



企业数字化运营的用户数据资产管理平台
打通多源数据
统一用户识别
项目概述
用户画像:UserProfile、UserPersonal
给每个用户打上标签,本体论。
用户基本数据和用户行为数据。
第一类:用户基本信息数据,构建标签还原画像称为User Personal;
第二类:用户业务数据,使用APP产出数据,构建标签还原画像被称为User Profile;
描述一个人:
张三、女性、28岁,高级白领、旅游达人、水瓶座
将用户数据标签化
构建用户画像基础:
数据仓库 → 构建标签 → 构建用户画像 → 营销、推荐、报表
用户画像的应用场景
电商平台用户画像系统设计与开发
项目背景
本项目基于电商平台进行设计开发,旨在通过对注册会员的偏好、行为习惯及人员属性进行深度分析,实现用户画像的还原。该画像体系服务于营销平台和个性化推荐系统,以提升营销精准度,并为每个用户提供快速、准确的商品推荐。
核心业务数据来源
-
订单数据
- 包括购买记录、交易金额、支付方式、收货地址等。
-
访问日志数据
- 用户浏览轨迹、页面停留时间、点击行为、搜索关键词等。
-
会员注册基本信息
- 年龄、性别、地区、注册时间、会员等级等静态信息。
用户画像标签存储架构
| 存储类型 | 用途说明 |
|---|---|
| HBase 表 | 存储每个用户的个体画像(细粒度标签),支持高并发读写与海量数据存储。 |
| ElasticSearch / Solr 索引 | 支持多维度标签组合查询,用于快速筛选符合特定条件的用户群体,服务于运营圈人、精准营销等场景。 |
项目平台架构
第一部分:标签管理平台
一、功能模块
- 基础标签管理
- 组合标签构建
- 画像模块
- 微观画像(单个用户)
- 群体画像(用户群特征分析)
- 标签查询系统
二、基础标签分类体系
1. 按数据来源划分
| 分类 | 描述 |
|---|---|
| 人员属性 | 如性别、年龄、职业、教育程度、婚姻状况等。 |
| 商业属性 | 如消费频次、客单价、品类偏好、品牌偏好等。 |
| 行为属性 | 如登录频率、页面浏览路径、加购行为、收藏行为、搜索行为等。 |
| 用户价值 | 基于RFM模型或其他价值评估模型划分的高/中/低价值用户。 |
2. 按实现方式划分
| 类型 | 描述 |
|---|---|
| 规则匹配标签 | 基于明确业务规则生成,如“近7天有下单”、“浏览过手机类目”。 |
| 统计类型标签 | 通过聚合计算得出,如“月均消费金额”、“访问频次”。 |
| 挖掘类型标签 | 利用机器学习或数据挖掘算法生成,如“潜在流失用户”、“价格敏感型用户”。 |
3. 标签等级划分
| 层级 | 名称 | 示例 |
|---|---|---|
| 一级标签 | 主分类标签 | 用户属性、行为特征、消费能力 |
| 二级标签 | 主分类标签 | 人口属性、浏览行为、购买行为 |
| 三级标签 | 主分类标签 | 性别、年龄段、设备类型 |
| 四级标签 | 业务标签 | “女性用户”、“25-30岁用户”、“iOS设备用户” |
| 五级标签 | 属性标签 | 具体值标签,如 gender=female、age=28 |
说明:层级越高,抽象程度越高;层级越低,越具体可执行。
第二部分:标签模型应用开发
开发模式
-
一个标签对应一个模型
每个标签由独立的数据处理逻辑生成。 -
一个模型即一个 Spark 程序
使用 Apache Spark 进行大规模离线/准实时计算。
支持批处理(T+1)与流式处理(近实时更新)两种模式。
输出结果写入 HBase 和 ES/Solr。
示例:标签模型流程
[原始数据]
↓ (ETL清洗)
[Spark Job] → 计算"近30天购买频次"
↓ (输出)
[HBase] → 存储用户ID + 频次值
[ES/Solr] → 构建索引,支持按“购买频次 > 5”查询人群
项目背景
概述
基于电商平台进行设计界开发,是面向注册会员的偏好、行为习惯和人员属性的画像还原。帮助提升营销平台提升营销的精准度,也方便个性化推荐系统,快速准确的为每个用户推荐相关的商品。
- 业务数据
订单数据、访问日志数据、会员注册基本信息。 - 画像标签存储
- HBase表:每个用户的个体画像
- ElasticSearch、Solr索引:方便依据不同标签条件组成查询出相应用户群体。
- 项目平台:
- 第一部分:标签管理平台
- 第一块:基础标签、组合标签、画像模块(微观画像、群体画像)、标签查询
针对基础标签:分类和等级划分
从不同角度来说,标签划分不同类别
从数据源:人员属性、商业属性、行为属性和用户价值
从实现程度:规则匹配标签、统计类型标签、挖掘类型标签
标签划分等级
主分类标签:一级、二级、三级标签
业务标签:四级标签
属性标签:五级标签
第二部分:标签模型应用开发
一个标签对应一个模型,一个模型就是一个spark程序;
第三部分:
数据化运营
为什么使用Hbase数据库?因为对于用户的标签可能会增加,使用MySQL并不能很好的管理标签。
用户基础数据存储在Hbase中
元数据管理:管理标签
针对用户画像标签系统来说,需要管理整个系统中有多少类型标签,每个标签的对应值有哪些?
