







兄弟们!!!今天我们来聊一聊ElasticSearch中的分词器,分词器的作用就是将文本内容切分成一个个的词项,倒排索引记录这些词项与文档的关联关系,后续搜索时,ElasticSearch仅通过检索这些词项即可关联出对应的文档记录。
体验一下分词
使用ElasticSearch的内置分词器standard(默认分词器),对hello world进行分词
POST _analyze
{
"analyzer": "standard",
"text": "hello world"
}
===输出结果===
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "world",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
分词结果:分成了hello和world两个词项
ElasticSearch内置分词器

- standard是默认的分词器
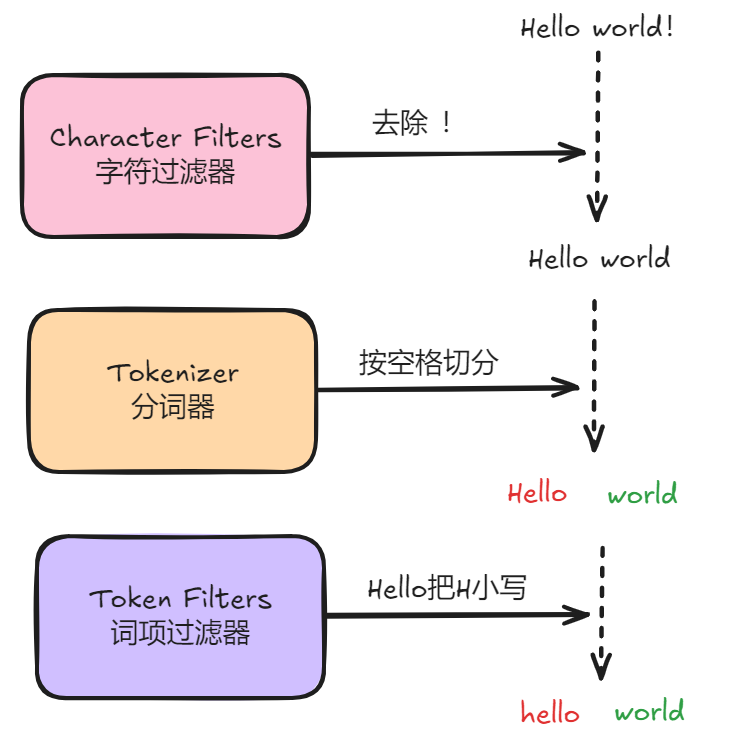
分词器的组成
分词器由三个部分组成:
- Character Filters:字符过滤器,主要负责字符的增删改
- Tokenizer:分词器,主要负责将文本切分为多个词项
- Token Filters:词项过滤器,主要负责切分后词项的增删改
字符过滤器(Character Filters)
负责字符的增删改
- HTML Strip Character Filter:删除HTML元素标签
- Mapping Character Filter:替换指定字符
- …
分词器(Tokenizer)
负责分词
- Standard Tokenizer:标准分词器,按照基本语法分词
- Letter Tokenizer:字母分词器,按照字母分词
- Whitespace tokenizer:空格分词器,按照空格分词
- …
词项过滤器(Token Filters)
负责处理分词后的词项
- Lowercase token filter:将词项中字母转换为小写
- …
自定义一个分词器
在知道了分词器的三个组成部分后,我们来自定义一个分词器
调试自定义分词器
POST _analyze
{
"char_filter": [
"html_strip",
{
"type":"mapping",
"mappings": ["!=>"]
}
],
"tokenizer": {"type":"whitespace"}, //可以直接写成 "tokenizer":"whitespace"
"filter": [{"type":"lowercase"}], //可以直接写成 "filter":["lowercase"]
"text": "<h1>Hello world!</h1>"
}
===输出结果===
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 4,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "world",
"start_offset" : 10,
"end_offset" : 16,
"type" : "word",
"position" : 1
}
]
}
- char_filter:使用了内置的html_strip字符过滤器和内置的mapping字符过滤器,并配置mapping规则将**!**转换为空
- tokenizer:使用内置的whitespace分词器,按照空格切分
- filter:词项过滤器选择内置的lowercase词项过滤器,将词项全部转为小写
创建索引,应用自定义分词器
定义索引
PUT analyzer_index
{
"settings":{
"analysis": {
"char_filter": {
"xixi_char_filter":{
"type":"mapping",
"mappings": [
"!=>"
]
}
},
"tokenizer": {
"xixi_tokenizer":{
"type":"whitespace"
}
},
"filter": {
"xixi_filter":{
"type":"lowercase"
}
},
"analyzer": {
"xixi_analyzer":{
"char_filter":["html_strip","xixi_char_filter"],
"tokenizer":"xixi_tokenizer",
"filter":"xixi_filter"
}
}
}
},
"mappings": {
"properties": {
"content":{
"type": "text",
"analyzer": "xixi_analyzer"
}
}
}
}
- char_filter:定义了一个名为xixi_char_filter的字符过滤器
- tokenizer:定义了一个名为xixi_tokenizer的分词器
- filter:定义了一个名为xixi_filter的词项过滤器
- analyzer:定义了最终的分词器xixi_analyzer,并指定这个最终分词器的char_filter、tokenizer和filter
- 最后定义一个content字段,应用了xixi_analyzer分词器
验证分词器
POST analyzer_index/_analyze
{
"analyzer": "xixi_analyzer",
"text":"<h1>Hello world!</h1>"
}
===输出结果===
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 4,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "world",
"start_offset" : 10,
"end_offset" : 16,
"type" : "word",
"position" : 1
}
]
}
安装IK分词器
中文分词器我们可以选择比较有名的IK分词器,下面我来演示安装方法
- 下载IK分词器安装包
wget https://github.com/infinilabs/analysis-ik/releases/download/v7.17.18/elasticsearch-analysis-ik-7.17.18.zip
- 解压IK分词器安装包
yum install -y unzip
unzip elasticsearch-analysis-ik-7.17.18.zip
- 将解压后的目录移动至**${ES_HOME}/plugins**目录下

- 重启ES
bin/elasticsearch -d
- 验证
//ik_max_word
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
//ik_smart
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
IK分词器提供了两种分词模式
- ik_max_word:这种模式会将文本最大程度地切分成独立的词汇。它主要通过条件随机场(Conditional Random Field, CRF)模型来识别词汇边界,然后使用动态规划寻找最优的词段划分。
- ik_smart:这种模式结合了理解歧义和未知词的算法,对文本进行词典分词的同时,也会智能识别词汇的边界,从而提高分词的准确性
直白点就是:ik_max_word分出的词项多,ik_smart分出的词项少
参考文章
- 《一本书讲透Elasticsearch:原理、进阶与工程实践》【杨昌玉】
- 《ElasticSearch核心技术及实战》【极客时间】
兄弟们求关注啊!!
公众号:溪溪技术笔记

















 2829
2829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









