






 本文介绍了文本归一化、字符过滤器(HTMLStrip、mapping、patternreplace)、tokenfiter的近义词处理,以及分词器(如standard、IK分词器和自定义分词)的应用。重点讲解了IK分词器的原理,包括主词库、停用词库和自定义词库的使用,以及热更新技术,如数据库和远程文件的更新策略。
本文介绍了文本归一化、字符过滤器(HTMLStrip、mapping、patternreplace)、tokenfiter的近义词处理,以及分词器(如standard、IK分词器和自定义分词)的应用。重点讲解了IK分词器的原理,包括主词库、停用词库和自定义词库的使用,以及热更新技术,如数据库和远程文件的更新策略。
一、normalization(归一化)
将文本拆分成词项之后,为了让这些词项更容易被搜索,这些词项需要被归一化。
将这些词项的大小写统一,语气词停用词去除,特殊的词汇变得跟符合人平时的语言词汇(不同意的词变成通用词)。
二、character fifter
字符过滤器,在分词处理之前,要过滤掉一些无用的字符,大致过滤以下三种:
(1)、HTML Strip
过滤html标签,也可以指定要保留的标签
配置自定义的配置:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"自定义分词器名称": {
"tokenizer": "ik_smart或者ik_max_word",
"char_filter": ["html_strip"]
}
}
}
}
}
配置完成以后,在配置mapping的时候设置好这个分词器,在查询的时候也可以显示的指定这个
分词器,最终生成的词项,就会排除掉html标签。
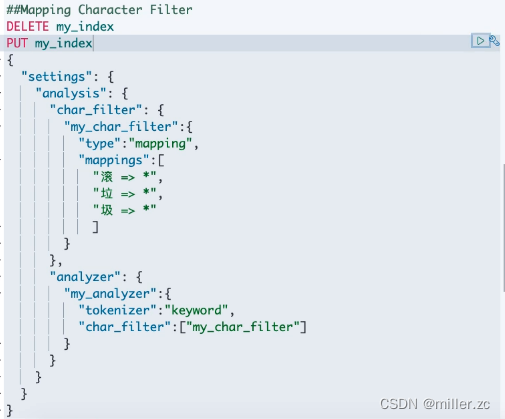
(2)、mapping
自定义映射,会根据自定义的规则,来替换特定的字符
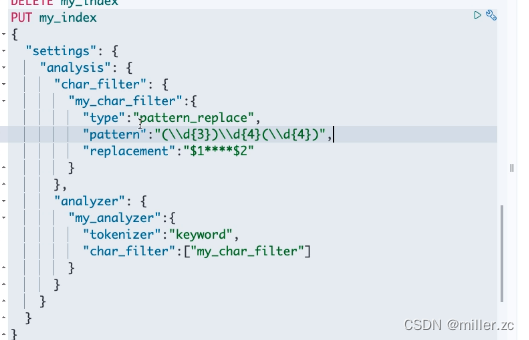
(3)、pattern replace
正则替换,通过正则表达式,来替换特定的部分。
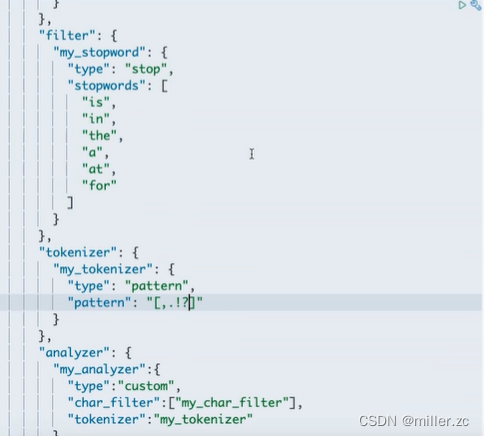
三、token fifter
令牌过滤器,处理时态转换、大小写转换、停用词、近义词、大小写等数据,近义词/停用词等都可以自定义配置。

