









 本文详细介绍了Redis的内存操作原理、高速查询性能、常见应用场景(如缓存、排行榜和消息队列),以及其持久化策略(RDB和AOF)、事务和主从复制机制,展示了Redis在高可用性方面的哨兵模式。
本文详细介绍了Redis的内存操作原理、高速查询性能、常见应用场景(如缓存、排行榜和消息队列),以及其持久化策略(RDB和AOF)、事务和主从复制机制,展示了Redis在高可用性方面的哨兵模式。
前言
在我们开发的几乎每一个项目中,都会用到redis,大多数人都知道它是用来做缓存的,能够提高查询性能,很快。但是它到底是如何提高查询性能的呢?为什么快呢?它的作用仅仅是提高查询性能吗?本篇文章将带大家走进redis。看完这篇文章,你将会轻松的把redis纳入你的知识储备。
文章目录
什么是 Redis
Redis (remote dictionary server)是一个高性能的key-value数据库。它是内存中的数据结构存储系统,可以用作数据库、缓存和消息中间件。
附加描述:开源、遵守BSD协议、基于内存、使用C语言编写。。。
redis是NoSQL(not only sql)非关系型数据库,与传统关系型数据库对比:
NoSQL数据库: 不用事先为要存储的数据建立字段,随时可以存储自定义的数据格式
关系数据库: 在关系型数据库中,对于大数据量的表,增删改字段是非常耗费性能的
Redis 为什么这么快
单机的Redis就可以⽀撑每秒十几万的并发,性能是MySQL的几十倍
它快的原因有以下几点:
- 完完全全基于内存操作,数据读写都在内存中完成
(最主要的原因就是这个) - 基于非阻塞的I/O多路复用机制
- 使用C语言实现,redis在基础的数据结构上,做了大量的优化
Redis 的常见应用场景
- 缓存
这是最多的使用场景。一些频繁被访问的数据,如果放在关系型数据库,每次查询的开销都会很大,由于数据库的IO比较慢,响应就会比较差,比如查询一个数据量庞大的商品列表,却要加载好几十秒,用户的体验感极差。但是如果放在redis中是可以解决这个问题的,因为它是基于内存的, 可以很高效的访问。 - 排行榜
Redis提供了sorted set(排序集合)的功能,比如通过将用户行为数据记录下来,如点赞数、评论数等,然后通过 sorted set数据类型来排序。如果使用传统的关系型数据库会非常的麻烦,而利用Redis的sorted set数据结构能够轻松的搞定;现在很多游戏都用redis来实现各种排行榜。 - 计算器/限速器
这是利用Redis中原子性的自增操作,比如用户的点赞、访问等操作是非常频繁的,如果使用关系型数据库,频繁的读写操作会给数据库带来很大的压力,采用redis的话只需要执行一次 INCR 命令即可,并且能够保证在高并发场景下的数据一致性。限速器比较典型的使用场景是限制某个用户访问某个接口的频率,比如在演唱会抢票时用户会疯狂的点击抢票按钮,通过redis限速的话就可以避免给服务器带来比较大的压力。 - 消息队列
生产者将消息存入队列中,消费者从队列中取出消息进行处理。通过使用 Redis 的 发布/订阅功能来实现消息的发布和订阅,保证了消息传递的可靠性和高效性。 - Session共享
一般的web项目来说,Session是默认保存在服务器的文件中,在集群服务上,同一个用户访问会在不同机器上,这就会导致用户频繁登录;如果采用Redis保存Session后,无论用户的访问被集群中的任何一台机器响应,服务器都能够获取到对应的Session信息。 - 分布式锁
通过设置唯一的key-value来控制访问某个资源的并发数,当一个客户端需要访问该资源时,先去获取分布式锁,执行完后再释放锁,可以保证同一时间只有一个客户端在访问该资源,这种方式可以有效避免因为并发访问而导致的数据冲突和竞争问题。
Redis 的五种数据类型
String
字符串类型的值可以是字符串、数字、二进制;值最大不能超过512MB。
应用场景:缓存、计数、共享Session、限速器
list
存储多个有序的字符串。
应用场景:消息队列
set
存储多个无序且不重复的字符串。
应用场景:标签
hash
就类似于java里面的Map<String,Object>,hash类型本身就是一个键值对结构,redis这边的话,key-value的模式是不变的,不过就是value里面存储的也是一个kv键值对。
