






什么是目标检测
目标检测指的是检测出图片中物体的位置并作出标注。不同于分类网络的每个图片只有一个lable。目标检测的网络往往会对图片中的多个目标进行定位。(多个lable信息)
一般来说可以将分类网络视为
一张图片输入;
一个类标签输出。
而目标检测网络可以被视为:
向网络输入一张图像;
获得多个边框和类标签作为输出。
yolo 模型介绍
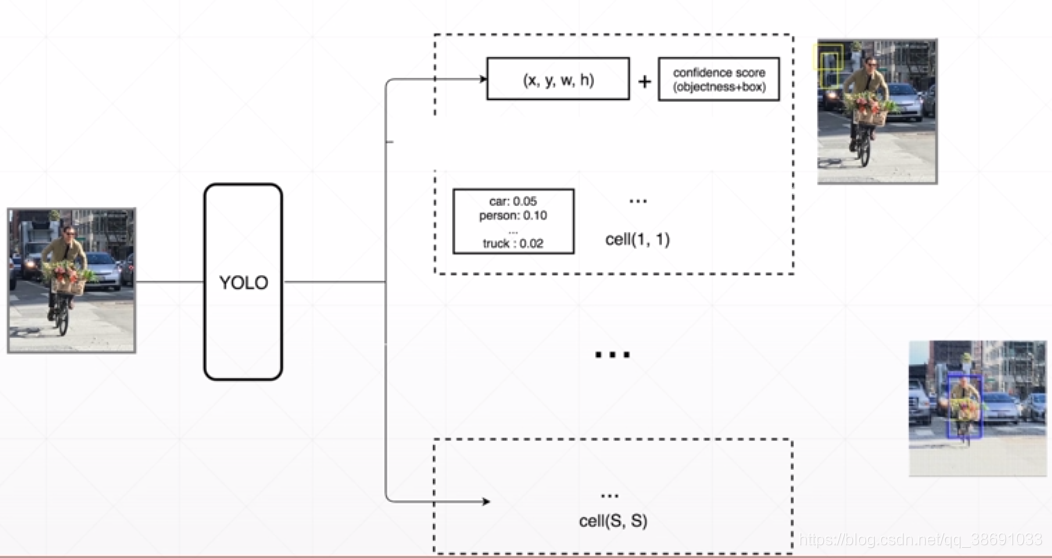
上文提到了,目标检测网络是要获得多个边框作为输出。那么,原始边框的获取就成为了一个问题。我们都知道卷积可以聚合空间信息。那么,可以理解成原始图片和通过卷积神经网络计算而产生的特征图 是具有某种相对空间上的关系。既,深度卷积层输出的特征图中的每个向量是可以映射回原图的。如下图所示

那么利用这种属性,是否就可以设计一种网络。计算出原始图片中物体的位置信息呢。
目标检测V0.1

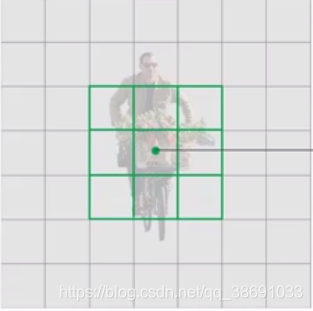
如上图所示,若将原始图片分为若干个区域(box)。通过若干层的卷积降维后。512512尺寸的原始图片被降维成77的特征图(上图右侧)。而这个7*7是由 49个向量组成。每个向量代表了部分图片的信息。
在目标检测网络中,只需要让这个 向量 中包含一个置信度 Confi(0~1) 信息。即可表示在原图对应位置上有没有物体。若这个向量 输出的 C(confi) 等于 1 则表示该向量 原图中的对应位置有物体。
输出的理想值已经得到,我们还需要一个target(目标值)。这个target是手动标注的。也是一个 7* 7的矩阵。将512512的原图,映射到 77的target上,,有目标的位置 置为1 ,其他位置置零。