存储在MySQL中
画像数据
涉及的数据有两类:
- 第一类数据:标签数据(元数据MetaData) MySQL
- 存储标签的基本信息数据,每个标签名称、标签的值、标签的级别(类型)等。
- 第二类数据:用户画像标签
- 存储HBase表中,tbl_prifile
ROW_KEY:userId
列簇 ColumnFamily:- 用户标签列簇:user
- 商品标签列簇:item
- 列值:每个标签
tagName -> tagValue - 在HBase Shell命令行中创建用户标签表
create 'tbl_profile', 'user', 'item'
- 存储ElasticSearch索引:tags_index
- 替换CDH 产品的 solr
- 存储HBase表中,tbl_prifile
架构
tag-web模块:标签管理平台
tag-model模块:给所有用户打上某个标签的值
tag-web模块依赖tag-model模块,tag-web平台执行tag-model模块中的一些应用,所以model模块先编译安装。
- 安装install
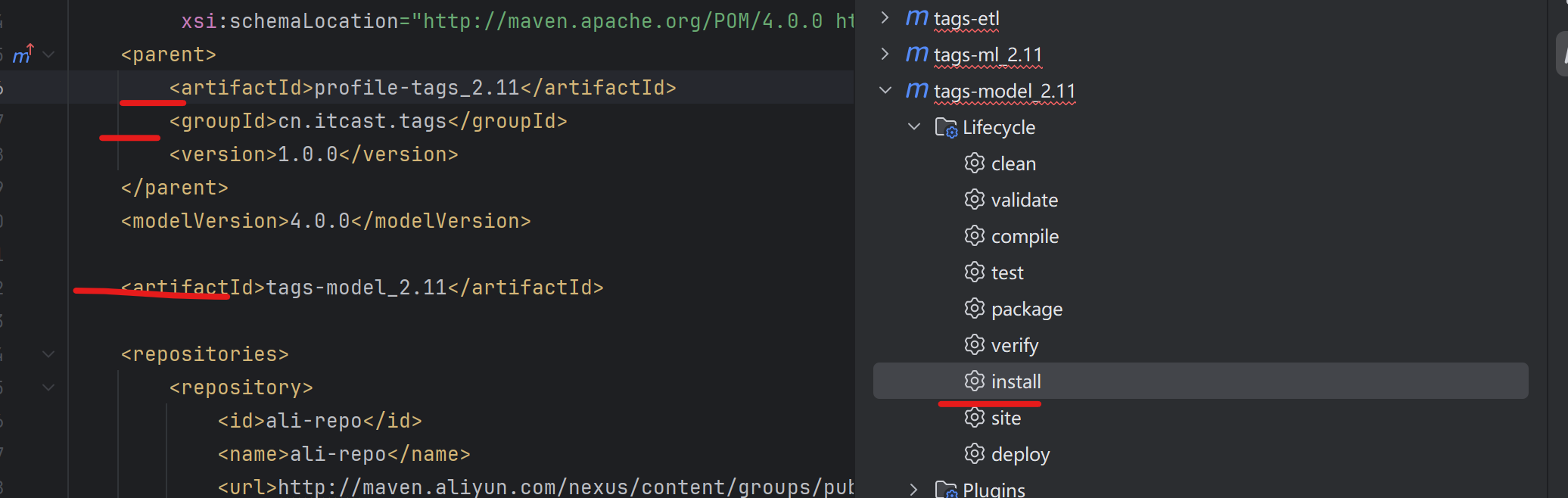
- 查看安装后的模块
[INFO] Installing D:\project\profile-tags\tags-model\target\tags-model_2.11-1.0.0.jar to D:\BigdataUser\m2-3.3.9\repository\cn\itcast\tags\tags-model_2.11\1.0.0\tags-model_2.11-1.0.0.jar
[INFO] Installing D:\project\profile-tags\tags-model\pom.xml to D:\BigdataUser\m2-3.3.9\repository\cn\itcast\tags\tags-model_2.11\1.0.0\tags-model_2.11-1.0.0.pom
不需要再配置Tomcat,直接使用SpringBoot。
画像技术架构图
- 数据源层
- MySQL数据库表、日志文件
- 数据存储层
- 采集工具:sqoop、flume、Cannal
- 数据分析层
- 主要使用SparkSQL、SparkMlib构建用户标签
- 标签数据存储:HBase、Solr/Elastcisearch
- 标签元数据
- 主要管理整个用户画像平台中哪些标签,标签的基本信息
- 存储在MySQL表中
- 每个标签开发完成后,每隔一段时间运行应用程序,给用户打上标签值
- 使用Oozie中Coordinator调度器。
技术架构图
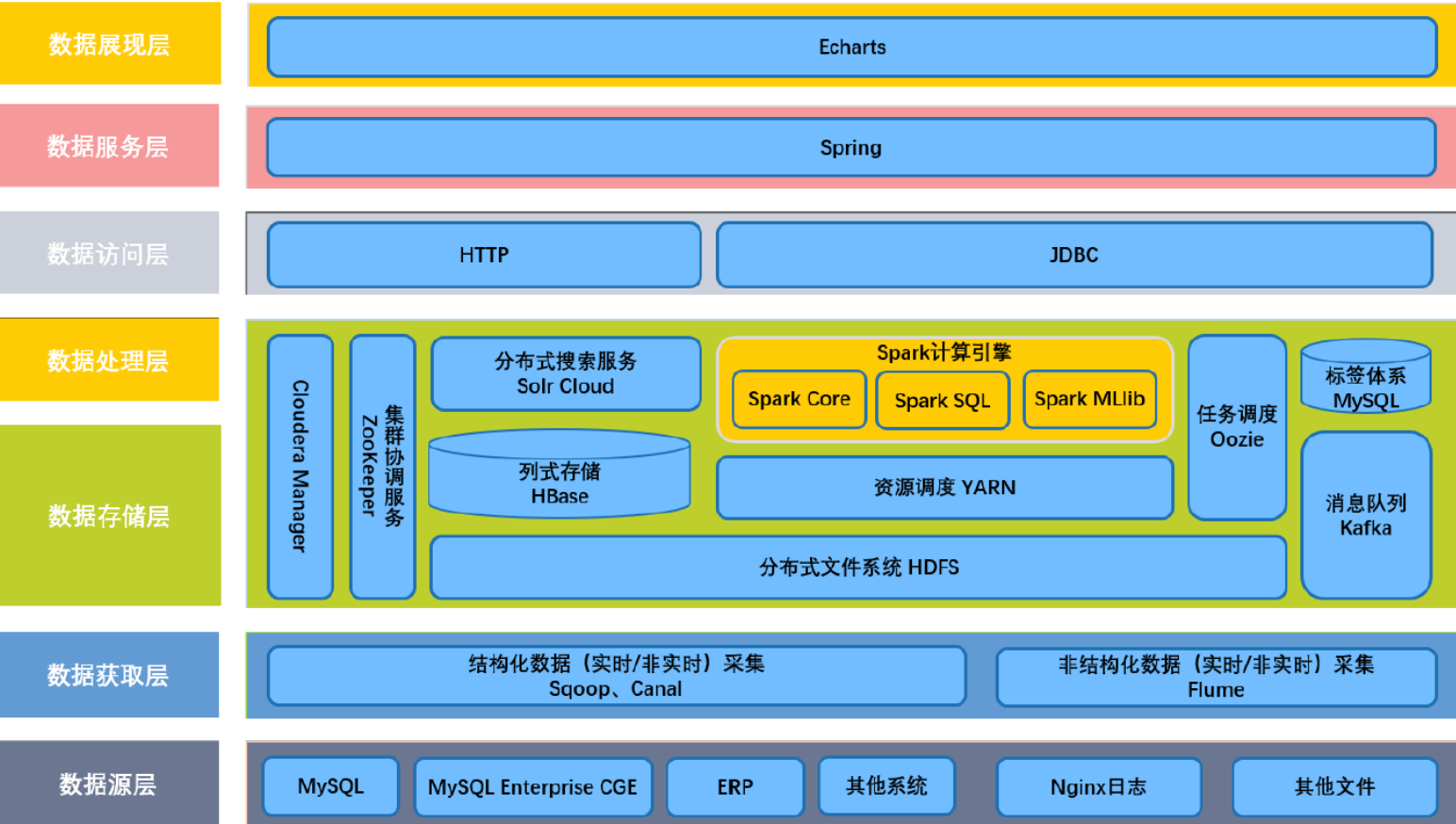
功能架构图
用户画像:将用户数据进行标签化,给用户打标签。
HBase通过协处理器可以监控表中是否有数据变化。
用户画像标签开发中,按照标签开发难易程度划分:
- 规则匹配类型标签,可以理解为 if_else
- 统计类型标签,使用聚合函数统计
- 挖掘类型标签,设计机器学习算法
标签系统概述
基础标签
标签分类
在用户画像项目中,将标签按照级别进行划分,总共氛围5个级别标签。
- 1,2,3 主分类标签
- 4级 业务标签 性别标签
- 5级 属性标签 男女属性
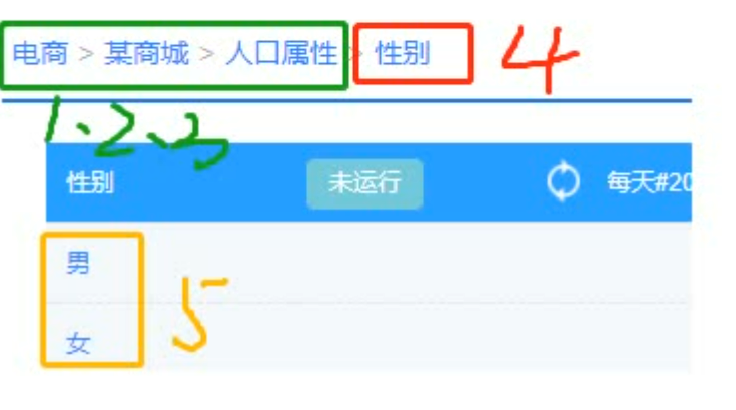
为什么主分类是三级?是根据具体的电商场景为例。
以淘宝为例来说,淘宝网的子行业
天猫超市、苏宁易购等等
然后是用户。
一个标签(四级标签、业务标签)对应一个模型,每个模型对应一个spark应用。
