







下载spark安装包:https://spark.apache.org/downloads.html
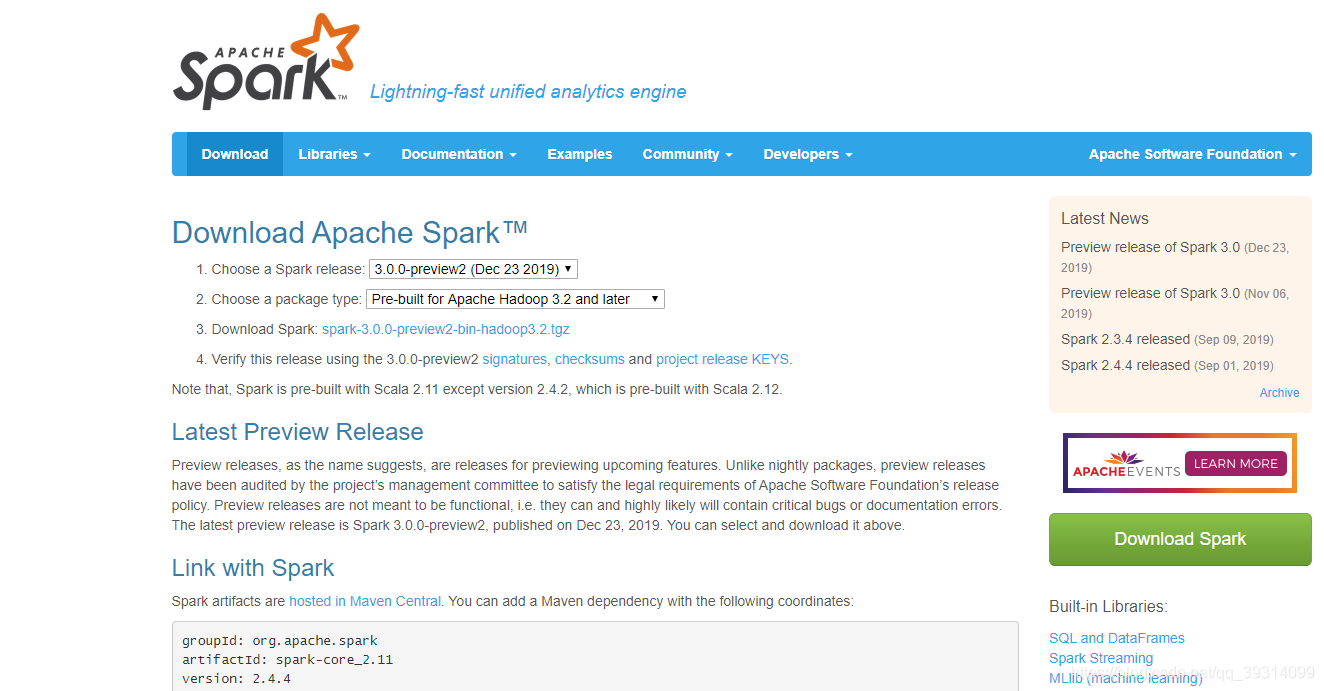
下载对应hadoop版本的spark即可。
- 解压,得到目录如下:
- 配置环境变量。依然采用在/etc/profile.d/下创建spark.sh。

- 配置spark:
进入conf文件夹,复制配置文件的模板,命名为spark-env.sh。
cp spark-env.sh.template spark-env.sh |
前提是需要配置好java、scala、hadoop。
spark-env.sh文件只需要在尾部追加一点配置:

