







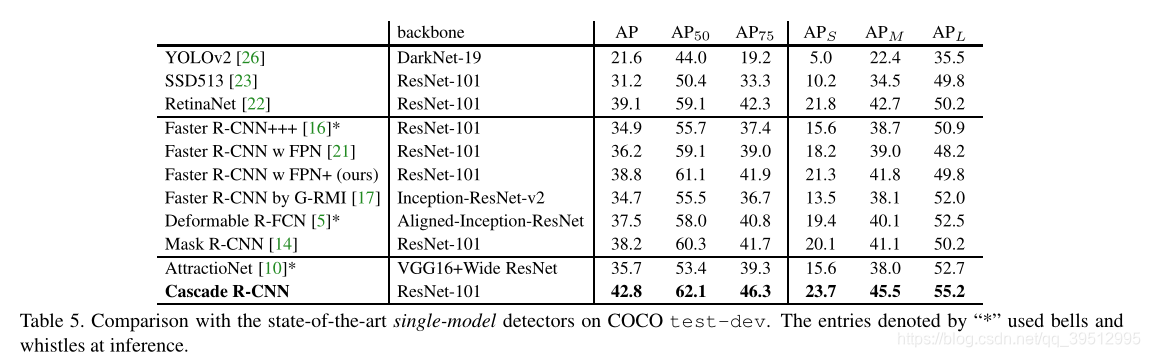
Cascade RCNN
Cascade R-CNN: High Quality Object Detection and Instance Segmentation(级联R-CNN)
CVPR2018
Abstract
在目标检测中,用IoU来定义正负样本,使用低阈值比如0.5通常会是产生噪声(识别错误的目标),而是用高阈值通常会使检测性能下降(漏检目标),造成这种情况的主要原因有两个:
-
大阈值使正样本指减少导致的过拟合
-
在train和inference过程中会引起mismatch问题。(inference-time quality mismatch between detector and test hypotheses)
提出了多级目标检测体系结构——级联R-CNN
mismatch问题
下图表示RPN提出的Proposals的分布,横轴表示Proposal与groundtruth之间的IoU,纵轴表示满足当前IoU的Proposal数量

- 在训练阶段,groundtruth已知,可以很自然的把与gt的iou大于threshold(0.5)的Proposals作为正样本,这些正样本参与之后的bbox回归学习。
- 在推理阶段,groundtruth未知, 所以只能把所有的proposal都当做正样本 。
我们可以明显的看到training阶段和inference阶段,bbox回归器的输入分布是不一样的,training阶段的输入proposals质量更高(被采样过,IoU>threshold),inference阶段的输入proposals质量相对较差(没有被采样过,可能包括很多IoU<threshold的),这就是论文中提到mismatch问题,这个问题是固有存在的,通常threshold取0.5时,mismatch问题还不会很严重。threshold越大,mismatch问题反而越严重。
Introduction
-
下图(a)(b)表示阈值分别设置为0.5和0.7时产生的边界框(推理完成后判断正负样本的阈值)
-
下图(c) 横轴表示经过RPN输入到Fast R-CNN网络中的用来区分正样本和负样本时的IoU ,纵轴表示经过Fast R-CNN网络,bbox回归之后的IoU , 不同的线条代表不同阈值训练出来的detector
- 大部分线条都是在y=x的灰色线条之上的,这就说明某个proposal在经过detector后的IoU几乎必然是增加的,那么再经过一个更大阈值训练的detector,它的IoU就会更好。
- 可以看到在0.550.6的范围内阈值为0.5的detector性能最好,在0.60.75阈值为0.6的detector性能最佳,而到了0.75之后就是阈值为0.7的detector了。因此,只有proposal自身的阈值和训练器训练用的阈值较为接近的时候,训练器的性能才最好,如果两个阈值相距比较远,就会出现较严重mismatch问题
-
下图(d) 横轴表示经过RPN输入到Fast R-CNN网络中的用来区分正样本和负样本时的IoU ,纵轴表示 inference阶段得到的AP值 , 不同的线条代表不同阈值训练出来的detector
- IoU的阈值越大,inference阶段的AP值和检测性能大多呈现下降趋势。**究其原因:**从图中我们可以意识到,单一阈值训练出的检测器效果非常有限,以现在最常见的阈值0.5为例,由于所有IoU大于0.5的proposal都会被选中,那么对于IoU0.60.95的proposal来说,detector的表现就很差了。那么,直接选用0.7的高阈值,此时阈值为0.50.7的proposal都被排除了,横轴0.7~0.95之间,红色线条的表现最差,实际上detector的性能反而是最低的,原因是这样子训练正样本大大减少,过拟合问题非常严重。