问题
1、V0.1 这种 映射方式。只能大概判断目标在哪个区域,而不能精准到像素点。位置关系相当不精准。
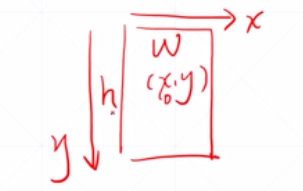
而我们需要精准的获得原始图片中物体的中心点信息,物体框高度信息,宽度信息(x,y,w,h)
2、V0.1没有目标框内的类别信息,
为了解决上面两个问题。则有了目标检测V1
目标检测YOLO.V1
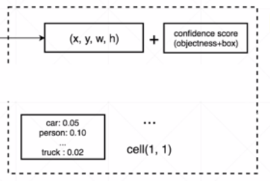
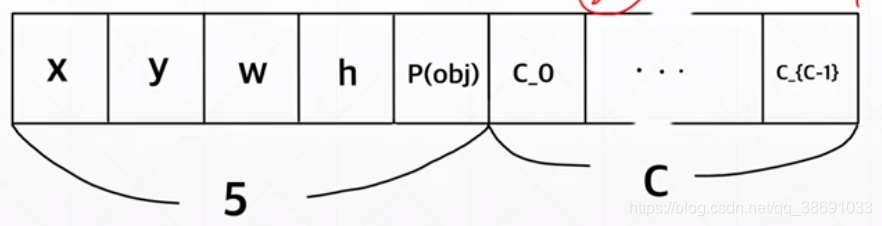
首先,我们需要预测出(x,y,w,h)+ 种类 。那么我们理想中的输出就应该由一个原本的标量C 变为一个Tensor。这个Tensor不但包含 原本的置信度信息(c),同时也要包含检测框的中心信息(x,y),检测框的宽度(w),检测框的高度(h)还有预测的类别信息(0.1,0.25,…).也就是
这里说明一下。yolo区别与Fast-RNN等其他网络的最主要的原因是,Fast-Rnn和其他Rnn的变种是先将这个区域发现出来,然后再对这个区域进行分类。而yolo则更高效的将这两个步骤结合。
这里的通过卷积网络提取到向量 就应该是 一个 n维的tensor n = (x, y, w, h, c,(类别概率))
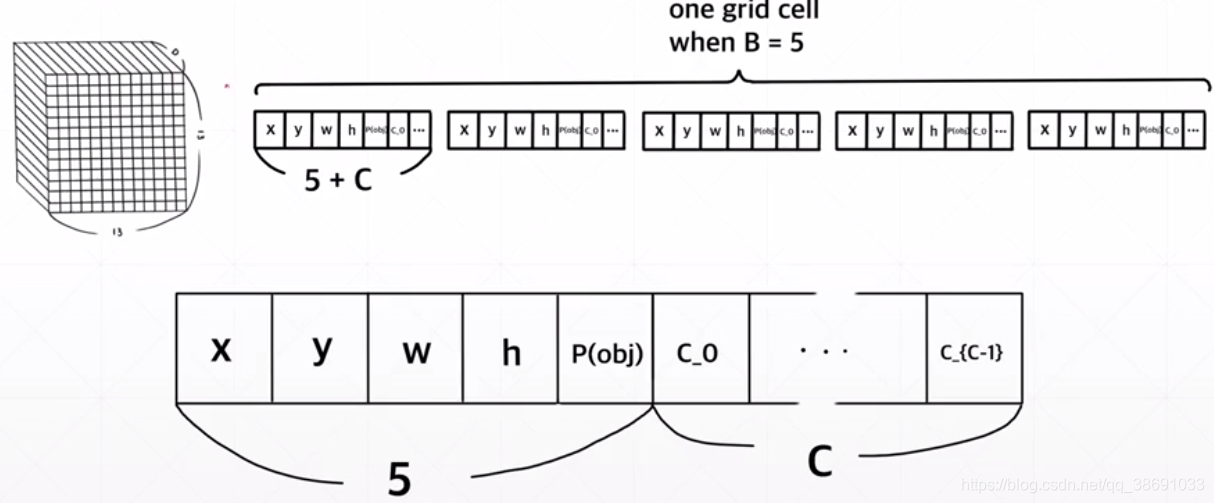
YOLO.V1中是 5+20 .(20分类)
不过再原论文中,采用的是 5+5+20 .另外的一个 5 是指 另外一个box的位置信息。再工程中,择优2选1.
