/* Copyright (C) 2002 Jean-Marc Valin
File: speex_jitter.h
Adaptive jitter buffer for Speex
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions
are met:
- Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
- Neither the name of the Xiph.org Foundation nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE FOUNDATION OR
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
/*
TODO:
- Add short-term estimate
- Defensive programming
+ warn when last returned < last desired (begative buffering)
+ warn if update_delay not called between get() and tick() or is called twice in a row
- Linked list structure for holding the packets instead of the current fixed-size array
+ return memory to a pool
+ allow pre-allocation of the pool
+ optional max number of elements
- Statistics
+ drift
+ loss
+ late
+ jitter
+ buffering delay
*/
#ifdef HAVE_CONFIG_H
#include "config.h"
#endif
#include "arch.h"
#include "speex/speex_jitter.h"
#include "os_support.h"
#ifndef NULL
#define NULL 0
#endif
#define SPEEX_JITTER_MAX_BUFFER_SIZE 200 /**< Maximum number of packets in jitter buffer */
#define TSUB(a,b) ((spx_int32_t)((a)-(b)))
#define GT32(a,b) (((spx_int32_t)((a)-(b)))>0)
#define GE32(a,b) (((spx_int32_t)((a)-(b)))>=0)
#define LT32(a,b) (((spx_int32_t)((a)-(b)))<0)
#define LE32(a,b) (((spx_int32_t)((a)-(b)))<=0)
#define ROUND_DOWN(x, step) ((x)<0 ? ((x)-(step)+1)/(step)*(step) : (x)/(step)*(step))
#define MAX_TIMINGS 40
#define MAX_BUFFERS 3
#define TOP_DELAY 40
/** Buffer that keeps the time of arrival of the latest packets */
struct TimingBuffer {
int filled; /**< Number of entries occupied in "timing" and "counts"*/
int curr_count; /**< Number of packet timings we got (including those we discarded) */
spx_int32_t timing[MAX_TIMINGS]; /**< Sorted list of all timings ("latest" packets first) */
spx_int16_t counts[MAX_TIMINGS]; /**< Order the packets were put in (will be used for short-term estimate) */
};
static void tb_init(struct TimingBuffer *tb)
{
tb->filled = 0;
tb->curr_count = 0;
}
/* Add the timing of a new packet to the TimingBuffer */
static void tb_add(struct TimingBuffer *tb, spx_int16_t timing)
{
int pos;
/* Discard packet that won't make it into the list because they're too early */
if (tb->filled >= MAX_TIMINGS && timing >= tb->timing[tb->filled-1])
{
tb->curr_count++;
return;
}
/* Find where the timing info goes in the sorted list */
pos = 0;
/* FIXME: Do bisection instead of linear search */
while (pos<tb->filled && timing >= tb->timing[pos])
{
pos++;
}
speex_assert(pos <= tb->filled && pos < MAX_TIMINGS);
/* Shift everything so we can perform the insertion */
if (pos < tb->filled)
{
int move_size = tb->filled-pos;
if (tb->filled == MAX_TIMINGS)
move_size -= 1;
SPEEX_MOVE(&tb->timing[pos+1], &tb->timing[pos], move_size);
SPEEX_MOVE(&tb->counts[pos+1], &tb->counts[pos], move_size);
}
/* Insert */
tb->timing[pos] = timing;
tb->counts[pos] = tb->curr_count;
tb->curr_count++;
if (tb->filled<MAX_TIMINGS)
tb->filled++;
}
/** Jitter buffer structure */
struct JitterBuffer_ {
spx_uint32_t pointer_timestamp; /**< Timestamp of what we will *get* next */
spx_uint32_t last_returned_timestamp; /**< Useful for getting the next packet with the same timestamp (for fragmented media) */
