







IMPROVE OBJECT DETECTION WITH FEATURE-BASED KNOWLEDGE DISTILLATION: TOWARDS ACCURATE AND EFFICIENT DETECTORS学习笔记
ICLR2021
Introduction
-
大多数为图像分类设计的知识蒸馏网络在目标检测任务中效果不好,原因是:
- 前景和背景像素之间不平衡
- 缺乏对不同像素之间关系的提炼
-
基于以上两个原因,本文分别做了以下工作:
- attention-guided distillation 注意力引导蒸馏:通过注意力机制来发现前景物体的关键像素,从而使学生更加努力地学习其特征。
- non-local distillation非局部蒸馏:使学生不仅能够学习单个像素的特征,而且能够学习由非局部模块捕获的不同像素之间的关系。
-
本文提出的两个模块只在训练的时候需要,在推理的过程中不会引入额外的计算
-
本文的方法是基于特征的蒸馏,可以直接用于所有类型的目标检测器
-
不同于图像分类的知识蒸馏中高AP的教师网络会对学生网络造成负面影响,目标检测中的知识蒸馏需要高AP的教师网络
-
相当于是基于这篇工作进行改进Distilling object detectors with fine-grained feature imitation
METHODOLOGY

ATTENTION-GUIDED DISTILLATION
- 空间注意力 G s G^s Gs(每一点上C个通道的平均值):
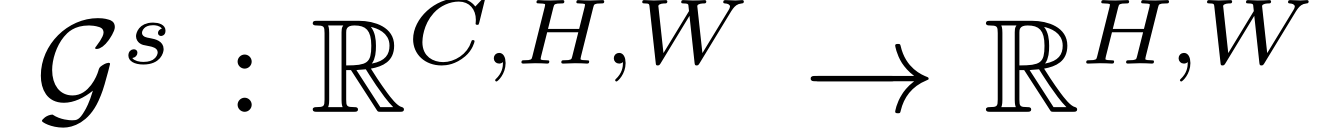
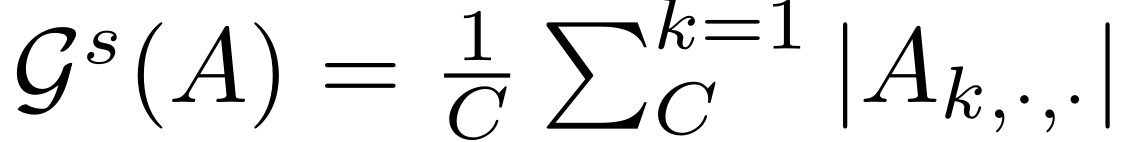
-
通道注意力 G c G^c Gc(每个通道上所有点的平均值):
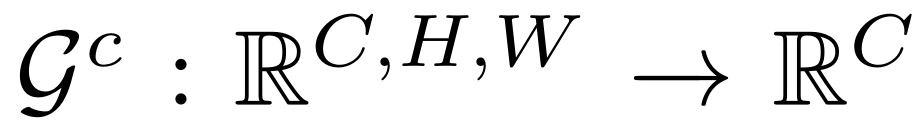
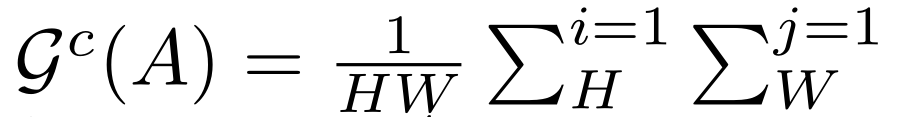
-
空间注意力Mask M s M^s Ms:

-
通道注意力Mask M c M^c Mc:
M c = C ⋅ s o f t m a x ( ( G c ( A S ) + G c ( A τ ) ) / T ) M^c=C ·softmax((G^c(A^S) +G^c(A^τ))/T) Mc=C⋅softmax((Gc(AS)+Gc(Aτ))/T)
T T T是softmax中的超参数,用来调节注意力mask中元素的分布:

- ATTENTION-GUIDED DISTILLATION的损失 L A G D L_{AGD} LAGD由两部分组成:attention transfer loss L A T L_{AT} LAT和attention-masked loss L A M L_{AM} LAM
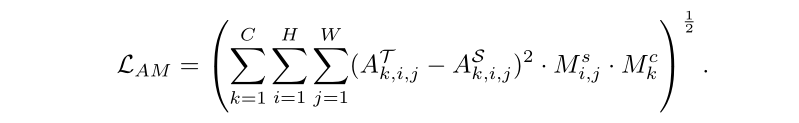