应用场景:缓存用户信息、缓存对象
sorted set
满足集合唯一性的要求,同时也满足有序的性质;有序集合是集合的一部分,有序集合给每个元素多设置了一个分数,相当于多了一个维度,redis 也是利用这个维度进行排序的。
应用场景:排行榜
Redis 的持久化策略
其实大家不禁会问,redis中存储的数据都是在自己进程的内存中,那如果服务器挂了,或者停电了,存储的数据不就全部没了?其实不必担心,是不会的;redis有自己的持久化策略,持久化操作就是把数据从内存备份到硬盘文件,在内存数据丢失的情况下,可以从硬盘恢复。redis提供了两种持久化策略:RDB和AOF。
RDB
RDB 全称 Redis DataBase,它是在指定的时间间隔内,将内存中的数据全部保存到磁盘文件,默认保存在/usr/local/bin/dump.rdb。没错,RDB就是dump.rdb这个持久化文件的后缀名,它没看起来那么复杂。
RDB可以进行自动备份或者手动备份:
自动备份在redis.conf文件中自动备份的配置默认是开启的,所有它会自动将数据备份到dump.rdb文件中,服务器开启时会从dump.rdb恢复到redis,这就是为什么我们关闭再开启服务器时,redis中的数据还在的原因。当然,如果只是使用redis的缓存功能,不要持久化的话,可以将这个配置关闭。
手动备份的话就是在执行完每次操作之后都执行一些save命令就好了。(用的不多)
RDB的优缺点:
优点:适合大规模数据恢复,对数据完整性和一致性要求不高
缺点:因为是间隔备份,意外宕机的话,最后一次的数据是无法写入文件的
AOF
AOF 全称 Append Only File,它是将redis执行过的写指令以追加文件的形式全部记录下来(读操作不记录),redis在启动时会读取该文件,这样可以重新构建数据。
AOF 默认是不开启的,需要在配置文件redis.conf中配置开启参数,配置完之后需要重启redis才能生效。
appendonly yes
appendfilename appendonly.aof
appendfsync:everysec
appendfsync 追加策略:
always:每次数据变更,就会立即记录到磁盘,性能较差,但数据完整性好
everysec:默认设置,异步操作,每秒记录,如果一秒内宕机,会有数据丢失
no:不追写
然后进行了一系列的写操作之后,也就是往redis中保存的大量数据,再关闭服务。这时候会出现一个新文件appendonly.aof,然后只要重新启动服务,数据就会恢复。
AOF的优缺点:
优点:数据完整性高
缺点:写操作太多,性能消耗太大
优先使用RDB还是AOF呢?
RDB和AOF是能够共存的,也就是
redis.conf文件中可以同时将它们开启,并且是优先使用AOF来恢复数据的,因为AOF的数据完整性较高。
在实际的生产环境中,就是在企业级的大项目中,主要还是使用AOF,因为它的数据完整性高啊,即使意外宕机,它丢失的数据也就那1秒的数据,但是对服务器的性能要求比较高,并且对硬盘的要求也比较高,一般的64mb肯定是不够用的,起码要5G以上,所以现在大多都采用主从(master/slave)。然后对于RDB的话备用就好,建议设置15分钟左右备份一次。
Redis 事务
Redis 事务是一组命令的集合
三大特性:
- 隔离性:所有命令都会按照顺序执行,事务在执行的过程中,不会被其他客户端送来的命令打断
- 没有隔离级别:队列中的命令没有提交之前都不会被实际的执行
- 不保证原子性:如果一个命令失败,但是别的命令可能会执行成功,不回滚
三个主要命令:
开启multi、执行exec、丢弃discard
分别可以理解为关系型数据库里的begin、commit、rollback
开启事务,加入队列,一起执行,全部成功:
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set key1 value1
QUEUED # 加入队列
127.0.0.1:6379> set key2 value2
QUEUED # 加入队列
127.0.0.1:6379> get key2
QUEUED # 加入队列
127.0.0.1:6379> exec # 执行,全部成功!