spx_uint32_t next_stop; /**< Estimated time the next get() will be called */
spx_int32_t buffered; /**< Amount of data we think is still buffered by the application (timestamp units)*/
spx_uint32_t buffer_size;
JitterBufferPacket packets[SPEEX_JITTER_MAX_BUFFER_SIZE]; /**< Packets stored in the buffer */
spx_uint32_t arrival[SPEEX_JITTER_MAX_BUFFER_SIZE]; /**< Packet arrival time (0 means it was late, even though it's a valid timestamp) */
void (*destroy) (void *); /**< Callback for destroying a packet */
spx_int32_t delay_step; /**< Size of the steps when adjusting buffering (timestamp units) */
spx_int32_t concealment_size; /**< Size of the packet loss concealment "units" */
int reset_state; /**< True if state was just reset */
int buffer_margin; /**< How many frames we want to keep in the buffer (lower bound) */
int late_cutoff; /**< How late must a packet be for it not to be considered at all */
int interp_requested; /**< An interpolation is requested by speex_jitter_update_delay() */
int auto_adjust; /**< Whether to automatically adjust the delay at any time */
struct TimingBuffer _tb[MAX_BUFFERS]; /**< Don't use those directly */
struct TimingBuffer *timeBuffers[MAX_BUFFERS]; /**< Storing arrival time of latest frames so we can compute some stats */
int window_size; /**< Total window over which the late frames are counted */
int subwindow_size; /**< Sub-window size for faster computation */
int max_late_rate; /**< Absolute maximum amount of late packets tolerable (in percent) */
int latency_tradeoff; /**< Latency equivalent of losing one percent of packets */
int auto_tradeoff; /**< Latency equivalent of losing one percent of packets (automatic default) */
int lost_count; /**< Number of consecutive lost packets */
};
/** Based on available data, this computes the optimal delay for the jitter buffer.
The optimised function is in timestamp units and is:
cost = delay + late_factor*[number of frames that would be late if we used that delay]
@param tb Array of buffersa
@param late_factor Equivalent cost of a late frame (in timestamp units)
*/
static spx_int16_t compute_opt_delay(JitterBuffer *jitter)
{
int i;
spx_int16_t opt=0;
spx_int32_t best_cost=0x7fffffff;
int late = 0;
int pos[MAX_BUFFERS];
int tot_count;
float late_factor;
int penalty_taken = 0;
int best = 0;
int worst = 0;
spx_int32_t deltaT;
struct TimingBuffer *tb;
tb = jitter->_tb;
/* Number of packet timings we have received (including those we didn't keep) */
tot_count = 0;
for (i=0;i<MAX_BUFFERS;i++)
tot_count += tb[i].curr_count;
if (tot_count==0)
return 0;
/* Compute cost for one lost packet */
if (jitter->latency_tradeoff != 0)
late_factor = jitter->latency_tradeoff * 100.0f / tot_count;
else
late_factor = jitter->auto_tradeoff * jitter->window_size/tot_count;
/*fprintf(stderr, "late_factor = %f\n", late_factor);*/
for (i=0;i<MAX_BUFFERS;i++)
pos[i] = 0;
/* Pick the TOP_DELAY "latest" packets (doesn't need to actually be late
for the current settings) */
for (i=0;i<TOP_DELAY;i++)
{
int j;
int next=-1;
int latest = 32767;
/* Pick latest among all sub-windows */
for (j=0;j<MAX_BUFFERS;j++)
{
if (pos[j] < tb[j].filled && tb[j].timing[pos[j]] < latest)
{
next = j;
latest = tb[j].timing[pos[j]];
