






focal-loss
经典loss,针对分类任务数据不平衡问题,在基础的交叉熵上加了一些改动。
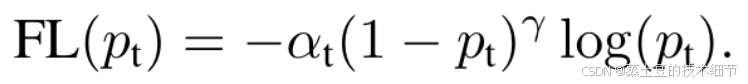
p是数据分到t类的概率,log是交叉熵。
γ
\gamma
γ是个超参数。当你的某条数据分类不准时,给个大loss显然会有帮助,那么
γ
>
0
\gamma>0
γ>0能显著帮助你提升pt过小情况下在整体训练loss中占的比重。
α
\alpha
α也是个超参数,用于t类训练数据loss的权重调整。显然,当t类数据数量过少时,它的loss会被淹没,
α
\alpha
α要让t类更有影响,则可以设为类的逆频率,即t类数据越少,
α
t
\alpha_t
αt越大。
triplet-loss
这是简单的用在embedding中的loss。
假设已经embedding了三张人脸图,两个是小王,一个是小李。显然,小王的照片应该embedding到一起,即使拍照角度不同,而小李embedding应该离远点。
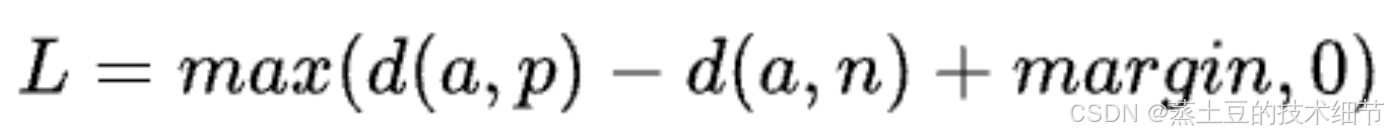
其中,d是距离,后期更常用s,以代表类内相似度,这么描述时可以在这个所谓的类里塞进更多数据。a是anchor,即正例embedding的标准,我觉得是在正例里随便挑一个。p是positive,n是negative,margin是为了让类内相似度>类间相似度。因此,loss的训练目标是:小王的正脸照为anchor,其他小王的照片要和正脸的(类内)相似度高,小李小赵什么的和小王的正脸照(类间)相似度低。当某批数据已经拉开了一段差距(margin)时,就停止训练这个数据。
⚠️注意,triplet-loss只是一个思想,focal-loss也一样。只要能实现“拉开正负例距离”,“加强数据少的类、训练不好的数据 的loss权重”,就行。
circle-loss
针对triplet-loss和softmax,circle-loss发现一个事儿不太对。
假如d(a,p)=0.8,d(a,n)=0.6,与d(a,p)=0.6,d(a,n)=0.4的loss怎么是一样的呢?这俩比起来,我肯定要多训练d(a,p)=0.8,d(a,n)=0.6的,因为以0.5为判断相似度的界,它不合格。
针对这种问题,circle-loss做了进一步优化。
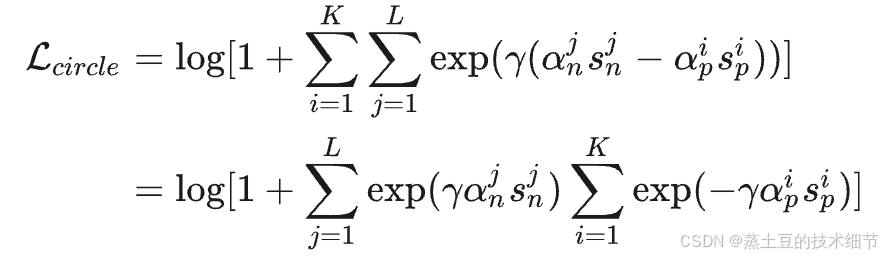
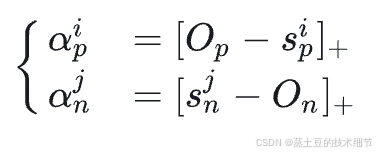
这个式子和之前的长得都不一样。先看下面这个,下面的是triplet-loss思路的另一种实现:
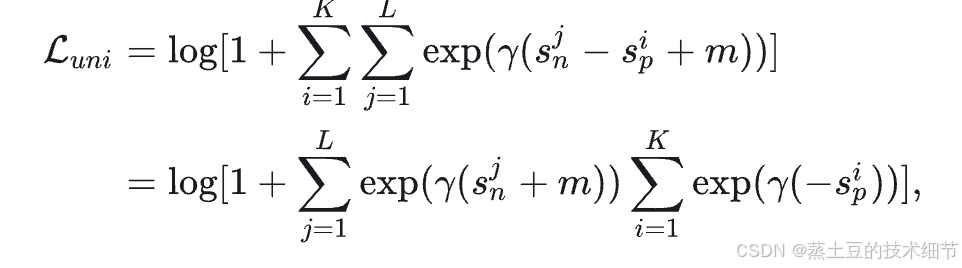
背景是我们有一个batch,batch里有多个类别的数据,每个类数据数量还不一样,例如有3张小王4张小红8张小李。每个类找一个anchor,然后再计算类间相似度和类内相似度,例如3张小王和小王anchor的内积相似度的均值作为类内,小王anchor和其他照片两两配对的内积相似度均值是类间相似度。具体一共有多少类内/类间相似度我不知道,看你想抽样几个了。总之,K设为类内相似度数量,L为类间相似度数量。
γ
\gamma
γ超参放缩相似度的效果。
反推一下,要L尽量小,log增函数,还有1+,后半部分>0,保证loss>0。综上,在两个累加项里,前者exp里的sn要尽量小,后者sp要尽量大,这就是该loss的目标。另外sn和sp在[0,1]之间。这就是triplet-loss的思想,让K=1,L=1,就更明显了,除了形式上更平滑,其他的和triplet-loss思路一致。
circle-loss对它的改动有以下两点:
- margin m去掉了
- 加了个放缩值 α \alpha α。
α \alpha α公式也给了,O是期望的相似度值,Op当然是>0.5,On当然是<0.5,以此让训练不完全的类内/类间相似度被加强。而在这放缩下,本来margin的目的是怕类内-类间=0,训练不了,加上放缩了就绝对不会出现这种情况了,所以不需margin了。

















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