1、标签表:tbl_basic_tag
2、模型表:tbl_model
标签规则:
当对所有用户计算该标签值时使用数据源信息。
用户基本信息表数据所在的数据源,以及对应的字段。
例如:从HBase表加载数据:
需要 ZooKeeper的地址信息:zkHosts、zkPort、zkNodePath、表的名称(table)、列簇(famliy)、字段(columns);
程序入口:对应的Spark应用运行主类
算法名称:挖掘类型、统计类型
算法引擎:jar包
模型参数:spark运行的资源参数
标签体系:
基础标签、组合标签
画像体系:
微观画像、标签查询
微观画像:从HBase表查询 tpl_profile 画像标签表,直接依据UserID查询即可。
标签查询:从搜索引擎Solr/ElasticSearch中进行查询。
大数据环境
企业的实际项目中:
大数据管理Web界面,方便安装部署和监控大数据框架组件:
CLouderManager:CM
Ambari:开源 /etc/
大数据平台基础环境
项目启动
ZooKeeper启动
cd /export/servers/zookeeper
./bin/zkServer.sh start
Hadoop启动
#启动Hadoop 的 namenode
hadoop-daemon.sh start namenode
#启动Hadoop的datanode
hadoop-daemon.sh start datanode
historyserver启动
mr-jobhistory-daemon.sh start historyserver
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/start-history-server.sh
yarn
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
[root@bigdata-cdh01 scripts]# cd ~
[root@bigdata-cdh01 ~]# clear
[root@bigdata-cdh01 ~]# ll
total 12
-rwxr–r-- 1 root root 2468 Nov 20 2019 env-bd.sh
-rw-r–r-- 1 root root 5710 Oct 8 21:57 zookeeper.out
env-bd.sh
hue启动
HUE_HOME=/export/servers/hue
HUE_LOG=${HUE_HOME}/hue-${DATE_STR}.log
/usr/bin/nohup ${HUE_HOME}/build/env/bin/supervisor > ${HUE_LOG} 2>&1 &
运行命令
#!/bin/bash
# 设置 Spark 家目录
SPARK_HOME="/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0"
# 提交 Spark 应用到 YARN 集群(集群模式)
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 512m \
--driver-cores 1 \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
hdfs://bigdata-cdh01.itcast.cn:8020/spark/spark-examples_2.11-2.2.0.jar \
10
业务数据调研以及ETL
业务数据:原始存储在MySQL中
业务数据:大数据存储在HBase中
那么如何将原始存储的数据导入到HBase中?