1) OK
2) OK
3) "value2"
开启事务,加入队列,废弃,数据不会被改动:
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set key1 aaa
QUEUED
127.0.0.1:6379> set key2 bbb
QUEUED
127.0.0.1:6379> discard # 丢弃
OK
127.0.0.1:6379> get key2
"value2" # 还是原来的值
队列中存在语法性错误,一个命令失败,但是别的命令可能会执行成功,不回滚:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr key1 # incr是自增命令,虽然v1不能++,但是加入队列并不会报错
QUEUED
127.0.0.1:6379> set key3 value3
QUEUED
127.0.0.1:6379> set key4 value4
QUEUED
127.0.0.1:6379> exec
1) (error) ERR value is not an integer or out of range # 执行的时候,刚才的incr key1会报错
2) OK # 成功
3) OK # 成功
127.0.0.1:6379> get key3
"value3" # 说明报错并没有影响成功的命令
127.0.0.1:6379> get key4
"value4"
队列中如果存在命令性错误,只要有一句报错,那么全部都取消:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set key5 value5
QUEUED
127.0.0.1:6379> setahhaahh # 无效命令,会报错
(error) ERR unknown command `setahhaahh`, with args beginning with:
127.0.0.1:6379> set key6 value6
QUEUED
127.0.0.1:6379> exec # 执行报错队列中命令全部取消
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> keys * #没有key5和key6,说明因为命令性错误的报错,全部都取消了
1) "key1"
2) "key2"
3) "key3"
4) "key4"
Redis 主从复制
这边介绍两种常用的模式:一主一从、一主多从
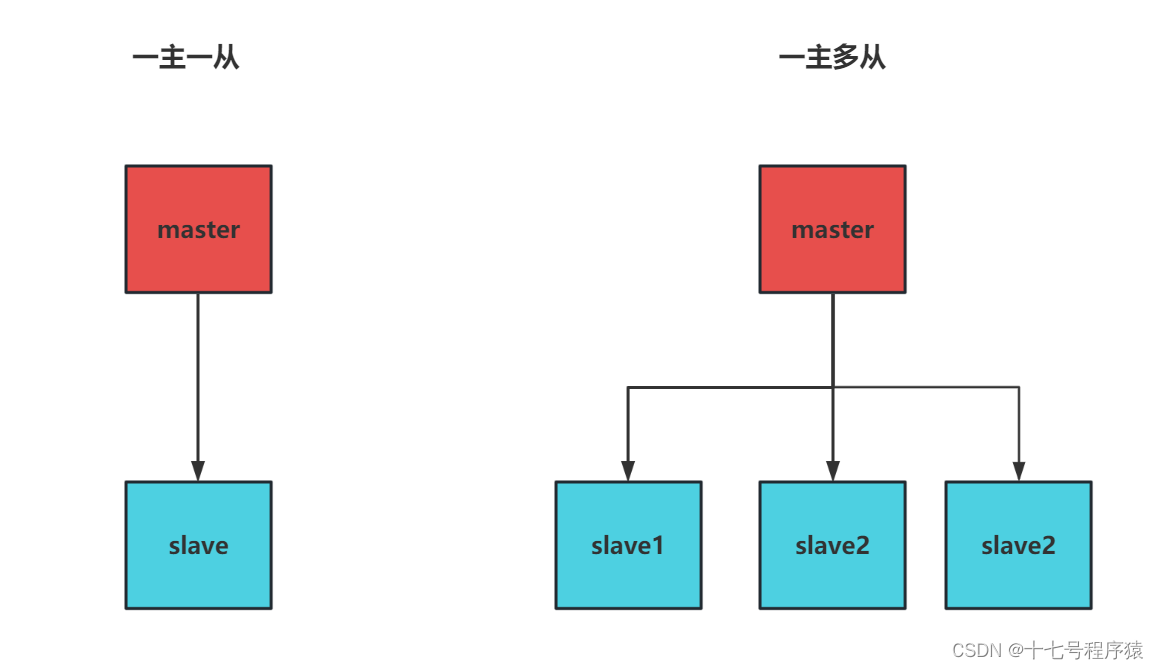
一主一从:当主节点宕机时,从节点转变成主节点继续服务
一主多从:redis的主从复制就是redis的集群模式,是一种读写分离的形式,主负责写,从负责读。所有的查询请求都在slave上进行响应,降低master的负载
原理
主要是分为全量复制和增量复制,slave在刚刚连接上master时,也就是在初始阶段,会进行全量复制(slave将master的全部数据复制到自己的数据文件中,并加载到内存中),之后再进行增量同步(将master的写操作复制到slave中)
优缺点:
优点:高并发,高可扩,高性能
缺点:因为所有的写都是在master完成的,同步到各个slave时会有通信延迟,那么数据的一致性会有影响
哨兵模式
哨兵模式可以实现redis主从模式下的高可用,哨兵就是字面上的意思,引用一个比较有意思的解释:有个哨兵一直在巡逻,突然发现老大挂了,然后哨兵小弟们会自动投票,从众小弟中选出新的老大。也就是当master挂了之后,几个slave会在它们自己中间重新选出一个slave成为新的master来继续处理请求。
Sentinel是Redis的高可用性解决方案:
Sentinel会检测master,如果发现master异常,则会进行master-slave切换,将其中一个slave作为master,将之前的master作为slave。
结语
记住!Redis是一个key-value数据库。它是内存中的数据结构存储系统,可以用作数据库、缓存和消息中间件。
点赞收藏不迷路!


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











