







 本文详细解析PyTorch中的nn.Embedding模块,包括其作为lookup table的性质和如何通过indices获取word embeddings。通过示例解释了nn.Embedding.from_pretrained()的用法,说明了输入为indices时如何从weight矩阵中取出对应的词向量,形成二维句子的三维词向量张量。
本文详细解析PyTorch中的nn.Embedding模块,包括其作为lookup table的性质和如何通过indices获取word embeddings。通过示例解释了nn.Embedding.from_pretrained()的用法,说明了输入为indices时如何从weight矩阵中取出对应的词向量,形成二维句子的三维词向量张量。
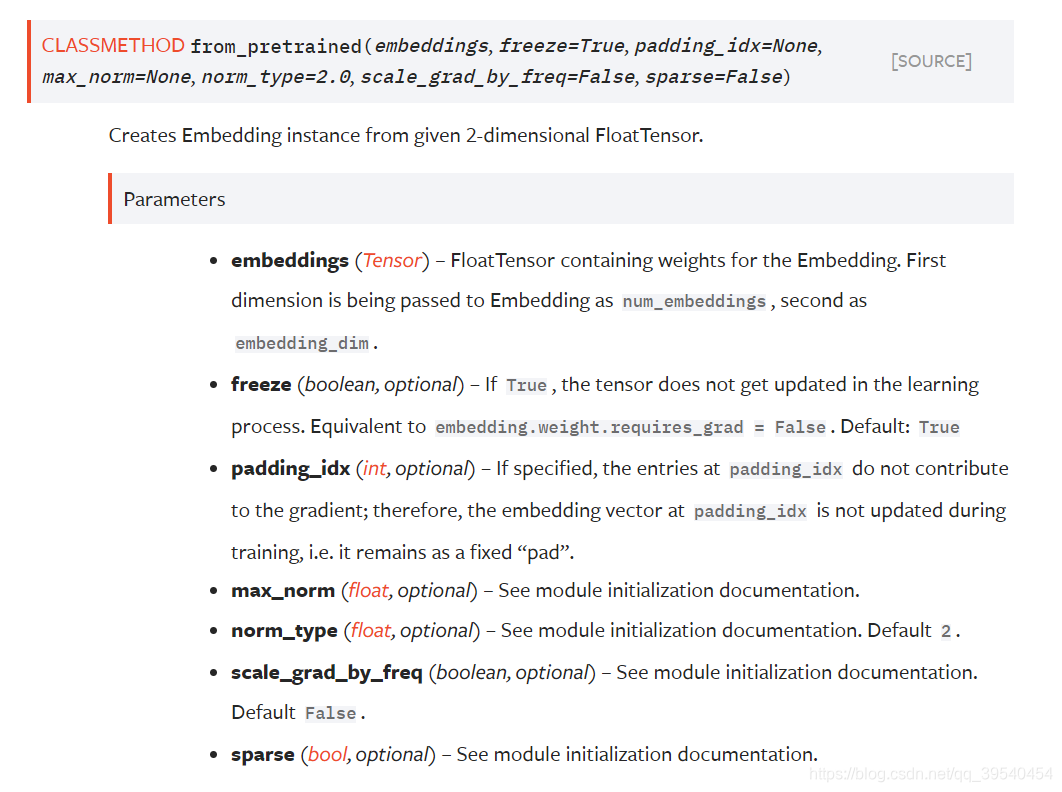
(2021.05.26补充)nn.Embedding.from_pretrained()的使用:
>>> # FloatTensor containing pretrained weights
>>> weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
>>> embedding = nn.Embedding.from_pretrained(weight)
>>> # Get embeddings for index 1
>>> input = torch.LongTensor([1])
>>> embedding(input)
tensor([[ 4.0000, 5.1000, 6.3000]])
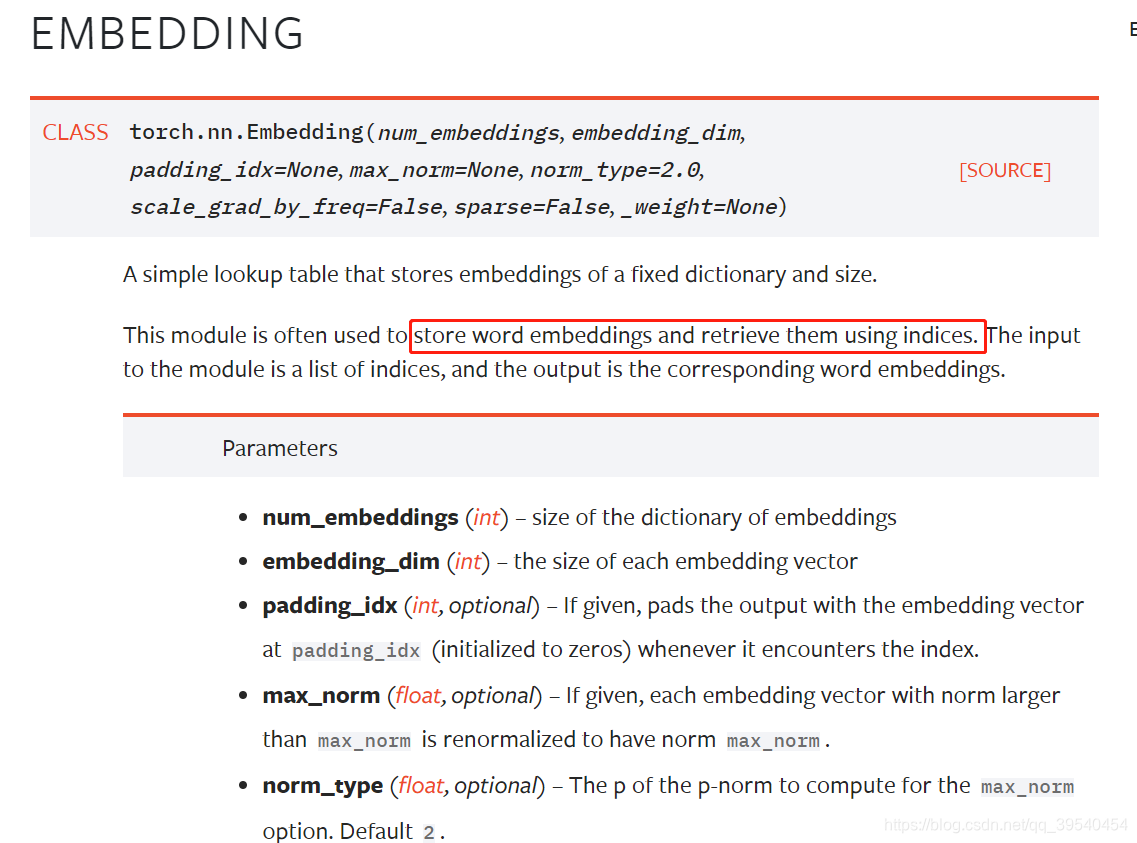
首先来看official docs对nn.Embedding的定义:
是一个lookup table,存储了固定大小的dictionary(的word embeddings)。输入是indices,来获取指定indices的word embedding向量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