将MySQL表数据导入到HDFS/Hive中,将数据存储为HFile文件,直接加载至HBase表(MR,Spark)。
将MySQL表数据同步都爱HBase表,方案如下:
- Sqoop导入,增量或者全量
- MySQL 到 HBase
- Sqoop导入HDFS
- MySQL 到 HDFS
- HDFS到HBase中
1.使用MapReduce程序
2.使用Spark程序
3.ImportTsv工具类,底层也是MapReduce程序
启动HBase数据库
切换到
cd /export/scripts/
然后运行脚本:
启动 HiveMetastore 服务和 HiveServer2 服务
sh metastore-start.sh
sh hiverserver2-start.sh
使用 beeline 命令行连接
/export/servers/hive/bin/beeline
!connect jdbc:hive2://bigdata-cdh01.itcast.cn:10000
#查看是否有10000端口的监听
netstat -anp | grep :10000
#输入用户名及密码
Enter username for jdbc:hive2://bigdata-cdh01.itcast.cn:10000: root
Enter password for jdbc:hive2://bigdata-cdh01.itcast.cn:10000: ****
创建表
创建数据库
CREATE DATABASE tags_dat;
USE tags_dat;
使用 Sqoop 创建 Hive 表
用户信息表:tbl_users
/export/servers/sqoop/bin/sqoop create-hive-table \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--table tbl_users \
--username root \
--password 123456 \
--hive-table tags_dat.tbl_users \
--fields-terminated-by '\t' \
--lines-terminated-by '\n'
订单数据表:tbl_orders
/export/servers/sqoop/bin/sqoop create-hive-table \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--table tbl_orders \
--username root \
--password 123456 \
--hive-table tags_dat.tbl_orders \
--fields-terminated-by '\t' \
--lines-terminated-by '\n'
商品表:tbl_goods
/export/servers/sqoop/bin/sqoop create-hive-table \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--table tbl_goods \
--username root \
--password 123456 \
--hive-table tags_dat.tbl_goods \
--fields-terminated-by '\t' \
--lines-terminated-by '\n'
行为日志表:tbl_logs
/export/servers/sqoop/bin/sqoop create-hive-table \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--table tbl_logs \
--username root \
--password 123456 \
--hive-table tags_dat.tbl_logs \
--fields-terminated-by '\t' \
--lines-terminated-by '\n'
导入数据到Hive表中
通过Sqoop工具导入到Hive表中;
用户信息表:tbl_users
/export/servers/sqoop/bin/sqoop import \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_users \
--direct \
--hive-overwrite \
--delete-target-dir \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--hive-table tags_dat.tbl_users \