}
}
if (next != -1)
{
spx_int32_t cost;
if (i==0)
worst = latest;
best = latest;
latest = ROUND_DOWN(latest, jitter->delay_step);
pos[next]++;
/* Actual cost function that tells us how bad using this delay would be */
cost = -latest + late_factor*late;
/*fprintf(stderr, "cost %d = %d + %f * %d\n", cost, -latest, late_factor, late);*/
if (cost < best_cost)
{
best_cost = cost;
opt = latest;
}
} else {
break;
}
/* For the next timing we will consider, there will be one more late packet to count */
late++;
/* Two-frame penalty if we're going to increase the amount of late frames (hysteresis) */
if (latest >= 0 && !penalty_taken)
{
penalty_taken = 1;
late+=4;
}
}
deltaT = best-worst;
/* This is a default "automatic latency tradeoff" when none is provided */
jitter->auto_tradeoff = 1 + deltaT/TOP_DELAY;
/*fprintf(stderr, "auto_tradeoff = %d (%d %d %d)\n", jitter->auto_tradeoff, best, worst, i);*/
/* FIXME: Compute a short-term estimate too and combine with the long-term one */
/* Prevents reducing the buffer size when we haven't really had much data */
if (tot_count < TOP_DELAY && opt > 0)
return 0;
return opt;
}
/** Initialise jitter buffer */
EXPORT JitterBuffer *jitter_buffer_init(int step_size)
{
JitterBuffer *jitter = (JitterBuffer*)speex_alloc(sizeof(JitterBuffer));
if (jitter)
{
int i;
spx_int32_t tmp;
for (i=0;i<SPEEX_JITTER_MAX_BUFFER_SIZE;i++)
jitter->packets[i].data=NULL;
jitter->delay_step = step_size;
jitter->concealment_size = step_size;
/*FIXME: Should this be 0 or 1?*/
jitter->buffer_margin = 0;
jitter->late_cutoff = 50;
jitter->destroy = NULL;
jitter->latency_tradeoff = 0;
jitter->auto_adjust = 1;
jitter->buffer_size = SPEEX_JITTER_MAX_BUFFER_SIZE;
tmp = 4;
jitter_buffer_ctl(jitter, JITTER_BUFFER_SET_MAX_LATE_RATE, &tmp);
jitter_buffer_reset(jitter);
}
return jitter;
}
/** Reset jitter buffer */
EXPORT void jitter_buffer_reset(JitterBuffer *jitter)
{
int i;
for (i=0;i<SPEEX_JITTER_MAX_BUFFER_SIZE;i++)
{
if (jitter->packets[i].data)
{
if (jitter->destroy)
jitter->destroy(jitter->packets[i].data);
else
speex_free(jitter->packets[i].data);
jitter->packets[i].data = NULL;
}
}
/* Timestamp is actually undefined at this point */
jitter->pointer_timestamp = 0;
jitter->next_stop = 0;
jitter->reset_state = 1;
jitter->lost_count = 0;
jitter->buffered = 0;
jitter->auto_tradeoff = 32000;
for (i=0;i<MAX_BUFFERS;i++)
{
tb_init(&jitter->_tb[i]);
jitter->timeBuffers[i] = &jitter->_tb[i];
}
/*fprintf (stderr, "reset\n");*/
}
/** Destroy jitter buffer */
EXPORT void jitter_buffer_destroy(JitterBuffer *jitter)
{
jitter_buffer_reset(jitter);
speex_free(jitter);
}
/** Take the following timing into consideration for future calculations */
static void update_timings(JitterBuffer *jitter, spx_int32_t timing)
{
if (timing < -32767)
timing = -32767;
if (timing > 32767)
timing = 32767;
/* If the current sub-window is full, perform a rotation and discard oldest sub-widow */
if (jitter->timeBuffers[0]->curr_count >= jitter->subwindow_size)
{
int i;
/*fprintf(stderr, "Rotate buffer\n");*/
struct TimingBuffer *tmp = jitter->timeBuffers[MAX_BUFFERS-1];
for (i=MAX_BUFFERS-1;i>=1;i--)
jitter->timeBuffers[i] = jitter->timeBuffers[i-1];
jitter->timeBuffers[0] = tmp;
