



 ESPNet是针对语义分割的轻量级网络,采用高效空间金字塔卷积模块(ESPModule),结合point-wise卷积和空洞卷积降低计算复杂度。ESPNetv2进一步优化,引入深度可分离空洞卷积和EESP模块,提高精度并减少参数。此外,还设计了循环学习率调度器,并通过shortcut连接输入图像来减少信息损失。
ESPNet是针对语义分割的轻量级网络,采用高效空间金字塔卷积模块(ESPModule),结合point-wise卷积和空洞卷积降低计算复杂度。ESPNetv2进一步优化,引入深度可分离空洞卷积和EESP模块,提高精度并减少参数。此外,还设计了循环学习率调度器,并通过shortcut连接输入图像来减少信息损失。
论文标题:ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
论文地址:https://arxiv.org/pdf/1803.06815v2.pdf
开源地址: https://github.com/sacmehta/ESPNet
论文思想
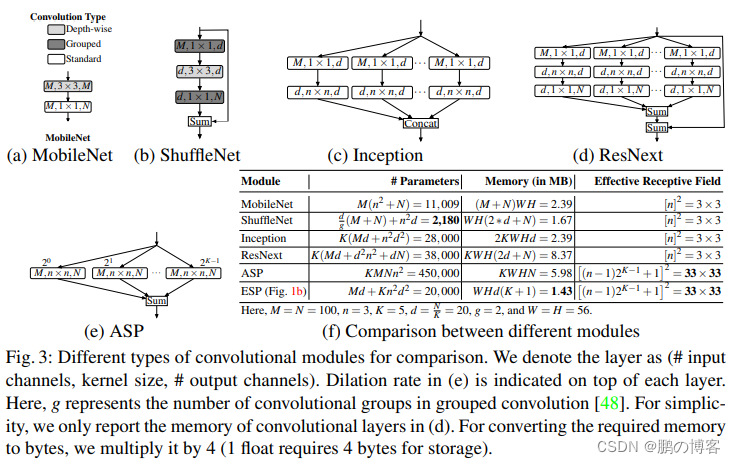
ESPNet是用于语义分割的轻量级网络,主要思想基于传统卷积模块设计,提出一种高效空间金字塔卷积模块(ESP Module)
该模块包含point-wise卷积和空洞卷积金字塔,有助于减小模型运算量和内存、功率消耗,以提高在终端设备上的适用性
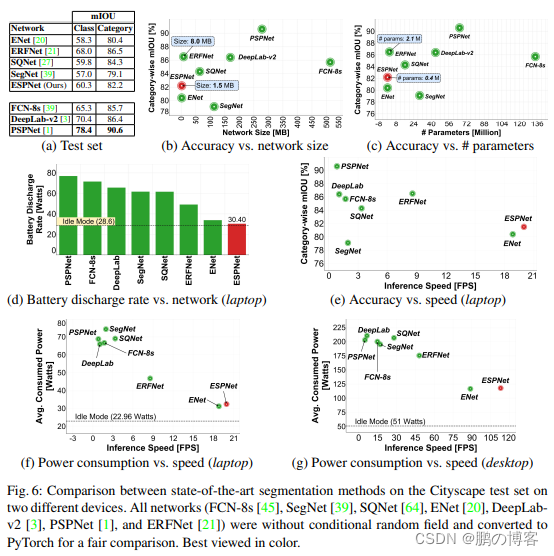
综合比较,ESPNet能在GPU/笔记本/终端设备上达到112FPS/21FPS/9FPS
具体实施
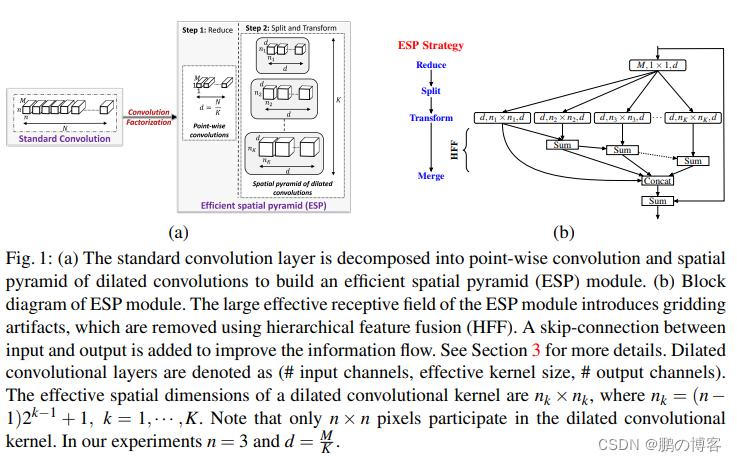
ESP模块将标准卷积分解成
point-wise卷积和空洞卷积金字塔(spatial pyramid of dilated convolutions)
point-wise卷积将输入映射到低维特征空间
空洞卷积金字塔使用K组空洞卷积的同时下采样得到低维特征
这种分解方法能够大量减少ESP模块的参数量和内存,并且保持较大的有效感受域
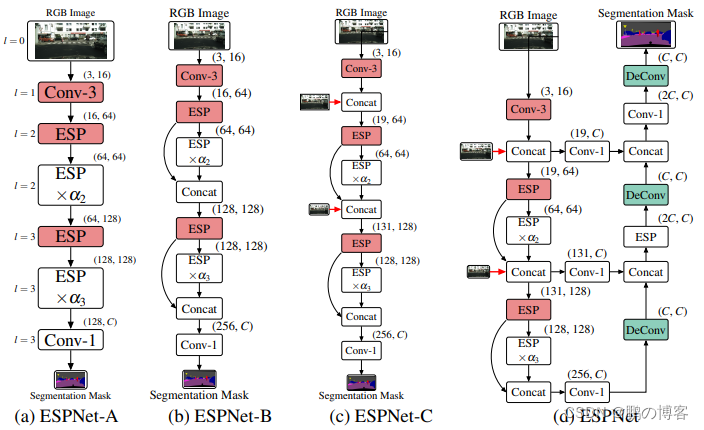
网络架构如下
实验结果