--hive-import \
--num-mappers 1
订单数据表:tbl_orders
/export/servers/sqoop/bin/sqoop import \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_orders \
--direct \
--hive-overwrite \
--delete-target-dir \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--hive-table tags_dat.tbl_orders \
--hive-import \
--num-mappers 10
商品表:tbl_goods
/export/servers/sqoop/bin/sqoop import \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_goods \
--direct \
--hive-overwrite \
--delete-target-dir \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--hive-table tags_dat.tbl_goods \
--hive-import \
--num-mappers 5
行为日志表:tbl_logs
/export/servers/sqoop/bin/sqoop import \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_logs \
--direct \
--hive-overwrite \
--delete-target-dir \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--hive-table tags_dat.tbl_logs \
--hive-import \
--num-mappers 1
数据迁移ETL
如何将业务数据从MySQL迁移(ETL)到HBase表中,不同方案。
涉及到编写程序:MR程序、Spark程序
数据导入
- Sqoop导入
- 直接将MySQL数据库表的数据同步导入至HBase表,底层运行MapReduce程序。
- MapReduce导入
- Spark RDD导入
- 编写程序,读取HDFS上文件数据,导入到HBase表中,需要将MySQL表的数据导入到HDFS、Hive中。
- 针对MapReduce导入,直接使HBase提供工具类ImportTsv,自己编写MapReduce导入。
启动HBase
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
HBase创建表
#进入HBase中
hbase shell
#列出所有的表
list
#创建四张表 tbl_logs tbl_orders tbl_users tbl_goods
create 'tbl_users', 'detail'
create 'tbl_orders', 'detail'
create 'tbl_goods', 'detail'
create 'tbl_logs', 'detail', SPLITS => ['189394']
数据迁移 - Sqoop导入
可以使用 Sqoop 将 MySQL 表的数据导入到 HBase 表中,需指定表的名称、列簇及 RowKey。示例如下:
/export/servers/sqoop/bin/sqoop import \
-D sqoop.hbase.add.row.key=true \
--connect jdbc:mysql://bigdata-cdh01.itcast.cn:3306/tags_dat \
--username root \
--password 123456 \
--table tbl_users \
--hbase-create-table \
--hbase-table tbl_users \
--column-family detail \
--hbase-row-key id \
--num-mappers 2
使用 Sqoop 从MySQL导入到HBase,有一个限制:组合字段主键。
需要指定 RDBMs 表中的某个字段作为HBase表的RowKey,如果HBase表的RowKey为多个字段组合,就无法指定,那么这种方式就无法使用。
数据迁移 - HBase ImportTSV工具导入