同样复制slaves的模板,命名为slaves。
cp slaves.template slaves |
slaves需要指定集群的机器hostname,和hadoop配置过程一样。
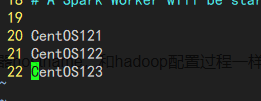
将spark文件夹发送到其他机器上。
防火墙我已经在配置hadoop的时候处理过,方法是建立了机器之间的内部信任关系。
配置hadoop地址:https://blog.youkuaiyun.com/qq_39314099/article/details/103681298
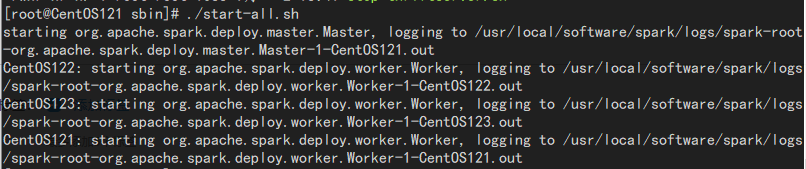
- 启动:
进入sbin目录,和hadoop一样,使用start-all.sh脚本来启动。
可以在浏览器访问:
CentOS121:8080
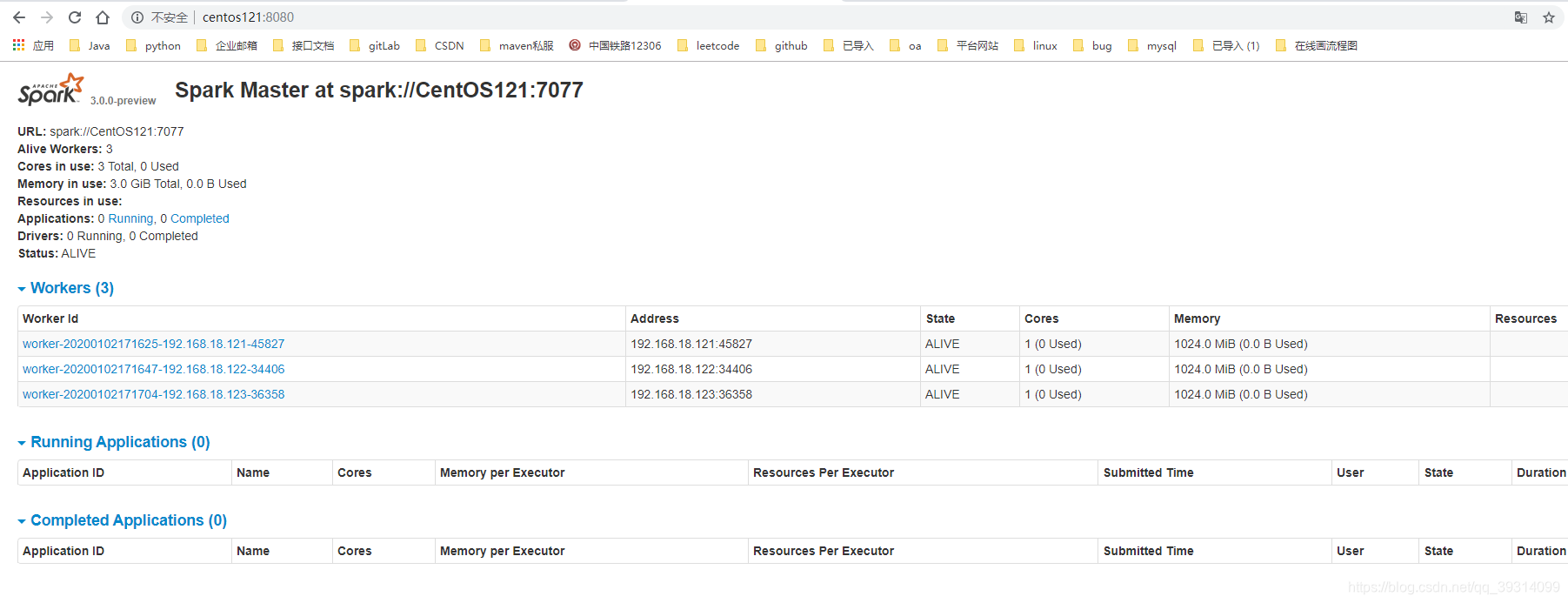
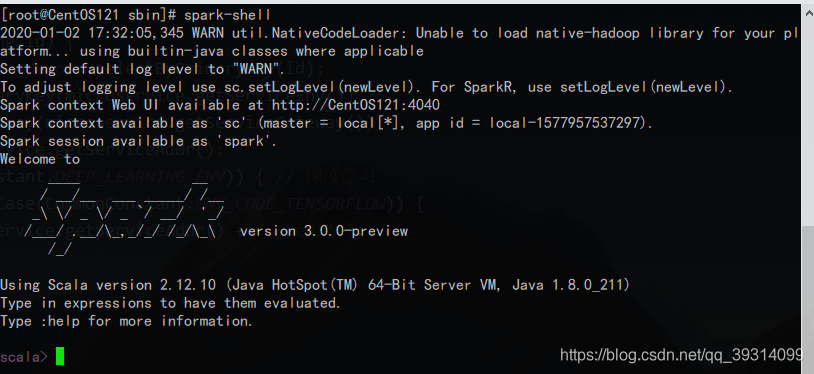
可以在命令行开启spark-shell:

















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