tb_init(jitter->timeBuffers[0]);
}
tb_add(jitter->timeBuffers[0], timing);
}
/** Compensate all timings when we do an adjustment of the buffering */
static void shift_timings(JitterBuffer *jitter, spx_int16_t amount)
{
int i, j;
for (i=0;i<MAX_BUFFERS;i++)
{
for (j=0;j<jitter->timeBuffers[i]->filled;j++)
jitter->timeBuffers[i]->timing[j] += amount;
}
}
/** Put one packet into the jitter buffer */
EXPORT void jitter_buffer_put(JitterBuffer *jitter, const JitterBufferPacket *packet)
{
spx_uint32_t i,j;
int late;
/*fprintf (stderr, "put packet %d %d\n", timestamp, span);*/
/* Cleanup buffer (remove old packets that weren't played) */
if (!jitter->reset_state)
{
for (i=0;i<jitter->buffer_size;i++)
{
/* Make sure we don't discard a "just-late" packet in case we want to play it next (if we interpolate). */
if (jitter->packets[i].data && LE32(jitter->packets[i].timestamp + jitter->packets[i].span, jitter->pointer_timestamp))
{
/*fprintf (stderr, "cleaned (not played)\n");*/
if (jitter->destroy)
jitter->destroy(jitter->packets[i].data);
else
speex_free(jitter->packets[i].data);
jitter->packets[i].data = NULL;
}
}
}
/*fprintf(stderr, "arrival: %d %d %d\n", packet->timestamp, jitter->next_stop, jitter->pointer_timestamp);*/
/* Check if packet is late (could still be useful though) */
if (!jitter->reset_state && LT32(packet->timestamp, jitter->next_stop))
{
update_timings(jitter, ((spx_int32_t)packet->timestamp) - ((spx_int32_t)jitter->next_stop) - jitter->buffer_margin);
late = 1;
} else {
late = 0;
}
/* For some reason, the consumer has failed the last 20 fetches. Make sure this packet is
* used to resync. */
if (jitter->lost_count>20)
{
jitter_buffer_reset(jitter);
}
/* Only insert the packet if it's not hopelessly late (i.e. totally useless) */
if (jitter->reset_state || GE32(packet->timestamp+packet->span+jitter->delay_step, jitter->pointer_timestamp))
{
/*Find an empty slot in the buffer*/
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data==NULL)
break;
}
/*No place left in the buffer, need to make room for it by discarding the oldest packet */
if (i==jitter->buffer_size)
{
int earliest=jitter->packets[0].timestamp;
i=0;
for (j=1;j<jitter->buffer_size;j++)
{
if (!jitter->packets[i].data || LT32(jitter->packets[j].timestamp,earliest))
{
earliest = jitter->packets[j].timestamp;
i=j;
}
}
if (jitter->destroy)
jitter->destroy(jitter->packets[i].data);
else
speex_free(jitter->packets[i].data);
jitter->packets[i].data=NULL;
/*fprintf (stderr, "Buffer is full, discarding earliest frame %d (currently at %d)\n", timestamp, jitter->pointer_timestamp);*/
}
/* Copy packet in buffer */
if (jitter->destroy)
{
jitter->packets[i].data = packet->data;
} else {
jitter->packets[i].data=(char*)speex_alloc(packet->len);
for (j=0;j<packet->len;j++)
jitter->packets[i].data[j]=packet->data[j];
}
jitter->packets[i].timestamp=packet->timestamp;
jitter->packets[i].span=packet->span;
jitter->packets[i].len=packet->len;
jitter->packets[i].sequence=packet->sequence;
jitter->packets[i].user_data=packet->user_data;
if (jitter->reset_state || late)
jitter->arrival[i] = 0;
else
jitter->arrival[i] = jitter->next_stop;/*预计下一个被调用时间*/
} else {
/* The original version of libspeex-dsp leaks packets when we