ImportTSV 是 HBase 提供的一个工具,用于将 TSV(Tab-Separated Values)格式的文本数据导入到 HBase 表中。TSV 文件也可以是 CSV 格式,每行数据中各个字段使用分隔符分隔。
支持两种导入方式:
- 使用
Put方式逐条加载导入。 - 使用
BulkLoad方式进行批量加载导入。此种性能更好。
- 第一种方式:使用put方式导入
查看 HBase 官方自带工具的使用说明,执行以下命令:
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf ${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.14.0.jar importtsv
Usage: importtsv -Dimporttsv.columns=a,b,c <tablename> <inputdir>
整体迁移命令如下:
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf ${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.14.0.jar \
importtsv \
-Dimporttsv.columns=HBASE_ROW_KEY,detail:log_id,detail:remote_ip,detail:site_global_ticket,detail:site_global_session,detail:global_user_id,detail:cookie_text,detail:user_agent,detail:ref_url,detail:loc_url,detail:log_time \
tbl_logs \
/user/hive/warehouse/tags_dat.db/tbl_logs
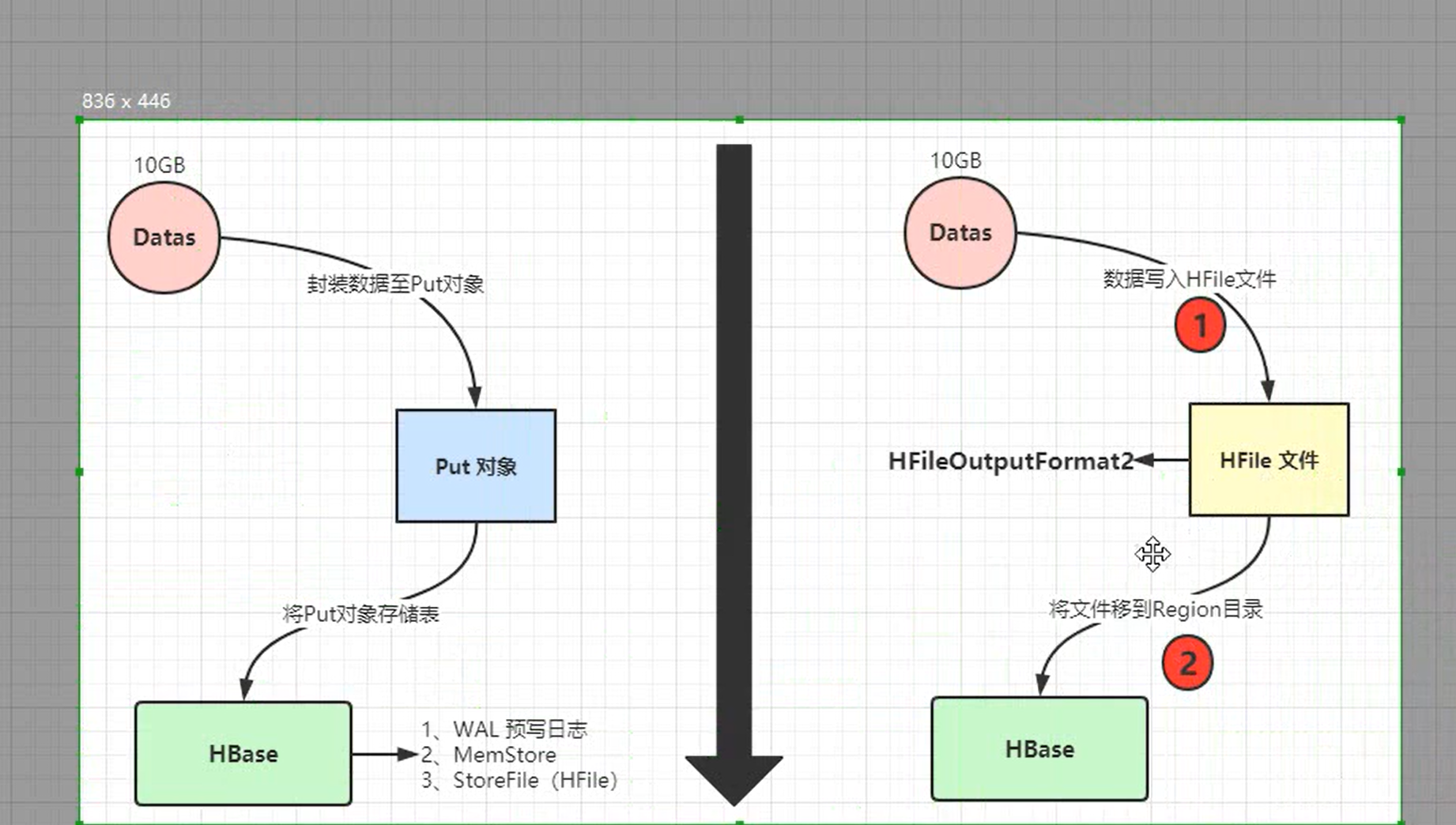
2. 第二种方式:转化为HFile文件,再生成表。
HBase Bulkload加载批量程序
- 第一步:转化为HFile文件
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf ${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.14.0.jar \
importtsv \
-Dimporttsv.bulk.output=hdfs://bigdata-cdh01.itcast.cn:8020/datas/output_hfile/tbl_logs \
-Dimporttsv.columns=HBASE_ROW_KEY,detail:log_id,detail:remote_ip,detail:site_global_ticket,detail:site_global_session,detail:global_user_id,detail:cookie_text,detail:user_agent,detail:ref_url,detail:loc_url,detail:log_time \
tbl_logs \
/user/hive/warehouse/tags_dat.db/tbl_logs
以上任务在执行时会有Reduce阶段,原因在于HFile文件是排序的,包括HBase表分区存储文件以及每一条数据也是排序的。所以这里就是涉及到shuffle。
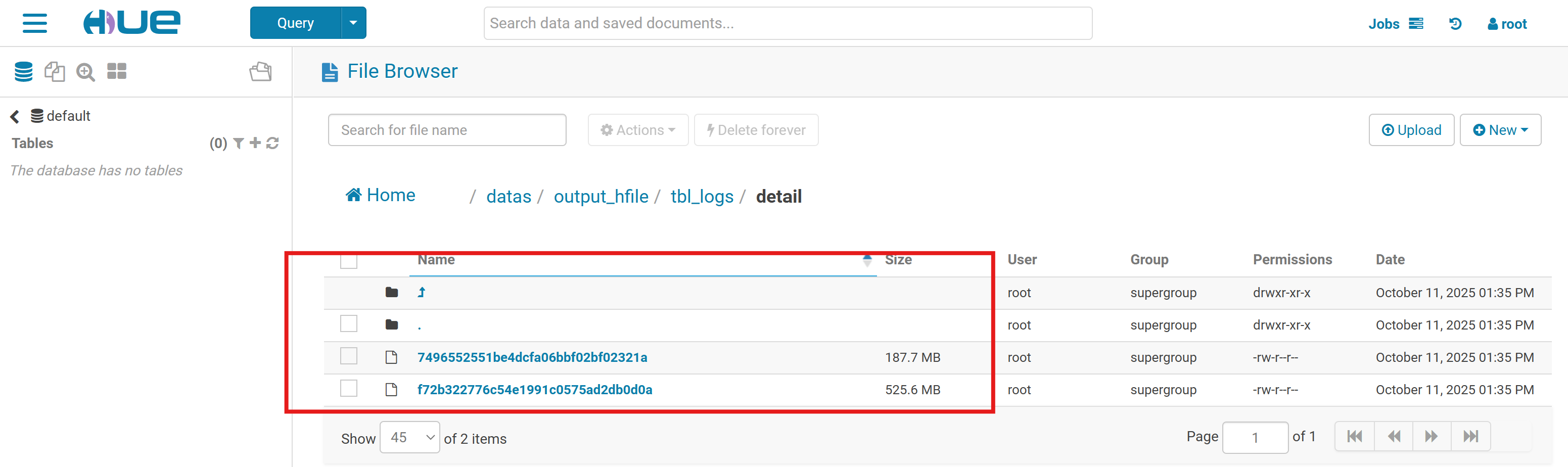
运行结束后,会产生两个文件。产生两个文件的原因是因为在定义tbl_logs表时,该条语句create 'tbl_logs', 'detail', SPLITS => ['189394']使用了分区。
- 第二步:将HFile文件加载到表中
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf ${HADOOP_HOME}/bin/yarn jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.14.0.jar \
completebulkload \
hdfs://bigdata-cdh01.itcast.cn:8020/datas/output_hfile/tbl_logs \
tbl_logs
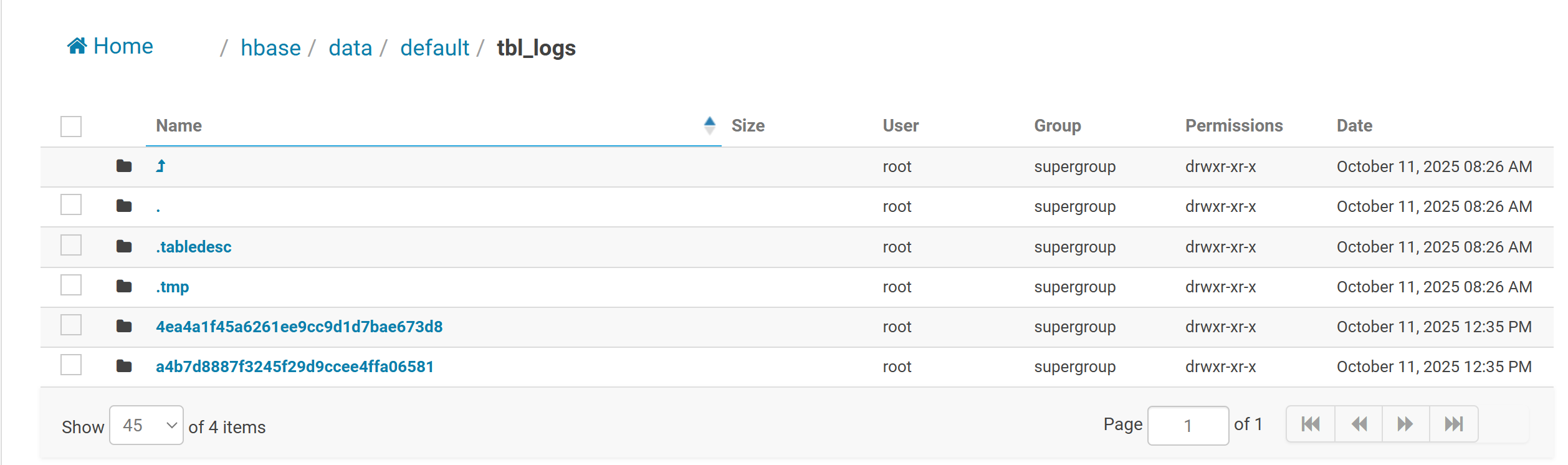
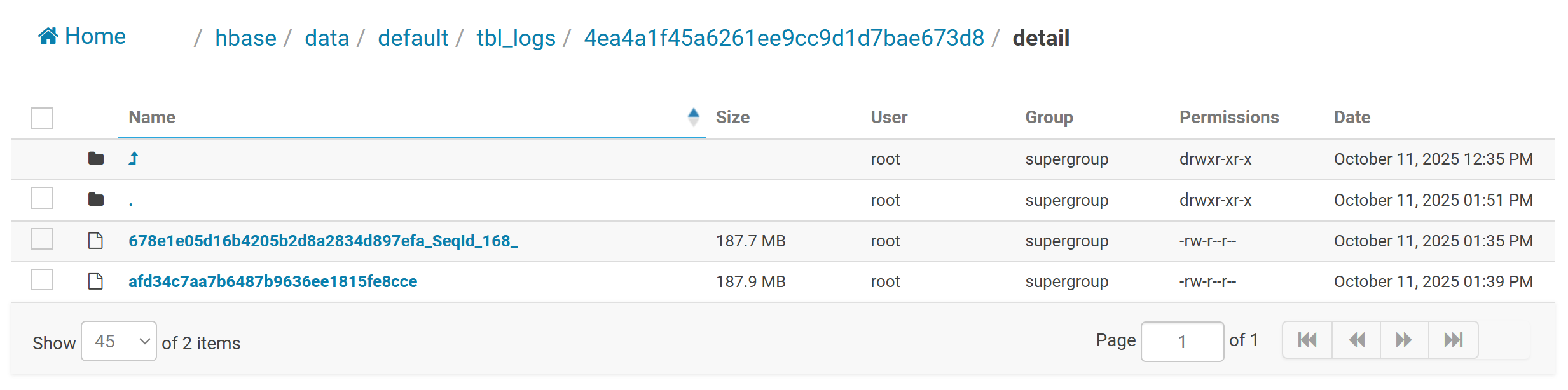
