







 本文主要介绍Python中生成器、迭代器及for循环相关知识。生成器创建后不占内存,可通过next()、send()等方法取数,节省内存;迭代器需满足特定条件,可由可迭代对象转化;for循环本质上遍历的是迭代器。
本文主要介绍Python中生成器、迭代器及for循环相关知识。生成器创建后不占内存,可通过next()、send()等方法取数,节省内存;迭代器需满足特定条件,可由可迭代对象转化;for循环本质上遍历的是迭代器。
Python中常见的可迭代对象,有list,tuple,dict,set。而关于list,有一个列表生成式:
a = [i for i in range(10)]
通过这种方法,可以声明一个1~9的列表,而且,可以在第一个参数传入一个方法,如:
def f(x):
return x*x
a = [f(x) for x in range(10)]
这样,就返回了一个1~9平方的列表。
但是,如果把中括号换成小括号,会怎么样呢?
1、生成器
a = (x for x in range(10))
将a输出一下:
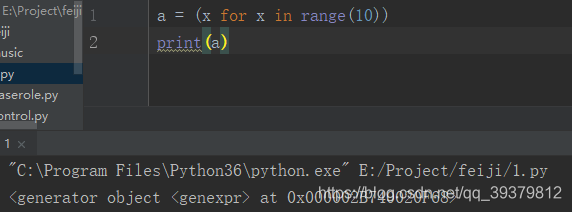
可以看到的是,它输出了一个地址,而这个地址是生成器对象的(generator)。当对它进行for循环遍历,是可以的。而然,这非重点。
生成器最大的特点就是,生成器对象创建之后,没有任何数据写入到内存。
Python3中,生成器有一个内置的方法__next__(),或者用python内置的方法next()它可以从生成器取出一个数,而取数的方法有三个特点:
1.生成器内部没有存储任何数据,当调用__next__()方法后,它就会通过cpu计算返回一个值,也就是说,调用一个next()方法后才会产生一个数据,不调用则不会产生 。
2.使用next()或者__next__()方法取出数据后,会保存当前的状态,下一次调用next()方法后,返回的数据是上次调用next()返回数据的后一个。
3.使用这种方法遍历,只能按照从前到后的顺序进行遍历,不能进行倒序。而且,当遍历完之后再次调用next()方法,就会抛出一个StopIteration异常。
关于生成器调用next()再产生数据的优点:
for i in range(1000000000000):
pass
a = (x for x in range(1000000000000)):
pass
第一种方法会先在内存创建这么多的数字,然后再进行遍历。很显然,内存会被占用很多。而用生成器的话,因为在垃圾回收机制的原因下,取出一个数之后,这个数没有被使用,那么内存中这个数就会被清掉,可以说极大的节省了内存。
其实,还有创建生成器的另一种方式,就是使用yield关键字
def f():
print("haha")
yield 1
print("yingyingying")
yield 2
a = f()
print(next(a))
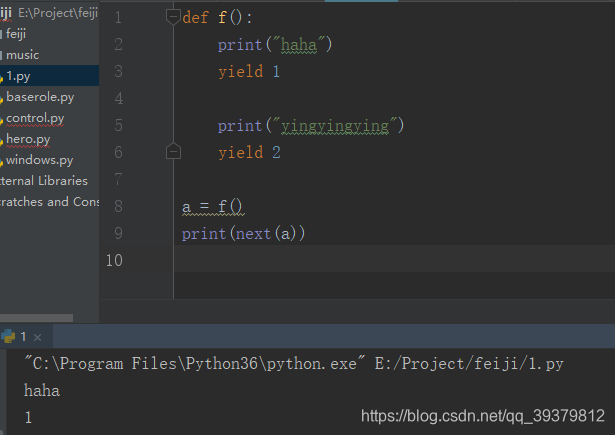
通过a接受生成器对象,对a进行next()遍历后,只有1被返回了。其实,yield的作用相当于return,不过区别就是,当执行到这一句的时候,它就会从这一状态退出并且保存这一状态。通俗的来说,就是从函数体内退出然后保存状态,当我下次调用的话就继续从这一个状态执行。当然,遍历完成后再执行next()也还是会报错的。
除了for循环和next()方法,还有一个方法可以遍历生成器,就是yield的内置方法send()。
send方法和next方法的区别就是,send方法接受一个生成器对象返回的数据的同时,可以修改前一个数据:
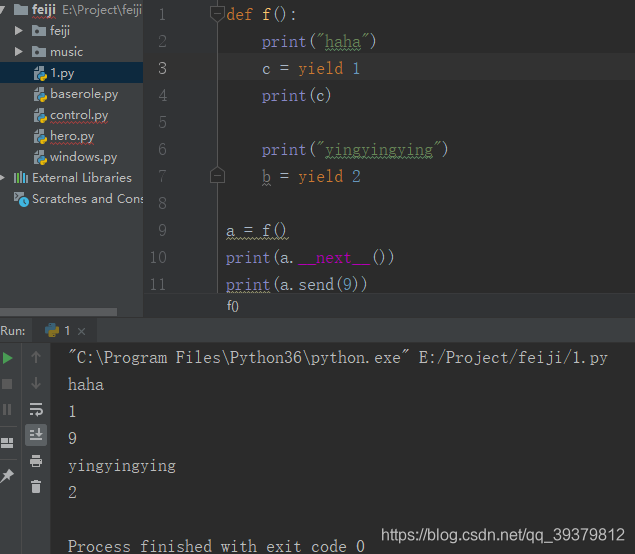
可以看到,在函数体内对yield修饰的变量进行赋值后,调用send后c的值变成了9。
这里有一个非常非常重要的点:
第一次调用send前没有调用next方法,必须只能传None
结合列表的思想,就是边界问题。send方法是返回当前指向的数值,然后修改上一个数值。但是第一个因为边界是修改不了的,会产生报错。所以如果调用第一个send方法就要在之前使用next()或者传入None。
2、迭代器
迭代器需要满足两个条件:
1、内部有__iter__方法
2、内部有__next__方法
而可迭代对象只需满足一个条件,即:
1、内部有__iter__方法
使用内置的iter()方法可以将一个可迭代对象转化一个迭代器。而关于生成器,迭代器和可迭代对象的关系:
生成器<迭代器<可迭代对象
3、for和迭代器
for循环的工作原理是怎样的呢?
1、使用iter()方法将一个可迭代对象变成一个迭代器
2、一直调用next()方法
3、检测异常
所以,说for遍历的是一个可迭代对象,其实严格意义上来说应该是遍历一个迭代器

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









