







摘要
分组和识别是视觉场景理解中的重要组成部分,例如用于目标检测和语义分割。在端到端的深度学习系统中,图像区域的分组通常是通过来自像素级识别标签的自上而下监督隐式地发生的。相反,在本文中,我们提出将分组机制引入深度网络,从而使语义分割能够仅通过文本监督自动生成。我们提出了一种分层的分组视觉变换器(GroupViT),它超越了常规的网格结构表示,学习将图像区域分组为逐渐增大的任意形状的段。我们将GroupViT与文本编码器联合训练,在一个大规模的图像-文本数据集上通过对比损失进行训练。仅通过文本监督且没有任何像素级注释,GroupViT能够学习将语义区域分组,并成功地以zero-shot的方式转移到语义分割任务上,即无需任何进一步的微调。它在PASCAL VOC 2012数据集上取得了52.3%的zero-shot准确度(mIoU),在PASCAL Context数据集上取得了22.4%的zero-shot准确度,并且与需要更多监督的最先进的迁移学习方法相比,表现出色。我们已将代码开源,网址为:https://github.com/NVlabs/GroupViT。
1. 引言
视觉场景自然由语义相关的像素组组成。分组和识别之间的关系在视觉理解中已被广泛研究,即使是在深度学习时代之前。在自下而上的分组中,首先将像素重新组织成候选组,然后使用识别模块处理每个组。这个流程已成功应用于从超像素进行图像分割、为目标检测和语义分割构建区域提议。除了自下而上的推理,自上而下的识别反馈也可以提供信号,以实现更好的视觉分组。

然而,随着深度学习时代的到来,显式的分组和识别的概念在端到端训练系统中已经不再是分离的,而是更加紧密地耦合在一起。例如,语义分割通常是通过全卷积网络(FCN)来实现的,其中像素分组仅在输出时通过识别每个像素的标签才显现出来。这种方法消除了显式分组的需求。尽管这种方法非常强大,并且仍然能提供最先进的性能,但它有两个主要的局限性:(i)学习受到每像素人工标签的高昂成本的限制;(ii)所学习的模型仅限于有限的标签类别,无法泛化到未见过的类别。最近,通过文本监督学习视觉表征取得了巨大的成功,在迁移到下游任务时也展现了很好的效果[63]。这种学习到的模型不仅能够以zero-shot方式迁移到ImageNet分类任务,并且实现最先进的性能,还能在超越ImageNet的目标类别上进行识别。受到这些研究的启发,我们提出了一个问题:是否能够仅通过文本监督来学习一个语义分割模型,而不需要任何每像素注释,并且能够以zero-shot的方式泛化到不同的对象类别集或词汇中?
为了实现这一目标,我们提出将分组机制重新引入深度网络,这样可以使语义分割仅通过文本监督自动生成。我们的方法概述如图1所示。通过在大规模配对图像-文本数据集上使用对比损失进行训练,我们使得模型能够在没有任何进一步注释或微调的情况下,zero-shot地迁移到多个语义分割词汇。我们的关键思想是利用视觉变换器(ViT),并将一个新的视觉分组模块整合到其中。
我们称我们的模型为GroupViT(分组视觉变换器)。与在规则网格上操作的卷积神经网络(ConvNets)不同,变换器的全局自注意力机制自然提供了将视觉标记组合成非网格形状段的灵活性。因此,与最近基于ViT的应用[17, 25, 48, 86]将视觉标记组织成网格不同,我们提出将视觉标记进行分层分组,形成不规则形状的段。具体来说,我们的GroupViT模型通过一系列变换器层的层次结构进行组织,每个阶段包含多个变换器来执行群组段之间的信息传播,并有一个分组模块将较小的段合并为更大的段。对于不同的输入图像,我们的模型动态地形成不同的视觉段,每个段直观地表示一个语义概念。
我们仅通过文本监督训练GroupViT。为了进行学习,我们在GroupViT的最终阶段使用平均池化合并视觉段输出。然后,我们通过对比学习将此图像级嵌入与来自文本句子的嵌入进行比较。我们通过使用对应的图像和文本对构建正向训练对,通过使用来自其他图像的文本构建负向训练对。我们使用变换器模型提取文本嵌入,并与GroupViT一起从头开始联合训练。值得注意的是,尽管我们仅在图像级别提供文本训练监督,但我们发现通过我们的分组架构,语义上有意义的段会自动生成。