执行完在Hbase下可以看到对应的两个region。以及将两个对应的HFile移动到对应的分区中。
数据迁移 - Spark导入
使用Spark将四张表的数据都做导入;
所有先创建4张表:
create 'tbl_tag_users', 'detail'
create 'tbl_tag_orders', 'detail'
create 'tbl_tag_goods', 'detail'
create 'tbl_tag_logs', 'detail', SPLITS => ['189394']
每个HFile文件中数据有序的,先按照RowKey排序,列簇排序,最后按照列排序。
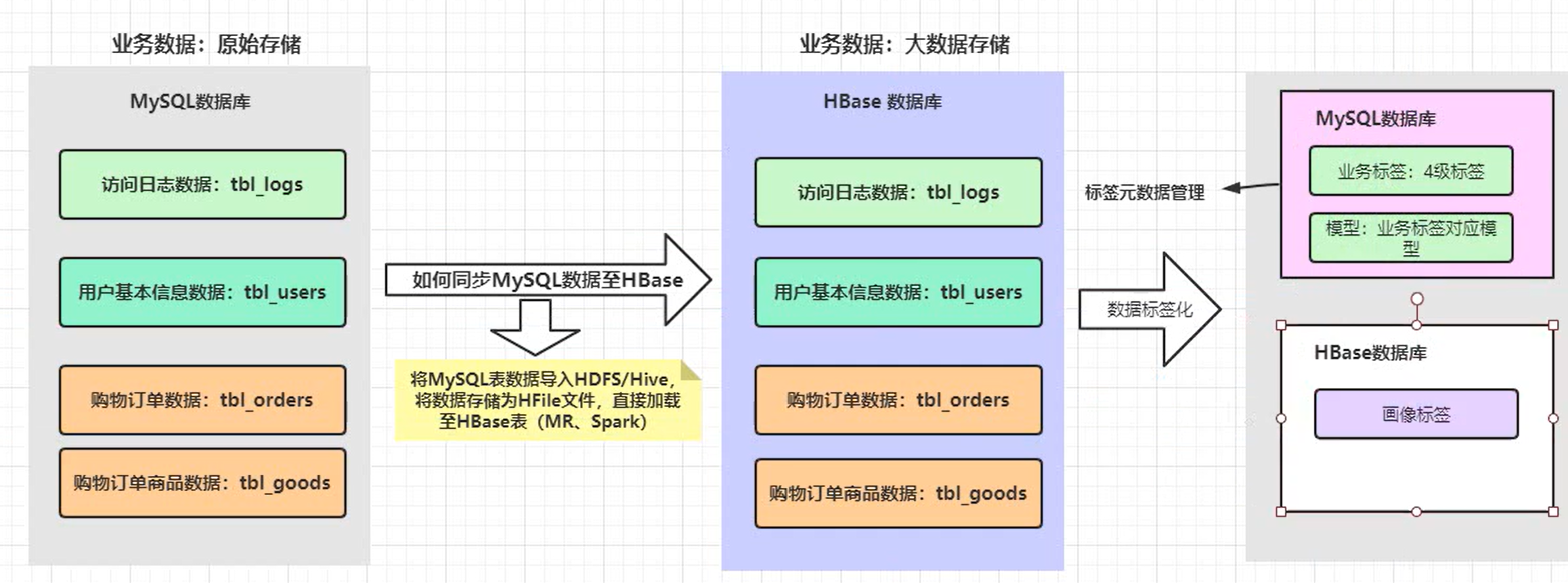
标签模型调度
每个标签对应一个模型,每个模型就是一个Spark应用程序,使用Oozie调度。
- 方式1:编写配置文件,使用命令行运行Oozie Job;
- 方式2:Oozie继承Hue,编写Oozie Job并调度执行;
- 方式3:Oozie Java Client API创建Oozie Job并执行;
标签存储与计算和用户画像开发时模块
- 理解标签数据存储与计算
- 开发整个用户画像时,模块组合及准备环境
- 工具类模块
- Web平台模块
- 标签模型开发模块
标签画像数据
Oozie调度Spark
但在2025年,Oozie已经跟不上时代潮流。推荐使用DolphinScheduler进行任务调度。
由于示例项目中还是使用Oozie,那么简单介绍一下Oozie。
Oozie包含三个组件:
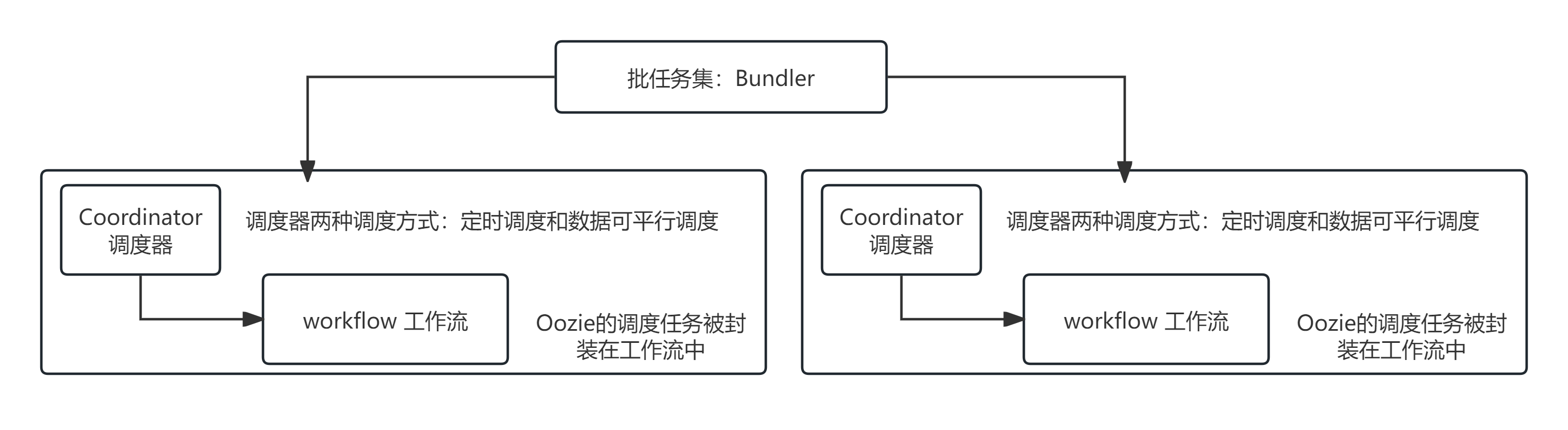
Oozie工作流组成:
第一部分:工作流配置文件:workerflow.xml
配置文件也由三部分组成:
第二部分:Lib,存储依赖第三方jar包
之前实例程序,需要将jar包放在目录中。
上述的文件都需要存储在HDFS目录中
第三部分:Job.properties
每个Job的属性配置文件
其中定义了很多属性,方便在workflow中使用。属于可有可无的。
必须放在本地文件系统的目录中
启动Oozie
OOZIE_HOME=/export/servers/oozie
${OOZIE_HOME}/bin/oozie-start.sh
- 创建OozieClient对象。
- 获取Properties对象,设置 job.properties 的全部内容。
- 提交执行OozieJob。
在编写程序之前,首先需要将工作流或调度器配置文件以及lib中的jar包放到HDFS上。
第四部分 标签模型开发
标签管理
针对用户画像系统来说,标签如何管理和画像标签存储至关重要。
问题:
如何解决频繁新增和删除标签
如何解决不同标签更新时间和频率不同的问题
为什么选择Spark?原因之一就是其支持外部数据源。
使用SpringBoot+VUE的管理系统。
标签存储
横表存储
问题:
- 增加标签,横表更新会很频繁
- 不同标签的计算频率不同
- 计算完成时间不同
- 大量空缺的标签会导致存储稀疏
竖表存储
把所有标签拆开,一个用户有几个标签就,就会有几个标签。
问题:组合查询条件在竖表中非常难查询。
横表 + 竖表存储
标签竖表对计算层支持更好。
标签横表对查询层支持更好,并结合ElasticSearch/Solr来提高查询效率。
Spark计算标签
Spark计算较快、支持外部数据源、编程容易。
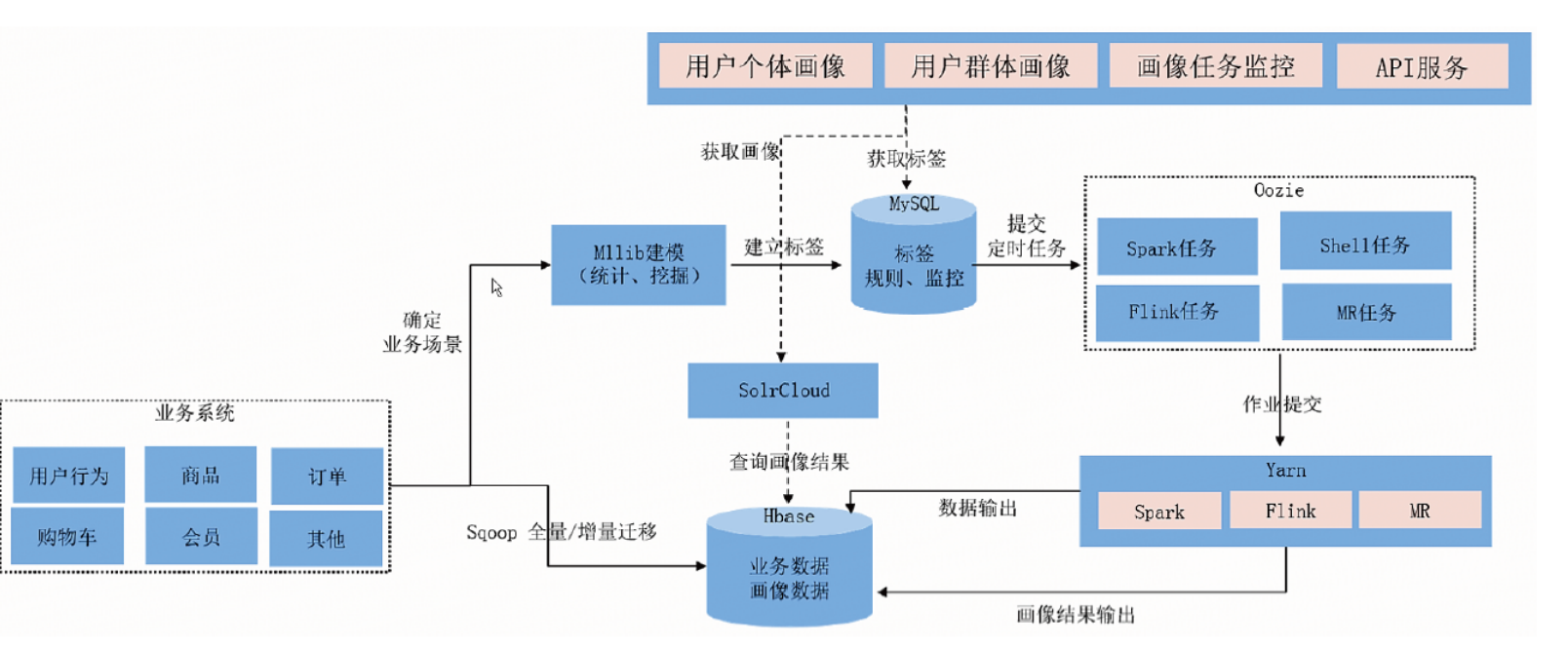
用户画像流程
- 数据迁移 ★
业务系统数据 → HBase表
通过Sqoop全量或增量同步
通过ImportTSV工具的BulkLoad批量加载
通过Spark程序数据迁移同步 - 确定业务场景及标签并建模
- 标签管理平台建立标签
- 标签开发对应Spark程序
- Oozie调度Spark程序运行在yarn集群中
- 画像结果输出到HBase并同步HBase表画像标签数据到ElasticSearch中
- 用户个体画像从HBase竖表中查询
- 用户群体画像从ElasticSearch中查询
第一个模块:标签调度模块
测试代码:测试Oozie功能
jars: “/apps/temp/jars”
model-base: “/apps/tags/models”
hdfs dfs -mkdir -p /apps/temp/jars
hdfs dfs -mkdir -p /apps/tags/models
hdfs dfs -mkdir -p /apps/tags/models/tag_0/lib/
标签模型计算
在本项目中,每个标签(业务标签,4级标签)对应一个模型,每个模型就是一个Spark应用程序。
每个应用程序应该如何开发完成呢?
