






 本文介绍了哈希的概念,通过一个数组示例说明哈希如何提高查找效率,并探讨了哈希函数的构造方法。接着,详细讲解了哈希冲突及其解决策略,重点介绍了使用链地址法处理冲突的实现过程,包括节点结构、哈希表头设计及相关操作函数的代码实现。
本文介绍了哈希的概念,通过一个数组示例说明哈希如何提高查找效率,并探讨了哈希函数的构造方法。接着,详细讲解了哈希冲突及其解决策略,重点介绍了使用链地址法处理冲突的实现过程,包括节点结构、哈希表头设计及相关操作函数的代码实现。
在学习哈希之前,我们思考这样一个问题,在下面的数组中,我们想在第一时间内确定一个数是否在这个数组里面(以35为例),我们应该如何做?
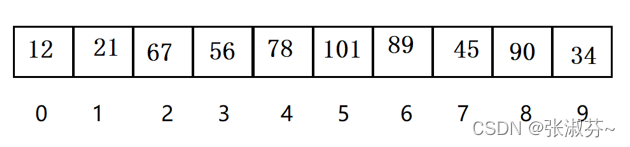
大家的第一想法肯定是从前向后遍历一遍,但我们会发现从前向后遍历一遍的时间复杂度为O(n),这并不是我们想要的第一时间内找到,我们观察数组,发现,数据和数组下标(也就是存储位置)没有任何关系,如果数据和它的存储位置有一个对应的关系,我们就可以通过数据和对应关系直接找到这个数据的存储位置,再判断数组存储的这个数和我们想要的数(35)是否相等,就可以得出35在不在数组中。我们给出哈希的概念。
哈希:(哈希也叫散列,哈希表==散列表)
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。查找时,根据这个确定的对应关系找到给定值key的映射f(key),若查找集合中存在这个记录,则必定在f(key)的位置上。
这里我们把这种对应关系f称为散列函数,又称为哈希函数。按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表或者哈希表。那么关键字对应的记录存储位置我们称为散列地址。
继续以上面的那个数组为例,我们给出对应关系(也就是哈希函数):y=x%10。
y=存储位置,x=数据的关键字
例如:数据12,12%10=2,我们就将数据12存储在数组下标为2的位置;
数据21,21%10=1,我们就将数据21存储在数组下标为1的位置;....
依次类推,我们得到以下数组:
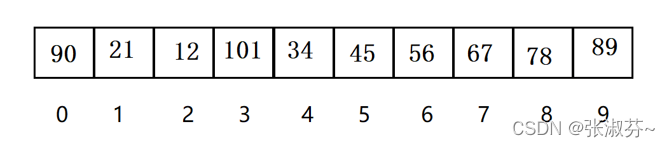
(这里我给到值比较特殊,正好每个数据都有对应的存储位置,要是两个数的散列地址相同,我们就称发生了哈希冲突,这个下边会继续讲解)
这样每个数据和存储它的位置都有关系了,我们要查35在不在这个数组中,35%10=5,我们看数组下标为5的位置,发现是45,45!=35,所以35不在这个数组中。
注意:哈希是一种存储方法,也是一种查找方法
接下来我们说,如何构造哈希函数,这里给出6种方法(这里最常用的是第4个方法,其他的方法有兴趣可以看看):
1.直接地址法:f(key)=a*key+b
2.数字分析法:电话号码的后四位作为关键字
3.平方取中法:假设关键字1234,平方后为1522756,取中间的三位227作为散列地址
4.除留余数法(最常用):f(key)=key%p(p相当于格子数)(p<m,m为散列表长)
5.折叠法:(将关键字分割成位数相同的几部分,(最后一部分位数可以不同)然后去这几部分的叠加和(舍去进位)作为散列地址)
关键字9876543210,散列表表长为3,分成4部分,987|654|321|0,987+654+321+0=1962,取962为散列地址
6.随机数法:f(key)=random(key),random为随机函数
(这6种方法不是独立存在的,可以揉起来一起用)
我们再说哈希冲突,我们给出概念:
哈希冲突:哈希冲突:不同数据的关键字通过哈希函数得到一个相同的地址,这时就发生冲突,这种冲突一般叫做哈希冲突(存放位置已经有值)
解决哈希冲突的4种方法(截图来源于教材):
1.开放地址法:
1.1线性探测法:一旦发生冲突,就寻找下一个空的散列地址,只要散列表足够大
1.2二次探测法:和线性探测法相比,不仅要寻找下一个空的散列地址,同时还要寻找上一个,防止后边没有空的散列地址,而在前边
fi(key)=(f(key)+di)%m(di=1^2,-1^2,2^2,-2^2....-q^2<=m/2)
增加平方的目的是为了不让关键字都聚集在某一块区域
1.3随机探测法:位移量由随机函数探测得到

