






 文章讲述了在数据预处理阶段如何进行异常值分析和处理,通过读取数据并进行可视化展示,识别并删除超出阈值范围的异常数据。接着,文章介绍了数据的归一化处理,使用sklearn的MinMaxScaler将数据缩放到[0,1]区间,以简化后续计算并便于不同尺度特征的比较。
文章讲述了在数据预处理阶段如何进行异常值分析和处理,通过读取数据并进行可视化展示,识别并删除超出阈值范围的异常数据。接着,文章介绍了数据的归一化处理,使用sklearn的MinMaxScaler将数据缩放到[0,1]区间,以简化后续计算并便于不同尺度特征的比较。
数据:
# 下载需要用到的数据集
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt
数据异常值分析
- 在数据清洗阶段,需要对异常值进行处理,根据实际需求异常值可以:删除(抛弃)或者标注保留。
- 将所有数据进行分析,设置阈值范围,当数据超过某个阈值范围设定为该数值处于异常情况。将需要处理的数据进行可视化展示,代码如下所示。我们将数据的正常值范围设定为-7.5-7.5,超过该阈值范围的数据即为异常数据。
# 导入数据分析工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
# 读取数据
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
#异常值分析
plt.figure(figsize=(18, 10))
plt.boxplot(x=train_data.values,labels=train_data.columns)
plt.hlines([-7.5, 7.5], 0, 40, colors='r')
plt.show()
可视化结果:
从图中可以明显看出来,一些非-7.5-7.5之间的数据也就是异常数据。
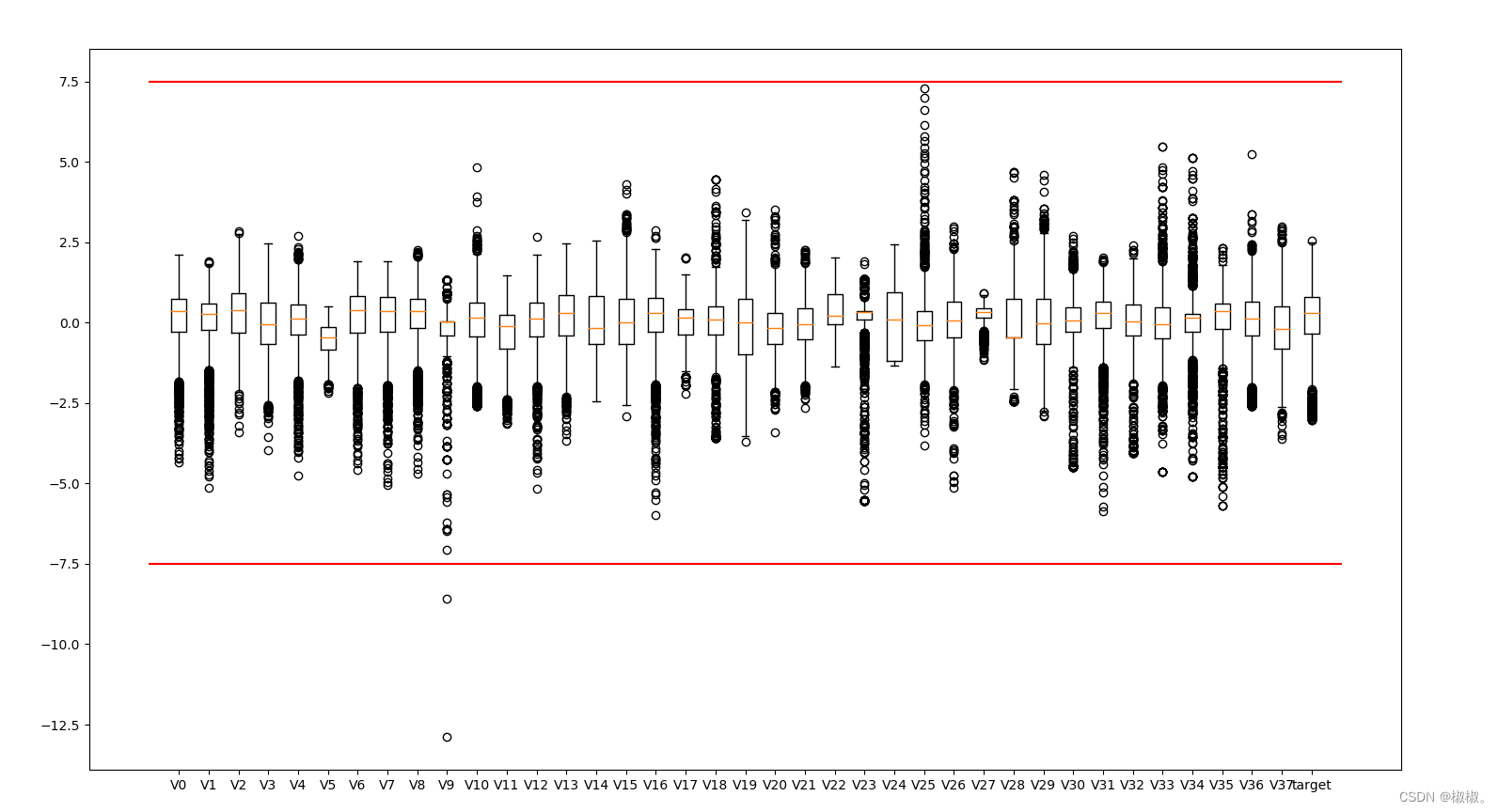
异常数据处理:
- 针对异常数据,这里采取删除的形式。
## 删除异常值
train_data = train_data[train_data['V9']>-7.5]
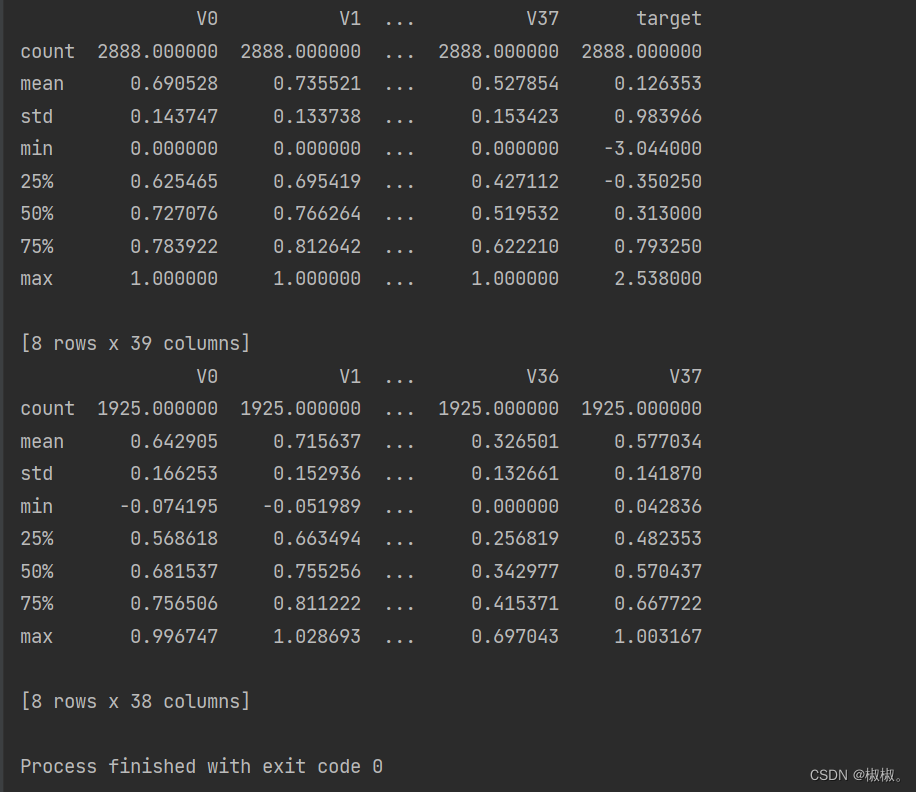
train_data.describe()
数据的归一化处理:
归一化的作用:
- 将数据映射到指定的范围,便于数据的计算处理。
- 把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。经过归一化后,将有量纲的数据集变成纯量,还可以达到简化计算的作用。
归一化使用的方法:
- 归一化一般将数据范围订到定为[0,1]或者[-1,1]区间,也可以自行定义。
- 这里的归一化处理采用的是sklearn的min_max_scaler来进行归一化处理,将带归一化数据进行获取后,将数据分为归一化[0,1]之间。
from sklearn import preprocessing
features_columns = [col for col in train_data.columns if col not in ['target']]
min_max_scaler = preprocessing.MinMaxScaler()
min_max_scaler = min_max_scaler.fit(train_data[features_columns])
train_data_scaler = min_max_scaler.transform(train_data[features_columns])
test_data_scaler = min_max_scaler.transform(test_data[features_columns])
train_data_scaler = pd.DataFrame(train_data_scaler)
train_data_scaler.columns = features_columns
test_data_scaler = pd.DataFrame(test_data_scaler)
test_data_scaler.columns = features_columns
train_data_scaler['target'] = train_data['target']
train_data_scaler.describe()
test_data_scaler.describe()


















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