以下是开发流程:
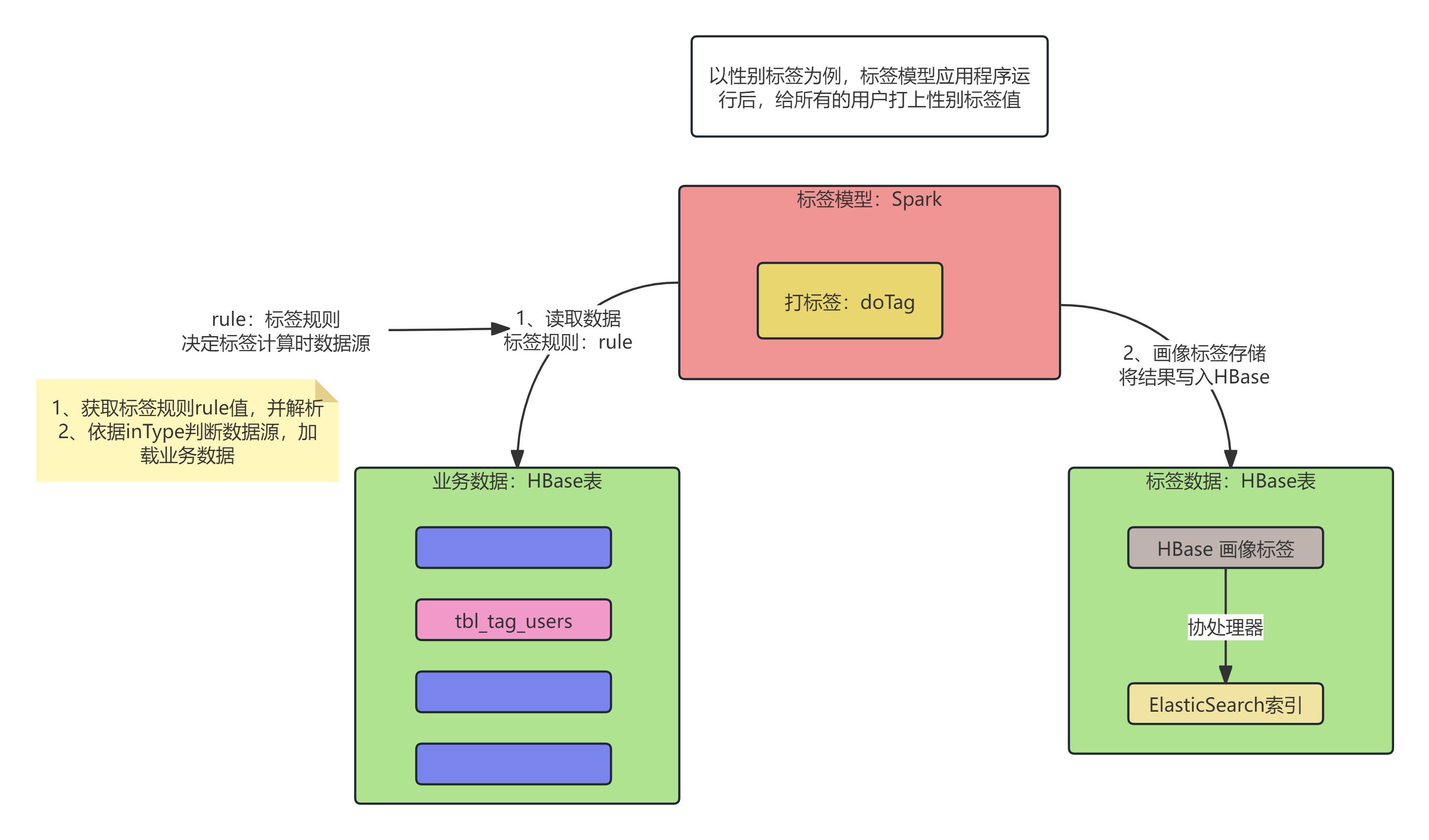
标签模型开发,包含四个步骤:
1)、加载标签数据,获取标签规则rule每个业务标签都有规则,表示此标签计算时业务数据存储的地方(业务数据数据源),比如存储HBase表中。
2)、加载业务数据给用户打标签,需要获取标签的值,从业务数据中获取,比如性别标签,性别信息gender存储tbl_tag_users。
3)、打标签结合属性标签数据和业务数据,给用户打上标签的值:使用标签的标识符标注TagId要使用属性标签中标签规则rule
4)、保存用户标签数据将标签数据保存至HBase表中:
tbl_profileRowKey:
userIdColumnFamily: user,
itemColumns:
userId: 10001
tagIds: 345,387,…
通过SparkSQL对数据进行计算,DataFrame DSL编程。

















 2255
2255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