* get here, since the application has no way of knowing whether
* a packet was actually queued or not: as such, when this
* happens, we destroy the packet that was passed ourselves */
if (jitter->destroy)
jitter->destroy(packet->data);
}
}
/** Get one packet from the jitter buffer */
EXPORT int jitter_buffer_get(JitterBuffer *jitter, JitterBufferPacket *packet, spx_int32_t desired_span, spx_int32_t *start_offset)
{
spx_uint32_t i;
unsigned int j;
spx_int16_t opt;
if (start_offset != NULL)
*start_offset = 0;
/* Syncing on the first call */
if (jitter->reset_state)
{
int found = 0;
/* Find the oldest packet */
spx_uint32_t oldest=0;
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data && (!found || LT32(jitter->packets[i].timestamp,oldest)))
{
oldest = jitter->packets[i].timestamp;
found = 1;
}
}
if (found)
{
jitter->reset_state=0;
jitter->pointer_timestamp = oldest;
jitter->next_stop = oldest;
} else {
packet->timestamp = 0;
packet->span = jitter->interp_requested;
return JITTER_BUFFER_MISSING;
}
}
jitter->last_returned_timestamp = jitter->pointer_timestamp;
/* 如果存在插值请求 */
if (jitter->interp_requested != 0)
{
packet->timestamp = jitter->pointer_timestamp;
packet->span = jitter->interp_requested;
/* Increment the pointer because it got decremented in the delay update */
jitter->pointer_timestamp += jitter->interp_requested;
packet->len = 0;
/* fprintf (stderr, "Deferred interpolate\n"); */
jitter->interp_requested = 0;
jitter->buffered = packet->span - desired_span;
return JITTER_BUFFER_INSERTION;
}
/* Searching for the packet that fits best */
/* Search the buffer for a packet with the right timestamp and spanning the whole current chunk
依次尝试寻找时间戳匹配且跨度足够的数据包、时间戳更早但跨度足够的数据包、时间戳更早且部分覆盖当前块的数据包,以及最早且跨度最大的数据包。
若找到合适的数据包,更新相关时间信息,复制数据包内容,更新指针时间戳, */
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data && jitter->packets[i].timestamp==jitter->pointer_timestamp && GE32(jitter->packets[i].timestamp+jitter->packets[i].span, jitter->pointer_timestamp+desired_span))
break;
}
/* If no match, try for an "older" packet that still spans (fully) the current chunk */
if (i==jitter->buffer_size)
{
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data && LE32(jitter->packets[i].timestamp, jitter->pointer_timestamp) && GE32(jitter->packets[i].timestamp+jitter->packets[i].span,jitter->pointer_timestamp+desired_span))
break;
}
}
/* If still no match, try for an "older" packet that spans part of the current chunk */
if (i==jitter->buffer_size)
{
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data && LE32(jitter->packets[i].timestamp, jitter->pointer_timestamp) && GT32(jitter->packets[i].timestamp+jitter->packets[i].span,jitter->pointer_timestamp))
break;
}
}
/* If still no match, try for earliest packet possible */
if (i==jitter->buffer_size)
{
int found = 0;
spx_uint32_t best_time=0;
int best_span=0;
int besti=0;
for (i=0;i<jitter->buffer_size;i++)
{
/* check if packet starts within current chunk */
if (jitter->packets[i].data && LT32(jitter->packets[i].timestamp,jitter->pointer_timestamp+desired_span) && GE32(jitter->packets[i].timestamp,jitter->pointer_timestamp))
{
if (!found || LT32(jitter->packets[i].timestamp,best_time) || (jitter->packets[i].timestamp==best_time && GT32(jitter->packets[i].span,best_span)))