在推理过程中,对于语义分割任务,给定输入图像,我们使用GroupViT提取其视觉组(如图1所示)。每个最终组的输出代表图像的一个段。给定一个用于分割的标签名称词汇,我们使用文本变换器提取每个标签的文本嵌入。然后,为了执行语义分割,我们将类别标签分配给图像段,依据它们在嵌入空间中的相似度。在我们的实验中,我们展示了仅使用文本监督训练的GroupViT,能够在没有任何微调的情况下,zero-shot地迁移到PASCAL VOC[26]和PASCAL Context 数据集的语义分割任务上。我们在PASCAL VOC 2012上取得了52.3%的平均交并比(mIoU),在PASCAL Context上取得了22.4%的mIoU,并且与需要更多监督的最先进的迁移学习方法相比,表现出色。根据我们的了解,我们的工作是首个在不同标签词汇上,单纯依赖文本监督而无需任何像素级标签,实现zero-shot语义分割的研究。
我们的贡献如下:
- 超越深度网络中的常规形状图像网格,我们提出了一种新颖的GroupViT架构,执行视觉概念的分层自下而上的分组,形成不规则形状的组。
- 在没有任何像素级标签和训练的情况下,仅使用图像级别的文本监督和对比损失,GroupViT成功地学习了将图像区域分组,并能够以zero-shot的方式迁移到多个语义分割词汇。
- 据我们所知,本研究是首个仅通过文本监督,且无需任何像素级标签,实现zero-shot迁移到多个语义分割任务的工作,并为这一新任务奠定了坚实的基准。
2. 相关工作
视觉变换器(Vision Transformer)。受变换器在自然语言处理(NLP)中的成功启发[22,81],视觉变换器(ViT)[24]最近被提出,并成功应用于多个计算机视觉任务,包括图像分类[48, 77, 78, 92]、目标检测[48, 84, 95]、语义分割[48, 87, 98]和动作识别[4, 6, 27, 49, 66]。然而,和卷积神经网络(ConvNets)一样,大多数ViT变体仍然在规则的图像网格上操作。例如,Liu等人[48]将图像划分为规则形状的窗口,并对每个窗口应用变换器块。卷积操作也被重新插入到[17, 25, 86]的变换器块中。尽管这些ViT变体取得了显著的性能,但它们并没有充分利用变换器的全局自注意力机制的灵活性。也就是说,自注意力机制在设计上可以应用于任何任意的图像段,并不局限于矩形形状和扫描顺序的网格。另一方面,我们的GroupViT模型利用了变换器的这一特性,学习将视觉信息分组成多个任意形状的段。通过分层设计,它进一步将较小的段合并为更大的段,并为每个图像生成不同的语义组。
文本监督的表征学习。随着大规模图像-文本配对数据在互联网上的出现,基于文本监督的表征学习[15,20,33,35,40,42,53,63,96]已经被证明在转移到各种下游任务中取得了成功,例如视觉问答[2,100]和视觉推理[94]。例如,Desai等人[20]通过图像描述任务预训练卷积神经网络(ConvNets),并通过微调下游任务的标注(如目标检测标签)来迁移表征。最近,Radford等人[63]提出在图像和文本之间进行对比学习。他们展示了所学习的模型可以在不进行微调的情况下,以zero-shot的方式直接迁移到ImageNet分类[19]任务中。超越图像分类,我们的GroupViT模型进一步探索了仅使用文本监督的zero-shot迁移到语义分割任务,这在现有的研究中尚未有类似的工作。
视觉定位(Visual Grounding)。视觉定位旨在学习图像区域与文本之间的对应关系。一类研究探索了完全监督的方法,通过数据集如Flickr30k Entities[62]和Visual Genome[38],在图像中检测与文本相关的边界框[15, 29, 36, 53, 61]。为了扩展学习,提出了弱监督的视觉定位方法,在训练过程中不提供边界框和文本的对应关系[12, 31, 45, 46, 83, 91]。然而,为了定位目标边界框,这些方法仍依赖于预训练的目标检测器[83, 91],而这些检测器又利用了来自其他数据集的框注释。虽然相关,但我们强调我们的任务设置与视觉定位有两个主要区别:(i)我们在互联网上的数百万个噪声图像-文本配对上训练我们的模型,而视觉定位需要相对较小规模的人工策划和标注数据;(ii)我们的GroupViT提供了一个自下而上的进阶视觉分组机制,通过文本监督自动生成目标段,而视觉定位则需要借用来自其他数据集的边界框注释。