改进
论文标题:ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network
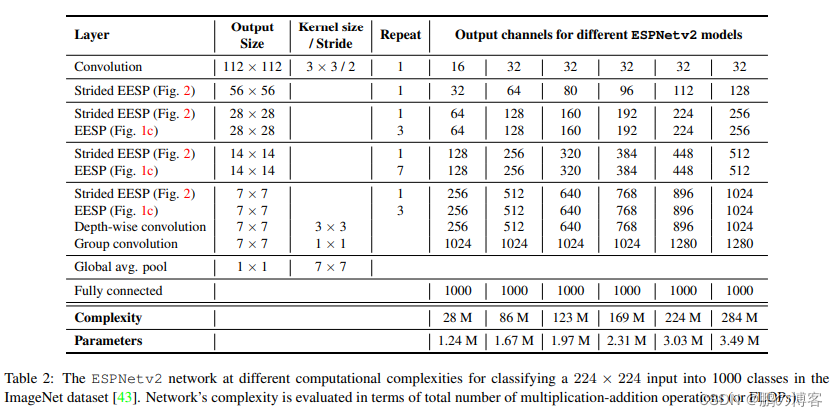
ESPNetv2主要基于ESPNetv1进行了模型轻量化处理,主要包括:
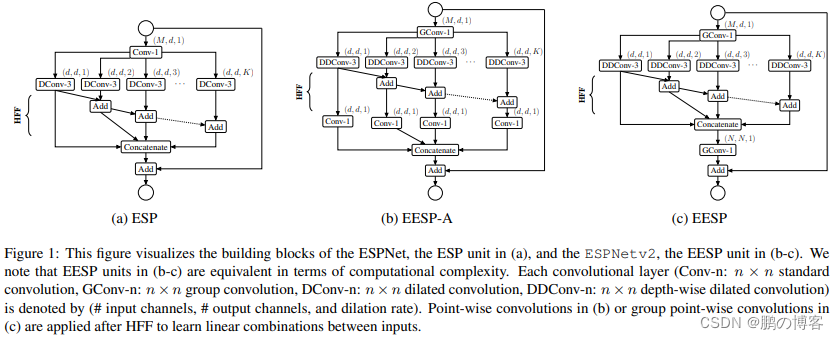
基于深度可分离空洞卷积以及分组point-wise卷积改进ESP模块,提出了EESP(Extremely Efficient Spatial Pyramid)模块
相对于ESPNet拥有更好的精度以及更少的参数
设计了cyclic learning rate scheduler,比一般的固定学习率的scheduler要好
其中下采样版本的EESP模块(Strided EESP with shortcut connection to an input image),主要改进如下
修改深度可分离空洞卷积为stride=2的版本。为模块原本的shortcut添加平均池化操作
将element-wise相加操作替换为concate操作,这样能增加输出的特征维度
为防止随着下采样产生的信息丢失,添加一条连接输入图像的shortcut
该路径使用多个池化操作来使其空间大小与模块输出的特征图一致
然后使用两个卷积来提取特征并调整维度,最后进行element-wise相加



















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