{
best_time = jitter->packets[i].timestamp;
best_span = jitter->packets[i].span;
besti = i;
found = 1;
}
}
}
if (found)
{
i=besti;
/*fprintf (stderr, "incomplete: %d %d %d %d\n", jitter->packets[i].timestamp, jitter->pointer_timestamp, chunk_size, jitter->packets[i].span);*/
}
}
/* If we find something */
if (i!=jitter->buffer_size)
{
spx_int32_t offset;
/* We (obviously) haven't lost this packet */
jitter->lost_count = 0;
/* In this case, 0 isn't as a valid timestamp */
if (jitter->arrival[i] != 0)
{
update_timings(jitter, ((spx_int32_t)jitter->packets[i].timestamp) - ((spx_int32_t)jitter->arrival[i]) - jitter->buffer_margin);
}
/* Copy packet */
if (jitter->destroy)
{
packet->data = jitter->packets[i].data;
packet->len = jitter->packets[i].len;
} else {
if (jitter->packets[i].len > packet->len)
{
speex_warning_int("jitter_buffer_get(): packet too large to fit. Size is", jitter->packets[i].len);
} else {
packet->len = jitter->packets[i].len;
}
for (j=0;j<packet->len;j++)
packet->data[j] = jitter->packets[i].data[j];
/* Remove packet */
speex_free(jitter->packets[i].data);
}
jitter->packets[i].data = NULL;
/* Set timestamp and span (if requested) */
offset = (spx_int32_t)jitter->packets[i].timestamp-(spx_int32_t)jitter->pointer_timestamp;
if (start_offset != NULL)
*start_offset = offset;
else if (offset != 0)
speex_warning_int("jitter_buffer_get() discarding non-zero start_offset", offset);
packet->timestamp = jitter->packets[i].timestamp;
jitter->last_returned_timestamp = packet->timestamp;
packet->span = jitter->packets[i].span;
packet->sequence = jitter->packets[i].sequence;
packet->user_data = jitter->packets[i].user_data;
/* Point to the end of the current packet */
jitter->pointer_timestamp = jitter->packets[i].timestamp+jitter->packets[i].span;
jitter->buffered = packet->span - desired_span;
if (start_offset != NULL)
jitter->buffered += *start_offset;
return JITTER_BUFFER_OK;
}
/* If we haven't found anything worth returning */
/*fprintf (stderr, "not found\n");*/
jitter->lost_count++;
/*fprintf (stderr, "m");*/
/*fprintf (stderr, "lost_count = %d\n", jitter->lost_count);*/
opt = compute_opt_delay(jitter);
/* Should we force an increase in the buffer or just do normal interpolation? */
if (opt < 0)
{
/* Need to increase buffering */
/* Shift histogram to compensate */
shift_timings(jitter, -opt);
packet->timestamp = jitter->pointer_timestamp;
packet->span = -opt;
/* Don't move the pointer_timestamp forward */
packet->len = 0;
jitter->buffered = packet->span - desired_span;
return JITTER_BUFFER_INSERTION;
/*jitter->pointer_timestamp -= jitter->delay_step;*/
/*fprintf (stderr, "Forced to interpolate\n");*/
} else {
/* Normal packet loss */
packet->timestamp = jitter->pointer_timestamp;
desired_span = ROUND_DOWN(desired_span, jitter->concealment_size);
packet->span = desired_span;
jitter->pointer_timestamp += desired_span;
packet->len = 0;
jitter->buffered = packet->span - desired_span;
return JITTER_BUFFER_MISSING;
/*fprintf (stderr, "Normal loss\n");*/
}
}
EXPORT int jitter_buffer_get_another(JitterBuffer *jitter, JitterBufferPacket *packet)
{
spx_uint32_t i, j;