用更少监督进行语义分割。已经提出了多种研究方向,用于在比密集的每像素标签更少的监督下进行分割。例如,少样本学习[23, 47, 54, 59, 75, 82, 90]和主动学习[9, 67, 71, 72, 88]被提出用于尽可能减少像素级标签的分割。更进一步,zero-shot方法[7, 41]被提出,用于学习未见过类别的分割模型,而不使用它们的像素级标签。然而,这仍然需要在已见类别上进行分割标签的学习作为初步步骤。另一类相关的研究是弱监督语义分割[1, 10, 28, 34, 39, 43, 70, 73, 85],它旨在仅通过图像级别的对象类别监督来学习语义分割。尽管这大大减少了监督,但它仍然需要使用有限词汇的手工标注,在精心策划的图像数据集上进行学习。与所有以往的工作不同,我们的方法完全摆脱了人工注释,GroupViT通过大规模的噪声文本监督进行训练。我们展示了,GroupViT能够zero-shot地泛化到任何类别集的语义分割任务,而不依赖固定的词汇。
同时开发的未公开的文本监督语义分割方法[30, 89, 93, 99]也展示了有前景的结果。与这些方法相比,GroupViT的一个主要区别在于,它们利用了在大型私有数据集(400M-1.8B图像-文本配对)上预训练的视觉-语言模型[33,63],而我们的GroupViT则是从头开始在更为嘈杂的公共数据集(总计3000万张图像)上训练,用于学习分组和分割,并且依然取得了具有竞争力的性能。在这些工作中,OpenSeg[30]也通过类无关的掩膜注释学习生成掩膜提议,而我们的方法不需要任何掩膜注释。
3. 方法
我们提出了GroupViT架构,用于仅通过文本监督实现语义分割的zero-shot迁移。GroupViT引入了一种新的分层分组变换器架构,利用变换器的全局自注意力机制,将输入图像分割成逐渐增大的任意形状的组。我们首先在3.1节详细描述GroupViT的架构。为了训练它,我们采用精心设计的图像-文本对之间的对比损失,如3.2节所述。最后,我们将训练好的GroupViT模型迁移到zero-shot语义分割任务中,而不需要进一步的微调,如3.3节所述。
3.1. 分组视觉变换器
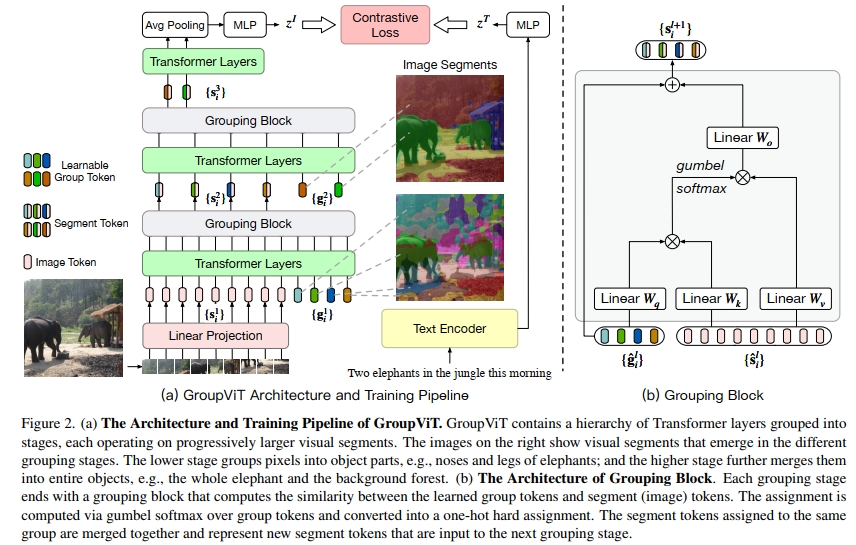
我们介绍了GroupViT图像编码器(图2),它通过基于变换器的架构执行视觉概念的分层渐进分组。在GroupViT中,我们将变换器层分为多个分组阶段。在每个阶段,我们通过自注意力学习多个分组标记(作为可学习的参数),这些标记通过自注意力全局聚合来自所有图像标记(段)的信息。然后,我们使用学到的分组标记,通过分组块将相似的图像标记合并在一起。通过一系列分组阶段,我们将较小的图像段合并为更大的段。接下来,我们描述每个组件。
架构:遵循ViT[24]的设计,我们首先将输入图像划分为N个不重叠的补丁,并将每个补丁线性投影到潜在空间。我们将每个投影的补丁视为输入图像标记,并将它们的集合表示为 { p i } i = 1 N \{ { \bf p } _ { i } \} _ { i = 1 } ^ { N } {
pi}i=1N。每个分组阶段,除了图像标记,我们还将一组可学习的分组标记与其一起输入变换器进行处理。
多阶段分组
如图2(a)所示,我们并非将所有N个输入图像标记通过变换器的所有层,而是将其层分成一个分组阶段的层次结构。每个阶段在其末尾包含一个分组块,用于将较小的组合并成更大的组。
形式上,假设有L个分组阶段,每个阶段由l索引,并且有一组可学习的组标记 { g i } i = 1 M l \{ \mathbf { g } _ { i } \} _ { i = 1 } ^ { M _ { l } } {
gi}i=1Ml。为了简化起见,我们将输入到第一个分组阶段的图像补丁 { p i } i = 1 N \{ { \bf { p } } _ { i } \} _ { i = 1 } ^ { N } {