最终的shape为:
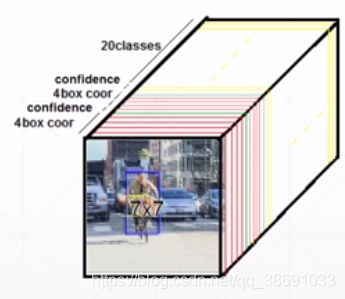
YOLO网络模型
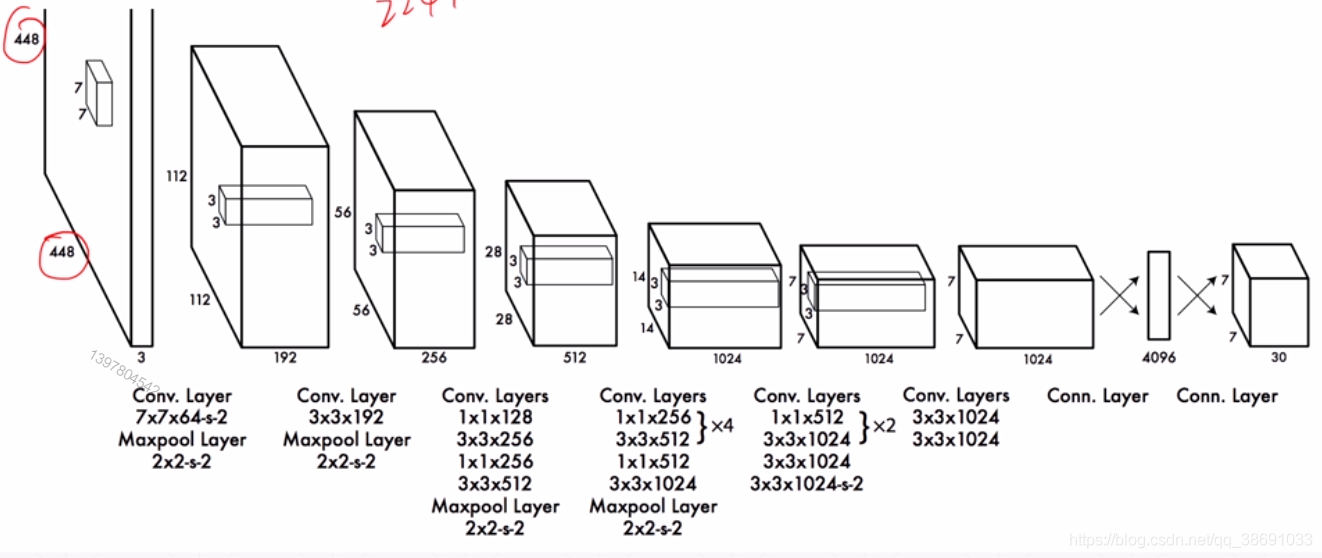
可以理解成再送入最后一个
卷积层之前的网络可以理解成一个分类网络。通过全卷积,或者转置卷积输出到最后 7730的Tensor。
YOLOV1训练方法
分类网络,是通过 输入x 得到预测值 y_ ,让后比较y_与标签y的差。通过bp来更新网络中的参数。
在分类网络中, y_可以简单理解成 一个一维的Tensor(0.1,0.25,…)但是在目标检测网络中。y_应该是一个shape为(N,5)的Tensor 。这里的N指的是图片中box的数量。(每个图片中由于要检测的物体不同,物体数量也不同,所以应该有不同数量的box)。5指的是box的位置信息(x,y,w,h,c)
那么 我们就需要将这个多变的(N,5)变为网络的target的值。这里不同于分类网络中直接one_Hot成一个一维的tensor。
理想中的target因该是一个7730的tensor。每个box 都会映射到 这个7730中的一个点上(1130)而 这个box的 (x,y,w,h )+ c + 类别的分类(20类)
那么由卷积网络得到的target就是对应位置的box的信息 + box的置信度 + box内物体的类别(one_Hot)
误差计算
通过target 与 预测值 之间的 交叉熵(CE)或者均方误差(MSE)来更新网络参数
预测
从两个 box 中选择一个好的 (两个box为20 +5 +5的shape)。对所有的box由置信度进行过滤 。比如confi> 0.7 。假设原来7*7个数的box 经过 过滤后,留下来10个box 。我们再对这写box用NMS(非最大值抑制)来去掉重合度高的Box。剩下的就是整幅图得到的box
YOLO.V2
特征抽取网络 DartNet-19
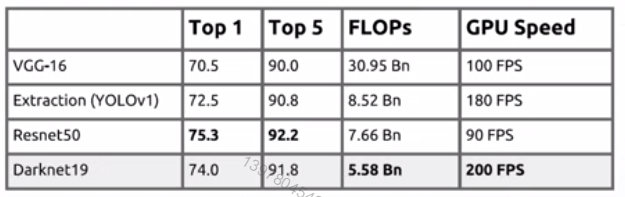
提升的原因:
1、DarkNet网络中增加了BN层。
