







梯度下降算法
穷举法和观察法不可行,因为w的数量如果过大,将会大大增加时间开销且可能找到局部最优解
梯度下降:(能够找到局部最优解,但也许找不到全局最优解(没有任何一个局部最优比他好))
那么为什么深度学习中大多数还是使用梯度下降来寻找最优解,因为在很多学习中得到结果,深度学习最优化问题中并不存在很多局部最优解。
但存在一个点(鞍点,偏导为0)
y
=
w
x
+
b
y=wx+b
y=wx+b
MSE:
c
o
s
t
(
w
)
=
1
N
∑
n
=
1
N
(
y
^
n
−
y
n
)
2
cost(w)=\frac{1}{N}\sum_{n=1}^{N}{(\hat{y}_n-y_n)^2}
cost(w)=N1n=1∑N(y^n−yn)2
优化目标:
w
∗
=
arg min
w
c
o
s
t
(
w
)
w^*=\argmin_{w}{cost(w)}
w∗=wargmincost(w)
求导数:
∂
c
o
s
t
∂
w
\frac{\partial cost}{\partial w}
∂w∂cost
update:
w
=
w
−
α
∂
c
o
s
t
∂
w
,
w=w-\alpha \frac{\partial cost}{\partial w},
w=w−α∂w∂cost,
α
是
学
习
率
(
步
长
)
\alpha 是学习率(步长)
α是学习率(步长)
然后就是迭代就最优的过程:
∂
c
o
s
t
∂
w
=
∂
1
N
∑
n
=
1
N
(
x
n
⋅
w
−
y
n
)
2
∂
w
\frac{\partial cost}{\partial w}=\frac{\partial \frac{1}{N} \sum_{n=1}^{N}(x_n\cdot w-y_n)^2}{ \partial w}
∂w∂cost=∂w∂N1∑n=1N(xn⋅w−yn)2
=
1
N
∑
n
=
1
N
∂
(
x
n
⋅
w
−
y
n
)
2
∂
w
=\frac{1}{N}\sum_{n=1}^{N}{\frac{\partial (x_n\cdot w-y_n)^2}{\partial w}}
=N1n=1∑N∂w∂(xn⋅w−yn)2
=
1
N
∑
n
=
1
N
2
⋅
(
x
n
⋅
w
−
y
n
)
∂
(
x
n
⋅
w
−
y
n
)
∂
w
=\frac{1}{N}\sum_{n=1}^{N}{2\cdot (x_n\cdot w-y_n)\frac{\partial (x_n\cdot w-y_n)}{\partial w}}
=N1n=1∑N2⋅(xn⋅w−yn)∂w∂(xn⋅w−yn)
=
1
N
∑
n
=
1
N
2
⋅
x
n
⋅
(
x
n
⋅
w
−
y
n
)
=\frac{1}{N}\sum_{n=1}^{N}{2\cdot x_n\cdot (x_n\cdot w-y_n)}
=N1n=1∑N2⋅xn⋅(xn⋅w−yn)
Update:
w
=
w
−
α
1
N
∑
n
=
1
N
2
⋅
x
n
⋅
(
x
n
⋅
w
−
y
n
)
w=w-\alpha\frac{1}{N}\sum_{n=1}^{N}{2\cdot x_n\cdot (x_n\cdot w-y_n)}
w=w−αN1n=1∑N2⋅xn⋅(xn⋅w−yn)
代码:
import random
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = random.random() # 随机初始化初始权重
def forward(x):
"""
定义的线性模型
"""
return x * w
def cost(x, y):
"""
损失函数
"""
cost = 0
for x_i, y_i in zip(x, y):
y_pred = forward(x_i)
cost += (y_pred - y_i) ** 2
return cost / (len(x))
def gradient(x, y):
grad = 0
for x_i, y_i in zip(x, y):
grad += 2 * x_i * (x_i * w - y_i)
return grad / (len(x))
epoch_list = []
cost_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
epoch_list.append(epoch)
cost_list.append(cost_val)
print("epoch:", epoch, "w:", w, "loss(MSE):", cost_val)
print("Predict:", forward(4))
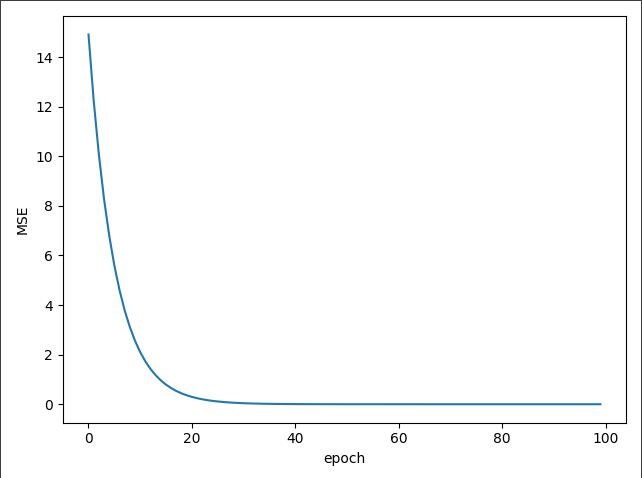
plt.plot(epoch_list, cost_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
误差随着训练轮次的增加逐渐减少


















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