pi}i=1N视为初始段集 { s i 1 } i = 1 M 0 \{ \mathbf { s } _ { i } ^ { 1 } \} _ { i = 1 } ^ { M _ { 0 } } {
si1}i=1M0,其中 N = M 0 N = M _ { 0 } N=M0。我们简化 { s i l } i = 1 M l − 1 \{ \mathbf { s } _ { i } ^ { l } \} _ { i = 1 } ^ { M _ { l - 1 } } {
sil}i=1Ml−1到 { s i l } \{ \mathbf { s } _ { i } ^ { l } \} {
sil},类似地, { g i l } i = 1 M l \{ \mathbf { g } _ { i } ^ { l } \} _ { i = 1 } ^ { M _ { l } } {
gil}i=1Ml到 { g i l } \{ \mathbf { g } _ { i } ^ { l } \} {
gil}。从 l = 1 l = 1 l=1开始,对于每个分组阶段,我们首先将 { s i l } \{ \mathbf { s } _ { i } ^ { l } \} {
sil}和 { g i l } \{ \mathbf { g } _ { i } ^ { l } \} {
gil}连接在一起,然后将它们输入若干个变换器层,每个层通过以下方式在它们之间进行信息传播:
{ g ^ i l } , { s ^ i l } = Transformer ( [ { g i l } ; { s i l } ] ) \{ \hat { \mathbf { g } } _ { i } ^ { l } \} , \{ \hat { \mathbf { s } } _ { i } ^ { l } \} = \operatorname { T r a n s f o r m e r } ( [ \{ \mathbf { g } _ { i } ^ { l } \} ; \{ \mathbf { s } _ { i } ^ { l } \} ] ) {
g^il},{
s^il}=Transformer([{
gil};{
sil}])
其中 [ ; ] [ \ ; \ ] [ ; ]表示连接操作。然后,我们通过分组块将更新后的 M l − 1 M _ { l - 1 } Ml−1个图像段标记 { s ^ i l } \{ \hat { \mathbf { s } } _ { i } ^ { l } \} {
s^il}分组为 M l M _ { l } Ml个新的段标记 { s i l + 1 } i = 1 \{ \mathbf { s } _ { i } ^ { l + 1 } \} _ { i = 1 } {
sil+1}i=1,具体方式如下:
{ s i l + 1 } = GroupingBlock ( { g ^ i l } , { s ^ i l } ) \{ \mathbf { s } _ { i } ^ { l + 1 } \} = \operatorname { G r o u p i n g B l o c k } ( \{ \hat { \mathbf { g } } _ { i } ^ { l } \} , \{ \hat { \mathbf { s } } _ { i } ^ { l } \} ) {
sil+1}=GroupingBlock({
g^il},{
s^il})
在每个分组阶段, M l < M l − 1 M _ { l } < M _ { l - 1 } Ml<Ml−1,即每个阶段的组标记逐渐减少,导致图像段变得越来越大且越来越少。经过最后一个分组阶段L后,我们对所有段标记应用变换器层,并最终对它们的输出进行平均,得到最终的全局图像表示 z I z ^ { I } z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4970
4970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