-
**如何能保证proposal的高质量又不减少训练样本? **
- 采用cascade R-CNN stages,用一个stage的输出去训练下一个stage, 留意到左图大部分线条都是在y=x的灰色线条之上的,这就说明某个proposal在经过detector后的IoU几乎必然是增加的,那么再经过一个更大阈值训练的detector,它的IoU就会更好。
Related Work
- 为了在R-CNN中减少冗余计算以提高速度,SPP-Net和Fast R-CNN引入了区域特征提取的思想。后来, Faster R-CNN 通过引入区域提议网络(RPN)实现了进一步的加速。
- R-FCN提出了高效的区域全卷积且没有精度损失,避免了Faster R-CNN在区域上的繁重计算
- MS-CNN 和FPN在多尺度推荐候选框,以缓解RPN接受域与实际目标大小的尺度不匹配。
Object Detection
- 第一行横纵轴分别是回归目标中的box的x方向和y方向偏移量;第二行横纵轴分别是回归目标中的box的宽、高偏差量
- 可以看到,从1st stage到2nd stage,proposal的分布其实已经发生很大变化了,因为很多噪声经过box reg实际上也提高了IoU,2nd和3rd中的那些红色点已经属于outliers,如果不提高阈值来去掉它们,就会引入大量噪声干扰,对结果很不利。从这里也可以看出,阈值的重新选取本质上是一个resample的过程,它保证了样本的质量。

- 从下图中,我们可以看到,1st stage大于0.5的,到2nd stage大于0.6的,到3rd stage大于0.7的……在这一个过程中proposal的样本数量确实没有特别大的改变,甚至还有稍许提升,和上图结合起来看,应该可以说是非常强有力的证明了。
- 总结一下:
- cascaded regression不断改变了proposal的分布,并且通过调整阈值的方式重采样
- cascaded在train和inference时都会使用,并没有偏差问题
- cascaded重采样后的每个检测器,都对重采样后的样本是最优的,没有mismatch问题

-
下图(a)是Faster R-CNN的网络结构, 先通过RPN(H0,C0,B0)得到一些候选框,然后再进一步的对这些框进行修正边框B1,和分类C1
-
图(b)Iterative BBox是级联的分类器和回归器, 只是在Inference时进行级联,也就是说这些分类器和回归器本质上还是对于初始化输入的那些候选区域训练的,和之前的操作没有什么区别,而且,从之前IOU的输入输出曲线上可以看到,高IOU的输入在经过低quality的回归器后,IOU反而会降低,造成负的效果。
-
图(c)Intergral Loss, 在roi-pooling之后,根据IOU将样本分成不同的集合,不同IOU的样本进入不同的分类器,但是回归器只有一个。这么做的目的是为了提高分类的精度,对不同IOU的样本采用不同的分类器,但是一方面,高IOU的样本其实非常少,那么高IOU的分类器就不能被充分的训练。另一方面一个回归器也难以对所有IOU的输入都表现良好 。

-
图(d)是本文提出的方法Cascade R-CNN,
Cascade R-CNN
-
回归函数:

- 其中 T T T 为级联的层数
-
与Iterative BBox的不同:
- Iterative BBox是用于改进边界框的后处理过程,Cascade R-CNN是一个重新采样的过程, 改变了不同阶段处理的假设的分布。
- Cascade R-CNN同时用于训练和推断,因此训练和推断分布没有差异。
- 多元回归器 f T , f T − 1 ⋅ ⋅ ⋅ , f 1 f_{T},f_{T-1}···,f_1 fT,fT−1⋅⋅⋅,f1进行了优化,得到了不同阶段的重采样分布。这与Iterative BBox的只对初始分布是最优的单个f相反。这些差异使得它比迭代BBox定位更精确。
损失函数
- 在每个阶段 t t t , R-CNN包括一个分类器 h t h_t ht 和一个为loU阈值 u t u^t ut 优化的回归器 f t f_t ft ,其中 u t > u t − 1 u_t>u_{t-1} ut>ut−1。