四、分词器
分词器就是按照不同的规则,将doc进行切词,切成一个个的词项,生成倒排索引。
tokenizer就是分词器,fiter就是过滤器,tokenizer+fiter就是analyzer(分词过滤器)
(1)、 默认分词器(standard)
基于英文的习惯进行拆分词项,按照空格进行拆分
(2)、ik分词器(ik_max_word)
基于中文的习惯,进行词项拆分
(3)、自定义分词器(custom)
实质上就是自己组合tokenizer就是分词器(自定义的),和fifter就是过滤器(自定义的)
(4)、中文分词器(IK)
实质上就是一个插件,这个插件里面有几种dic文件(字典文件),
里面记录了大量日常用到的中文词项。对文档进行解析分词的时候,就会去比对这些dic文件,
形成对应的倒排索引。
按照词项拆分粒度,分为ik_max_word(大粒度拆分)和ik_smart_word(小粒度拆分)
按照dic文件的不同,分为以下几类:
(1)、主词库(main.dic):
记录日常的中文分词信息
(2)、停用词词库(stopword.dic)
记录英文的停用词,不会建立在倒排索引中
(3)、特殊词库:
中文习惯的计量单位、行政单位、百家姓、语气词等等
(4)、自定义词库:
在Ikanalyzer.cfg.xml中扩展,设置自定义的dic文件(词库文件)的路径。
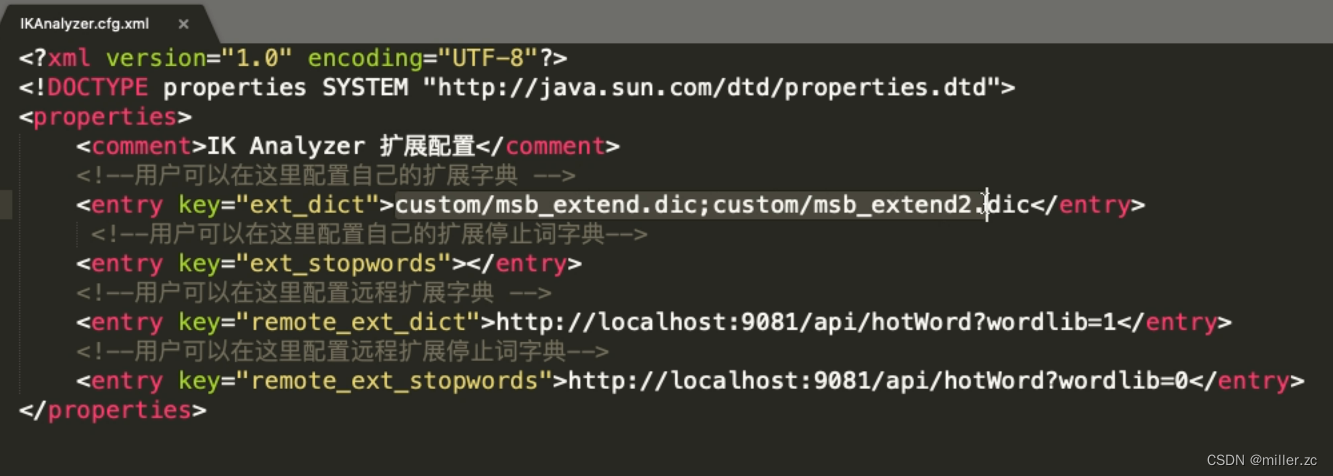
在服务器本地配置扩展词典,配置或修改之后需要重启es服务。
但是配置远程扩展,可以实现热更新。
(5)、热更新
1、基于远程文件的热更新:
(1)、将远程词典文件放在nginx或者其它http server下
(2)、写一个读取远程词典的http接口,这个接口满足两个条件,第一是返回utf-8编码,
第二是响应头里面有last-modified和etage字段,如果文件被修改,这两个字段的数据会变化。
(3)、在Ikanalyzer.cfg.xml文件中,配置读取远程字典数据的http接口路径,es默认会按一分钟为粒度去请求这个接口。
(4)、es只要发现读取远程字典数据的http接口,返回的last-modified和etage字段有变化,就会根据响应体里面的词项修改词库。
这种基于远程文件的热更新,实质上就是依靠一个http接口和es自带的定时执行,去检测文件是否更新,文件更新了就更新词库。这种方式虽然不用重启服务,但是IO频繁量大,并且读取文件完全没有优化。
2、数据库热更新
修改ik分词器源码,支持从mysql中每隔一定时间,自动加载新的词库
步骤:
1、在词典初始化方法,Dictionary类的静态方法initial里面创建一个线程,用来加载我们自定义的词项数据。
2、创建的线程里面的run方法,在死循环执行Dictionary.getSingleton().reLoadMainDict(),去重新加载词典。
3、Dictionary.getSingleton().reLoadMainDict()里面加上一个从mysql加载词项的方法this.loadMySQLExtDict();
4、this.loadMySQLExtDict();方法里面,就是连接数据库,执行数据库语句,查询出来的数据更新到词库。
5、源码修改完成之后,maven打包成jar,将jar移动到es的plugins文件夹下,加压替换原来的ik分词器jar,
将mysql的驱动jar放到ik目录下。
6、重启es就会生效。

















 2829
2829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