2、去掉最后的全连接分类层,(原因是全连接网络会破坏掉原图中空间位置的关系)。而用若干层卷积层替代
BOX的改变
再yoloV1 中,box的(x,y ,w,h)决定了box的位置信息,而实际上。在训练中 , (w,h)的取值范围是(-∞,+∞),这就使得网络输出范围很大。导致了target 和 网络输出结果 差距很大。影响训练效果。
解决方法:
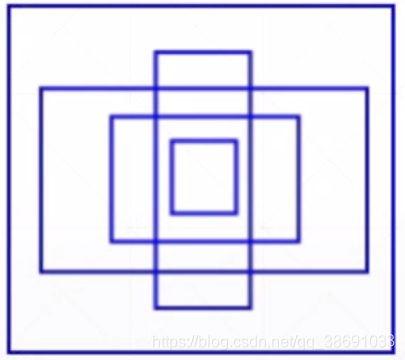
先给出一些备选框(Anchors),然后通过神经网络来预测 target 和 预选框之间的 偏移。 这无形中极大程度的降低了网络训练的难度。
Anchors(备选框)的选择不能太多,并且要有代表性(根据数据集的需要)。经过统计,yolo提供的Anchors如下图
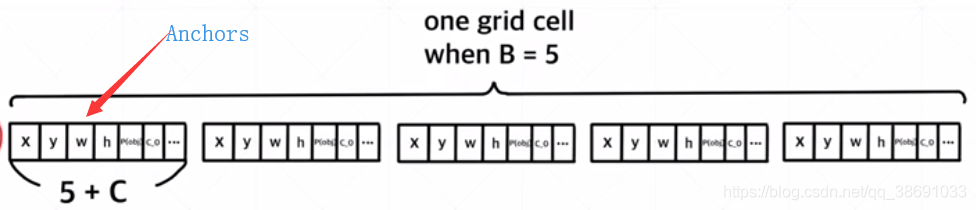
Anchors对神经网络计算的影响

如图片中所示,最后的7*7的输出中,没个点都有这么5个备选框。(不同于V1,每个位置值预测2个框)。根据target信息,将预测准确的备选框选中,其他备选框清除。(根据IOU指标)
总结
YOLOV2相对V1,主要是从2个备选框(V1网络中其实是一个,不过在工程中又加了一个),变为了通过数据集统计得到的5个备选框。同时,这5个box的输出也不是box的真实位置,而是同 target中box的偏移量。
YOLOV2的输出向量
在yilov2中,特征抽取网络提取到的特征向量被 下采样 到1313的尺寸(yolov1是77),这个值可以人工设定。
1313 中 ,每个网格点输出的 的向量如上图,一共有5个Anchors。每个Anchors也是由(x,y,w,h, + p + 类别概率)组成。但是不同于v1,这里的(x,y,w,h)都是预测到的box 和target中的box 之间的偏移量。
输出就是(5(5+20)= 120 )的向量。这里面的 5+20 指的是(x,y,w,h+ p + 类别概率)
所以 我们通过特征提取网络。在经过下采样得到的就因该是如下图所示的 13* 13* 120 的一个tensor
