







 谷歌研究人员提出MLP-Mixer模型,这是一种全新的基于多层感知机的视觉架构,旨在图像分类任务中提供与传统卷积神经网络和Transformer相竞争的表现。MLP-Mixer通过独特的混合层设计,在不依赖卷积的情况下有效捕捉空间信息。
谷歌研究人员提出MLP-Mixer模型,这是一种全新的基于多层感知机的视觉架构,旨在图像分类任务中提供与传统卷积神经网络和Transformer相竞争的表现。MLP-Mixer通过独特的混合层设计,在不依赖卷积的情况下有效捕捉空间信息。
整体导读:
卷积神经网络(CNNs)是计算机视觉的主流模型,近年来,基于注意力的网络,如vision transformer也得到了广泛的应用。2021年3月4日,谷歌人工智能研究院Ilya Tolstikhin, Neil Houlsby等人研究员提出一种基于多层感知机结构的MLP-Mixer并在顶会“Computer Vision and Pattern Recognition(CVPR)”上发表一篇题为“MLP-Mixer: An all-MLP Architecture for Vision”的文章。MLP-Mixer包含两种类型的MLP层:一种是独立应用于图像patches的MLP(即“混合”每个位置特征),另一种是跨patches应用的MLP(即“混合”空间信息)。当在大数据集上训练时,或使用正则化训练方案时,MLP-Mixer在图像分类基准上获得有竞争力的分数,并且预训练和推理成本与最先进的模型相当。作者希望这些结果能激发出更深入的研究,超越成熟的CNN和transformer领域。
论文名称:MLP-Mixer: An all-MLP Architecture for Vision
原文链接:https://arxiv.org/pdf/2105.01601.pdf
会议名称:Computer Vision and Pattern Recognition

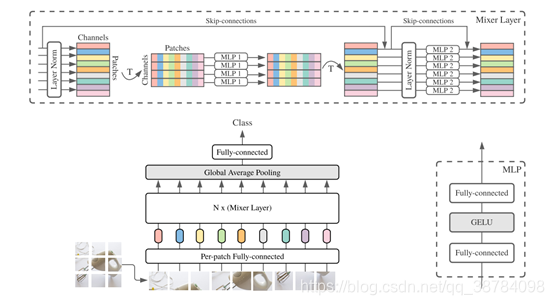
值得注意的是最近LeCun 的 twitter发表观点,其实MLP-Mixer在很多地方使用卷积,只是用一堆奇奇怪怪的词来描述自己在做的运算。
感兴趣的同学可以读一下https://mp.weixin.qq.com/s/cl5QCRgeY8zWc3AwE4waZQ
MLP模块代码
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)Mixer Layer代码
class MixerBlock(nn.Module):
def __init__(self, dim, num_patch, token_dim, channel_dim, dropout=0.):
super().__init__()
self.token_mix = nn.Sequential(
nn.LayerNorm(dim),
Rearrange('b n d -> b d n'),
FeedForward(num_patch, token_dim, dropout),
Rearrange('b d n -> b n d')
)
self.channel_mix = nn.Sequential(
nn.LayerNorm(dim),
FeedForward(dim, channel_dim, dropout),
)
def forward(self, x):
x = x + self.token_mix(x)
x = x + self.channel_mix(x)
return x整体模型代码
class MLPMixer(nn.Module):
def __init__(self, in_channels, dim, num_classes, patch_size, image_size, depth, token_dim, channel_dim):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
self.num_patch = (image_size // patch_size) ** 2
self.to_patch_embedding = nn.Sequential(
nn.Conv2d(in_channels, dim, patch_size, patch_size),
Rearrange('b c h w -> b (h w) c'),
)
self.mixer_blocks = nn.ModuleList([])
for _ in range(depth):
self.mixer_blocks.append(MixerBlock(dim, self.num_patch, token_dim, channel_dim))
self.layer_norm = nn.LayerNorm(dim)
self.mlp_head = nn.Sequential(
nn.Linear(dim, num_classes)
)
def forward(self, x):
x = self.to_patch_embedding(x)
for mixer_block in self.mixer_blocks:
x = mixer_block(x)
x = self.layer_norm(x)
x = x.mean(dim=1)
return self.mlp_head(x)


















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











