







 本文深入解析Vision Transformer (ViT) 论文,探讨如何将Transformer架构直接应用于图像识别任务,通过将图片分割为16x16的patch,形成序列输入到Transformer,挑战传统卷积神经网络的主导地位。实验证明,ViT在大规模数据集上的表现与卷积网络相当,展示了Transformer在计算机视觉领域的潜力。
本文深入解析Vision Transformer (ViT) 论文,探讨如何将Transformer架构直接应用于图像识别任务,通过将图片分割为16x16的patch,形成序列输入到Transformer,挑战传统卷积神经网络的主导地位。实验证明,ViT在大规模数据集上的表现与卷积网络相当,展示了Transformer在计算机视觉领域的潜力。
ViT论文解读
本文主要记录Yi Zhu大佬对于ICLR 2021的一篇论文精读
AN IMAGE IS WORTH 16x16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文地址:https://arxiv.org/pdf/2010.11929.pdf
源码地址:https://github.com/google-research/vision_transformer
标题部分
AN IMAGE IS WORTH 16x16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
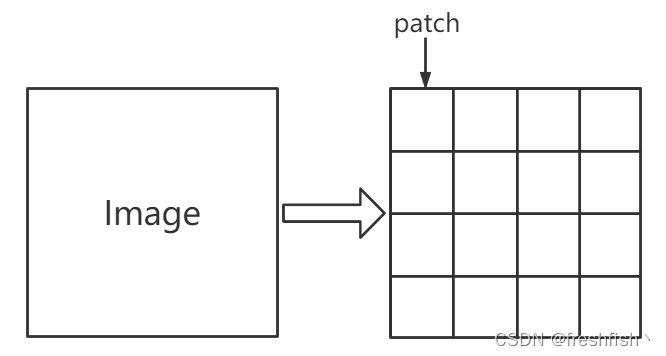
一张图片等价于很多16X16大小的单词
这里的等价指的是把图片看作是很多的patch,每个patch的大小是16x16,那么这张图片就是很多16x16patch组成的。
摘要
作者阐述了Transformer在NLP领域已经大放异彩了,但是在CV视觉领域还是很有限的。在CV的研究中,以往的模型要么是将Transformer中的Attent
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