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data && jitter->packets[i].timestamp==jitter->last_returned_timestamp)
break;
}
if (i!=jitter->buffer_size)
{
/* Copy packet */
packet->len = jitter->packets[i].len;
if (jitter->destroy)
{
packet->data = jitter->packets[i].data;
} else {
for (j=0;j<packet->len;j++)
packet->data[j] = jitter->packets[i].data[j];
/* Remove packet */
speex_free(jitter->packets[i].data);
}
jitter->packets[i].data = NULL;
packet->timestamp = jitter->packets[i].timestamp;
packet->span = jitter->packets[i].span;
packet->sequence = jitter->packets[i].sequence;
packet->user_data = jitter->packets[i].user_data;
return JITTER_BUFFER_OK;
} else {
packet->data = NULL;
packet->len = 0;
packet->span = 0;
return JITTER_BUFFER_MISSING;
}
}
/* Let the jitter buffer know it's the right time to adjust the buffering delay to the network conditions */
static int _jitter_buffer_update_delay(JitterBuffer *jitter, JitterBufferPacket *packet, spx_int32_t *start_offset)
{
spx_int16_t opt = compute_opt_delay(jitter);
/*fprintf(stderr, "opt adjustment is %d ", opt);*/
if (opt < 0)
{
shift_timings(jitter, -opt);
jitter->pointer_timestamp += opt;
jitter->interp_requested = -opt;
/*fprintf (stderr, "Decision to interpolate %d samples\n", -opt);*/
} else if (opt > 0)
{
shift_timings(jitter, -opt);
jitter->pointer_timestamp += opt;
/*fprintf (stderr, "Decision to drop %d samples\n", opt);*/
}
return opt;
}
/* Let the jitter buffer know it's the right time to adjust the buffering delay to the network conditions */
EXPORT int jitter_buffer_update_delay(JitterBuffer *jitter, JitterBufferPacket *packet, spx_int32_t *start_offset)
{
/* If the programmer calls jitter_buffer_update_delay() directly,
automatically disable auto-adjustment */
jitter->auto_adjust = 0;
return _jitter_buffer_update_delay(jitter, packet, start_offset);
}
/** Get pointer timestamp of jitter buffer */
EXPORT int jitter_buffer_get_pointer_timestamp(JitterBuffer *jitter)
{
return jitter->pointer_timestamp;
}
EXPORT void jitter_buffer_tick(JitterBuffer *jitter)
{
/* Automatically-adjust the buffering delay if requested */
if (jitter->auto_adjust)
_jitter_buffer_update_delay(jitter, NULL, NULL);
if (jitter->buffered >= 0)
{
jitter->next_stop = jitter->pointer_timestamp - jitter->buffered;
} else {
jitter->next_stop = jitter->pointer_timestamp;
speex_warning_int("jitter buffer sees negative buffering, your code might be broken. Value is ", jitter->buffered);
}
jitter->buffered = 0;
}
EXPORT void jitter_buffer_remaining_span(JitterBuffer *jitter, spx_uint32_t rem)
{
/* Automatically-adjust the buffering delay if requested */
if (jitter->auto_adjust)
_jitter_buffer_update_delay(jitter, NULL, NULL);
if (jitter->buffered < 0)
speex_warning_int("jitter buffer sees negative buffering, your code might be broken. Value is ", jitter->buffered);
jitter->next_stop = jitter->pointer_timestamp - rem;
}
/* Used like the ioctl function to control the jitter buffer parameters */
EXPORT int jitter_buffer_ctl(JitterBuffer *jitter, int request, void *ptr)
{
int count;
spx_uint32_t i;
spx_int32_t buffer_size;
switch(request)
{
case JITTER_BUFFER_SET_MARGIN:
jitter->buffer_margin = *(spx_int32_t*)ptr;
break;
case JITTER_BUFFER_GET_MARGIN:
*(spx_int32_t*)ptr = jitter->buffer_margin;