这里需要注意,由于每一个Anchors 都带有 目标概率值。那么也就可以表示box内物体可以有多种类别。(人抱猫)
另外,在v2中,置信度也 p(obj) 代替。
这里的P(obj) 表示的是Anchors box 和target box中物体的重合比例:IOU。
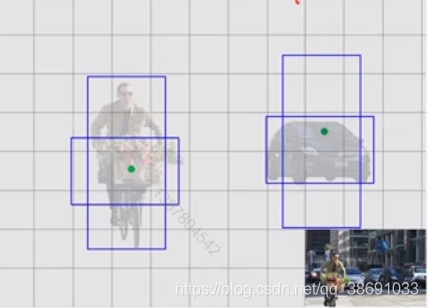
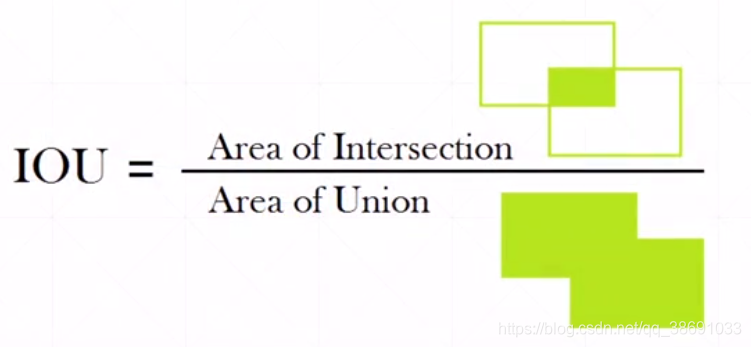
IOU 交并比
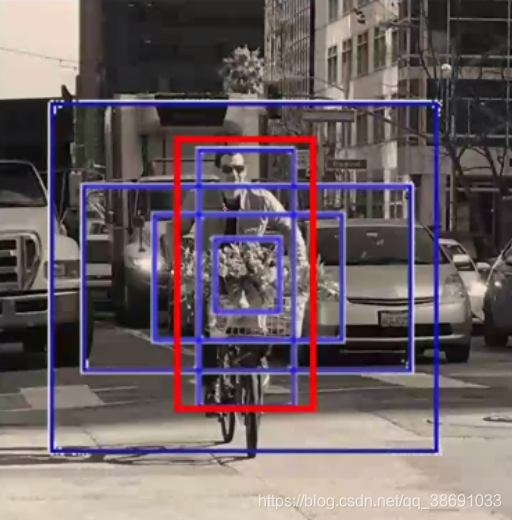
如图所示,红色的是target box,蓝色的是Anchors box。我们不仅仅希望 预测到的box在 target 的box中。而是希望两者重合区域,占二者的共同区域越大越好。则有了交并比。
输出tensor的改变
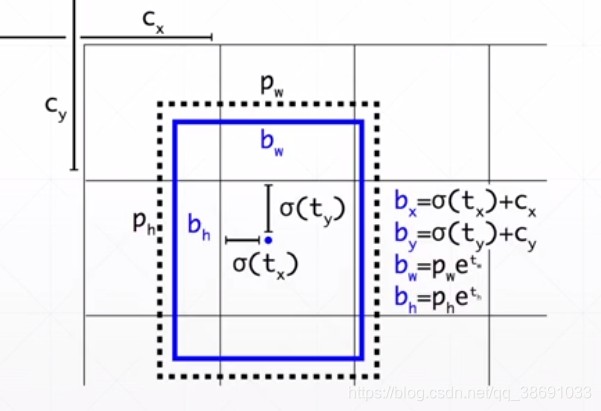
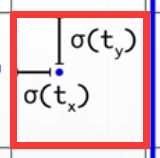
通过网络得到的预测值(Tx,Ty,Tw,Th)其中对Tx和Ty用sigmoid函数处理,这样可以保证检测box的中心点仍然在原本的 区域内
Tw和Th分别通过幂指函数变为 预设的 base box的 w,h 之间的倍率。
小结:
YOLOV2 对比 V1 一共做了3点改进。
首先是网络的改进(DarkNet中增加了BN层)。
其次是预设了5个box (Anchors)。
最后是通过计算偏移量(Tx, Ty, Tw,Th,Pob)来加快网络计算速度。
YOLOV2算法框架
1、Compose Target
2、Forward
3、Loss
Compse Target过程
13135*(5+20)的Tensor中。每一个点都应该对应一个Anchors引出的5个预设box
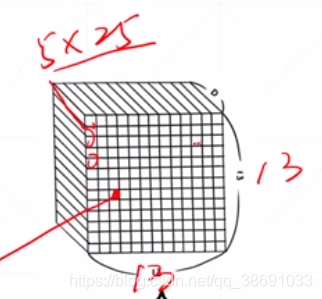
而这5个预设box中只有一个 是 和Target 的box 的IOU最大的。写入到标红位置。然后清零另外4个此锚点预设的box。