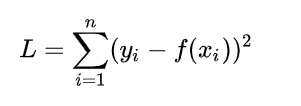
NON-LOCAL DISTILLATION

OVERALL LOSS FUNCTION

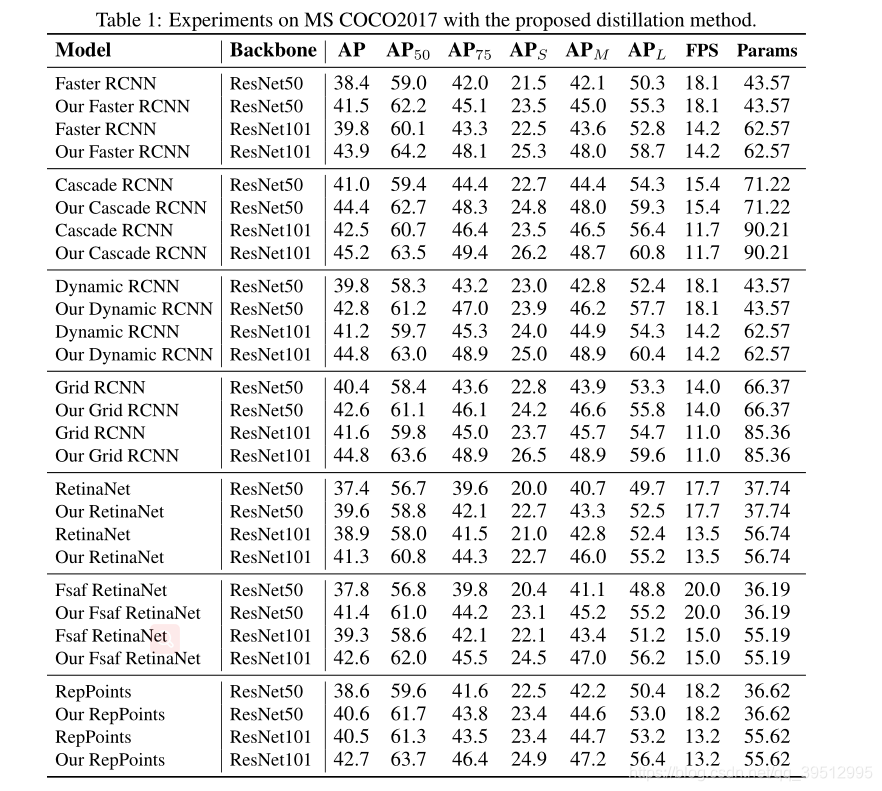
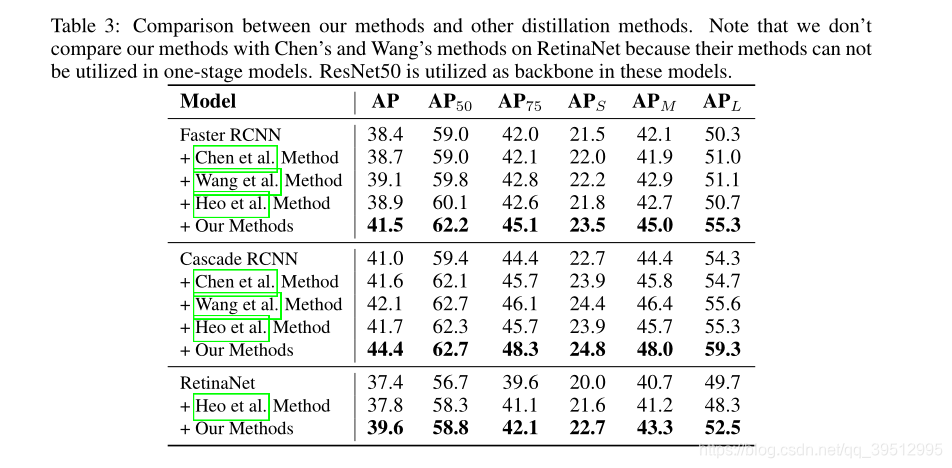
EXPERIMENT
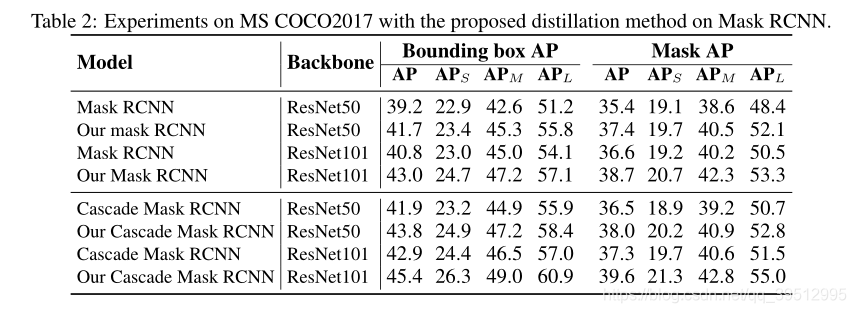
Ablation study

Sensitivity study on hyper-parameters

Sensitivity study on the types of non-local modules

Discussion
- 各个方面都有提高


















 5247
5247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









