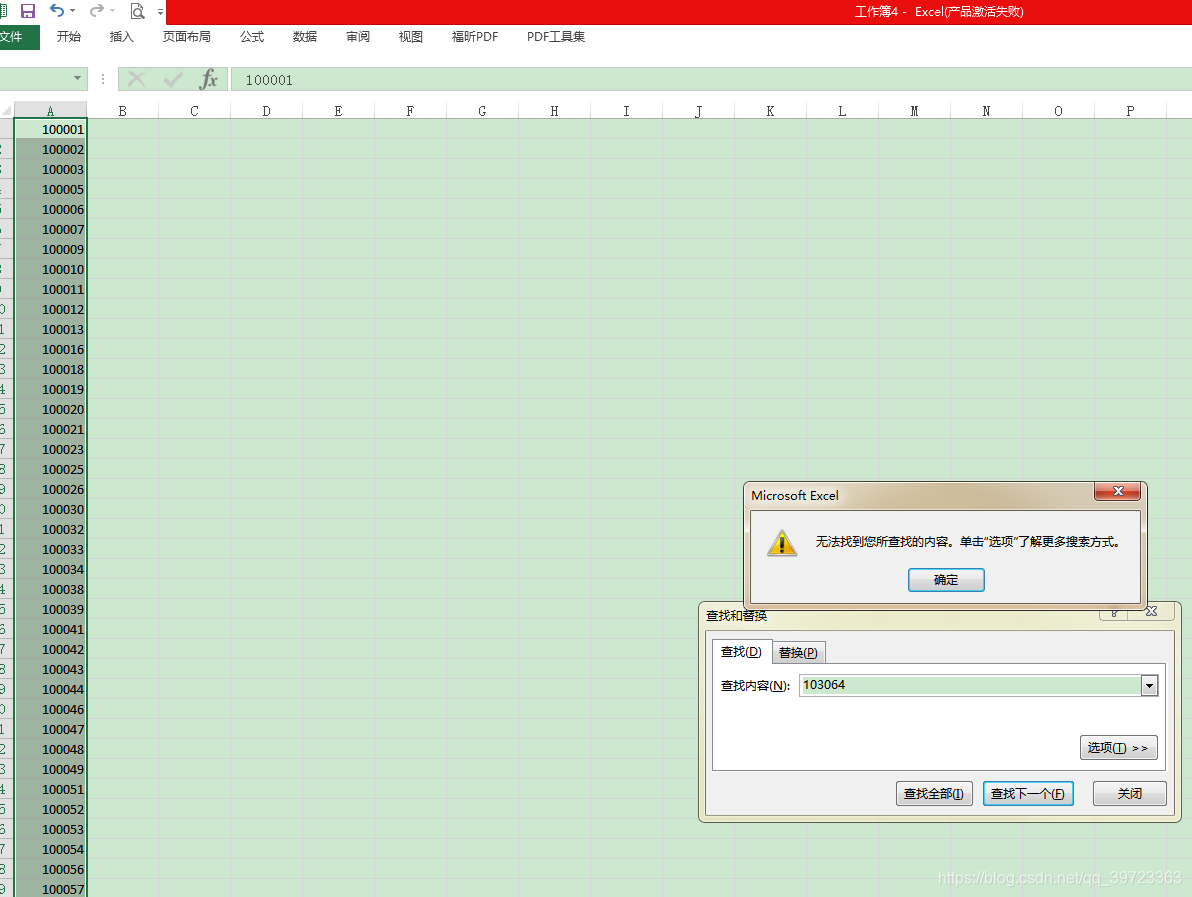
最后复制A列的数据,已经处理好的数据,到其他页面,验证完成
 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