此过程仅仅用到了原图像以及图像中目标的位置关系 和 映射到13*13 5(5+20) 这个Tensor之间的等价变换,并没有用到神经网络抽取的特征(类似于one_hot)
Forward
图片经过网络后 ,得到了 一个 1313125的Tensor,这个Tensor和我们的Target之间计算loss就可以了 。其中 (x,y,w,h,p)都是离散值。直接计算这5个之间的MES就好。而后面的(125 )就是一个分类问题,直接采用CE就可以了 。
LOSS
1、与Target中 x,y,w,h的偏差
2、分类误差
3、IOU(与实际的iou的差)
Test
去做Test之前。我已经拿到了 一个1313(525)的Tensor。映射到原图中可以理解成下图

由这个Tensor,可以拿到1313*5 个 box (每个网格有5个 预设box)。通过IOU,可以过滤掉一部分(P > 0.7等)。但剩下的还有很多。

这里就需要另外一个方法——NMS
NMS(非最大值抑制)
首先先来说明一下NMS做了什么。
通过神经网络,我们得到了 13135 的box。再通过IOU后。假设我们得到了40 个 box,这些box的位置信息为(x,y,w,h + 类别概率)最后经过 NMS 进一步对box进行过滤。留下只有几个box。(比如剩下5个box,他们的shape为 (x,y,w,h,+ 类别))
思想如下

如上图所示,我们如果发现一堆box 中有大部分是重叠的。那么网络就没有必要预测所有的Box,只需要预测这里面 IOU最高的那个box。即,取得 IOU最高的那个box
总结
yolo系列 和分类网络的区别并不是很大。主要区别如下
1、构建Target。需要人工把box匹配到目标上去(框出来)
2、网络输出的不是一个一维向量,而是一个 1313(5*25)的Tensor
3、最后loss的计算方式不同,分为3个小部分进行计算。分别是位置的偏移损失、IOU的损失、和 分类问题的损失。
参考文献


















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