- 其中, b t = f t − 1 ( x t − 1 , b t − 1 ) b_t = f_{t-1}(x^{t-1},b^{t-1}) bt=ft−1(xt−1,bt−1), g g g 是 x t x^t xt 的Ground Truth, λ = 1 λ=1 λ=1是权衡系数,[·]是指示函数, y t y^t yt是通过 (3) 中 $u^t 得 到 的 得到的 得到的x^t$的标签。
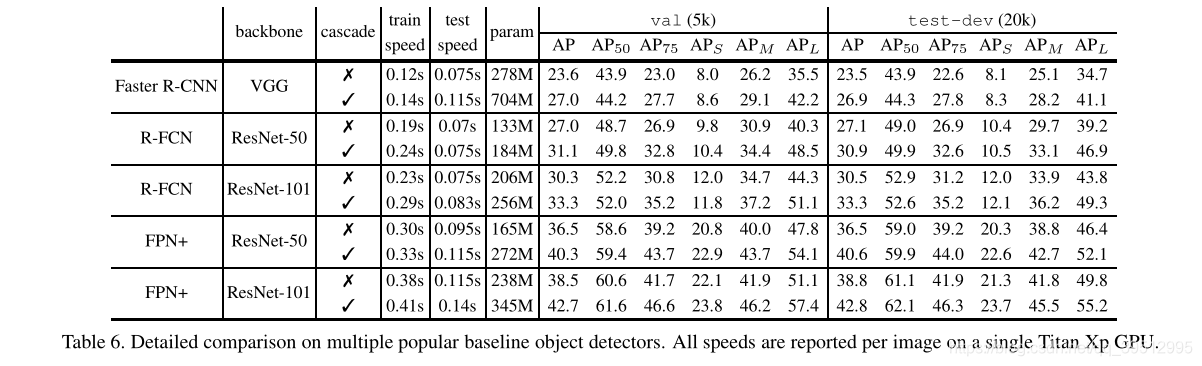
Experimental Results
-
网络结构:VGG为backbone的Faster R-CNN,以及以ResNet为backbone的 R-FCN和FPN
-
下图(a)中的实线表示在不同阈值下训练的检测器的AP曲线,虚线表示用更高质量的级联R-CNN提议代替原来的检测器提议(u=0.6, u=0.7分别使用了第二阶段提议和第三阶段提议)
-
下图(b)中将部分Ground Truth添加到了推荐候选框里, 虽然所有检测器都有所改进,但u=0.7的检测器收益最大,几乎在所有IOU级别上都取得了最佳性能。
-
结论:
- u=0.5不是精确检测的好选择,只是对低质量的提议更健壮。
- 高度精确的检测需要与检测器质量相匹配的候选框。
- 当测试提议候选框与检测器质量更接近时,检测器的性能会显著提高。

-
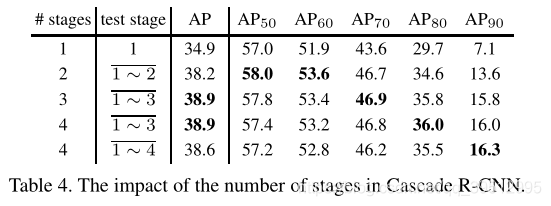
下图表示所有级联R-CNN检测器在各个级联阶段的检测性能。
- 即使使用相同的提议 ,图6中联合训练的检测器的性能也优于图5(a)中单独训练的检测器。这说明在级联R-CNN框架下,检测器得到了更好的训练。

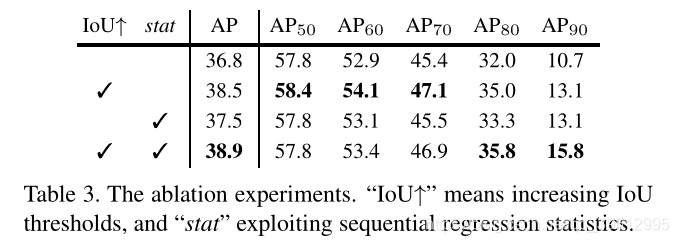
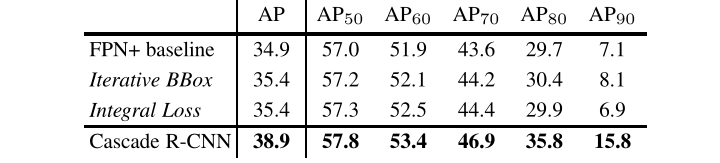
- :图7(a)对比了级联回归和迭代BBox的定位性能。单一回归器的使用降低了高 loU假设的定位性能。当迭代地应用回归变量(如在迭代BBox中)时,这种效果会累积,并且性能实际上会下降。注意经过3次迭代后,迭代BBox的性能非常差。相反,级联回归器在后期具有更好的性能,在几乎所有的loU级别上都优于迭代BBox。
- 共享一个回归变量的Intergral Loss检测器中所有分类器的检测性能如图7(b)所示。在各loU层中,u=0.6的分类器是最好的,而u=0.7的分类器是最差的。所有分类器的集合没有显示任何可见的增益。

Conclusion
Cascade R-CNN其实主要解决了两个问题:
- 一个是不同IOU的输入框的分布不同,需要不同的分类器和回归器。
- 另一个是随机生成的框中高IOU的样本太少,难以充分训练。
Cascade的结构同时解决了这两个问题,虽然方法很简单,但是其中蕴含了对目标检测任务的观察和深刻理解,可以很容易的应用到其他的检测方法上,最后效果也非常好,比当时最好的结果提升了4个点。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