2.再散列函数法:准备多个散列函数,一旦发生哈希冲突,就换一个散列函数

3.链地址法(需要实现的代码):把冲突的节点串起来(单链表)
4.公共溢出区法:凡是冲突的另找一块存储

这里着重讲解链地址法,也是我们需要实现的代码:

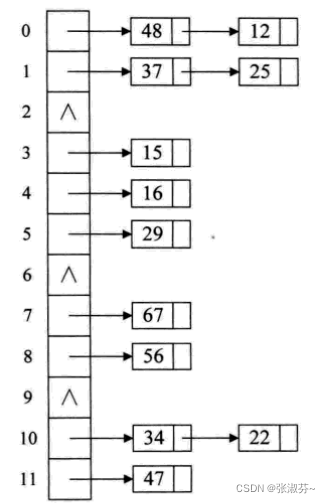
如上图,我们将散列地址相同的用单链表链接起来,接下来我们实现一下代码:
链地址法的有效节点和哈希表头需要单独设计。
typedef int ELEM_TYPE;
#define MAX_SIZE 12
//链地址法 中 后边连接的单链表的有效节点设计:
typedef struct Node
{
ELEM_TYPE data;
struct Node* next;
}Node,*PNode;
//链地址法的 哈希表头设计
typedef struct Head
{
struct Node arr[MAX_SIZE]; //数组 12个格子 每一个格子存放一个单链表的表头(用的是有效节点的结构体设计)
}Head, * PHead;
可执行函数声明:
//初始化
void Init_list_hash(struct Head* hd);
//插入(头插)
bool Insert_head(struct Head* hd, ELEM_TYPE val);
//删除
bool Del_val(PHead hd, ELEM_TYPE val);
//查找
struct Node* Search(PHead hd, ELEM_TYPE val);
//判空
bool IsEmpty(PHead hd);
//获取有效个数
int Get_length(PHead hd);
//清空
void Clear(PHead hd);
//销毁
void Destroy(PHead hd);
//打印
void Show(PHead hd);这里直接给出所有函数:
//初始化//对那数组中的12个单链表头结点进行初始化
void Init_list_hash(struct Head* hd)
{
for(int i=0; i<MAX_SIZE; i++)
{
hd->arr[i].next = NULL; //将每一个头节点的next全部置NULL即可
}
}
//插入(头插)
bool Insert_head(struct Head *hd, ELEM_TYPE val)
{
//assert
//购买新节点
struct Node *pnewnode = (struct Node*)malloc(1 * sizeof(struct Node));
assert(pnewnode != NULL);
pnewnode->data = val;
//找到插入位置
int hash = val % MAX_SIZE;
//插入
pnewnode->next = hd->arr[hash].next;//类似单链表头插代码:pnewnode->next = plist->next;
hd->arr[hash].next = pnewnode;
return true;
}
//删除(从前向后遍历一遍,确实存在val这个节点,则删除)//像单链表的按值删除
bool Del_val(PHead hd, ELEM_TYPE val)
{
//assert
int hash = val % MAX_SIZE;
struct Node *p = &hd->arr[hash];//保存头结点的地址
for(p; p->next!=NULL; p=p->next)//删除,需要前驱的for循环
{
if(p->next->data == val)
{
struct Node *q = p->next;
p->next = q->next;
free(q);
q = NULL;
return true;
}
}
return false;
}
//查找
struct Node * Search(PHead hd, ELEM_TYPE val)
{
//assert
int hash = val % MAX_SIZE;
struct Node *p = hd->arr[hash].next;//保存首元素的地址
for(p; p!=NULL; p=p->next) //查找,不需要前驱的for循环
{
if(p->data == val)
{
return p;
}
}
return NULL;
}
//判空
bool IsEmpty(PHead hd)
{
return Get_length(hd) == 0;
}
//获取有效个数
int Get_length(PHead hd)
{
int count = 0;
for(int i=0; i<MAX_SIZE; i++)
{
struct Node *p = hd->arr[i].next;//保存首元素的地址
for(p; p!=NULL; p=p->next) //查找,不需要前驱的for循环
{
count++;
}
}
return count;
}
//清空
void Clear(PHead hd)
{
Destroy(hd);
}
//销毁
void Destroy(PHead hd)
{
for(int i=0; i<MAX_SIZE; i++)
{
while(hd->arr[i].next != NULL)
{
struct Node *p = hd->arr[i].next;
hd->arr[i].next = p->next;
free(p);
}
}
}
//打印
void Show(PHead hd)
{
for(int i=0; i<MAX_SIZE; i++)
{
printf("%d: ", i);
struct Node *p = hd->arr[i].next;//保存首元素的地址
for(p; p!=NULL; p=p->next) //查找,不需要前驱的for循环
{
printf("%d ", p->data);
}
printf("\n");
}
}
















 4676
4676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