break;
case JITTER_BUFFER_GET_AVALIABLE_COUNT:
count = 0;
for (i=0;i<jitter->buffer_size;i++)
{
if (jitter->packets[i].data && LE32(jitter->pointer_timestamp, jitter->packets[i].timestamp))
{
count++;
}
}
*(spx_int32_t*)ptr = count;
break;
case JITTER_BUFFER_SET_DESTROY_CALLBACK:
jitter->destroy = (void (*) (void *))ptr;
break;
case JITTER_BUFFER_GET_DESTROY_CALLBACK:
*(void (**) (void *))ptr = jitter->destroy;
break;
case JITTER_BUFFER_SET_DELAY_STEP:
jitter->delay_step = *(spx_int32_t*)ptr;
break;
case JITTER_BUFFER_GET_DELAY_STEP:
*(spx_int32_t*)ptr = jitter->delay_step;
break;
case JITTER_BUFFER_SET_CONCEALMENT_SIZE:
jitter->concealment_size = *(spx_int32_t*)ptr;
break;
case JITTER_BUFFER_GET_CONCEALMENT_SIZE:
*(spx_int32_t*)ptr = jitter->concealment_size;
break;
case JITTER_BUFFER_SET_MAX_LATE_RATE:
jitter->max_late_rate = *(spx_int32_t*)ptr;
jitter->window_size = 100*TOP_DELAY/jitter->max_late_rate;
jitter->subwindow_size = jitter->window_size/MAX_BUFFERS;
break;
case JITTER_BUFFER_GET_MAX_LATE_RATE:
*(spx_int32_t*)ptr = jitter->max_late_rate;
break;
case JITTER_BUFFER_SET_LATE_COST:
jitter->latency_tradeoff = *(spx_int32_t*)ptr;
break;
case JITTER_BUFFER_GET_LATE_COST:
*(spx_int32_t*)ptr = jitter->latency_tradeoff;
break;
case JITTER_BUFFER_SET_LIMIT:
buffer_size = *(spx_int32_t*)ptr;
jitter->buffer_size = (buffer_size > 1 && buffer_size <= SPEEX_JITTER_MAX_BUFFER_SIZE) ? buffer_size : SPEEX_JITTER_MAX_BUFFER_SIZE;
jitter_buffer_reset(jitter);
break;
default:
speex_warning_int("Unknown jitter_buffer_ctl request: ", request);
return -1;
}
return 0;
}
以上这个算法和下面这个算法的timing计算逻辑一样吗
// 维护状态信息
struct TimingCalculator {
uint32_t last_arrival_time;
uint32_t last_rtp_timestamp;
uint16_t last_sequence;
uint32_t clock_rate; // 时钟频率(如8000、16000、48000)
uint32_t expected_delay;
};
void init_timing_calculator(struct TimingCalculator *calc, uint32_t clock_rate) {
memset(calc, 0, sizeof(*calc));
calc->clock_rate = clock_rate;
calc->expected_delay = 50; // 初始预期延迟50ms
}
int32_t calculate_comprehensive_timing(struct TimingCalculator *calc,
uint32_t rtp_timestamp,
uint32_t arrival_time,
uint16_t sequence) {
if (calc->last_arrival_time == 0) {
// 第一个包,只记录信息
calc->last_arrival_time = arrival_time;
calc->last_rtp_timestamp = rtp_timestamp;
calc->last_sequence = sequence;
return 0;
}
// 计算基于时间戳的timing
uint32_t ts_diff = rtp_timestamp - calc->last_rtp_timestamp;
uint32_t arrival_diff = arrival_time - calc->last_arrival_time;
// 将时间戳差异转换为毫秒
uint32_t expected_ms = (ts_diff * 1000) / calc->clock_rate;
// 计算timing
int32_t timing = arrival_diff - expected_ms;
// 更新状态
calc->last_arrival_time = arrival_time;
calc->last_rtp_timestamp = rtp_timestamp;
calc->last_sequence = sequence;
return timing - calc->expected_delay;
}
最新发布





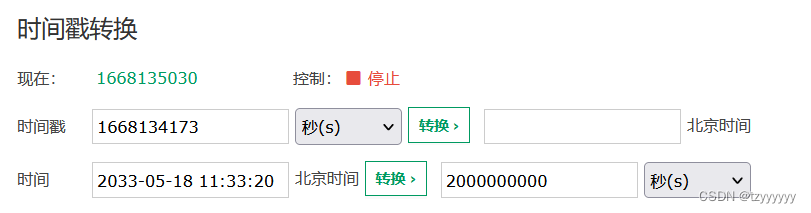
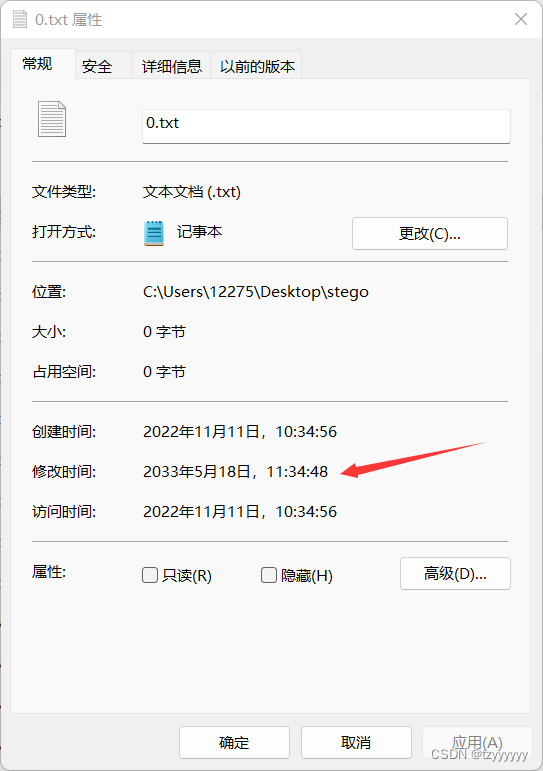
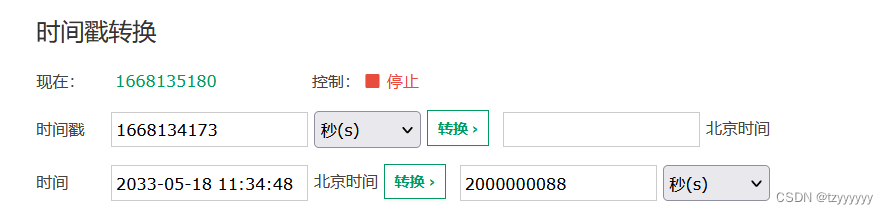
 本文讲述了作者通过分析大量txt文件的时间戳,利用时间戳差值解码技术找到隐藏的flag的过程。通过脚本逐个文件计算时间戳差,发现每个差值对应一个字符,最终组合成'XMan{seems_to_be_related_to_the_special_guests}
本文讲述了作者通过分析大量txt文件的时间戳,利用时间戳差值解码技术找到隐藏的flag的过程。通过脚本逐个文件计算时间戳差,发现每个差值对应一个字符,最终组合成'XMan{seems_to_be_related_to_the_special_guests}

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











