







 本文介绍了ConvMixer模型,它是对Vision Transformer和MLP Mixer的融合,通过深度可分离卷积进行特征混合。研究发现,大卷积核能提升模型性能,且ConvMixer在网络结构上不使用池化,保持了原始尺寸。提供了Pytorch和Keras两种实现方式,并指出ConvMixer在小数据集上的表现优于ViT。
本文介绍了ConvMixer模型,它是对Vision Transformer和MLP Mixer的融合,通过深度可分离卷积进行特征混合。研究发现,大卷积核能提升模型性能,且ConvMixer在网络结构上不使用池化,保持了原始尺寸。提供了Pytorch和Keras两种实现方式,并指出ConvMixer在小数据集上的表现优于ViT。
前言
卷积神经网络已经占据计算机视觉任务多年。近几年来,基于Transformer结构的模型(例如ViT(Vision Transformer))在很多场景中的性能已经超过了之前的卷积网络。
因为ViTs系列的模型需要将图片分成一个个的patch,再将patch 展平,输入到网络去寻找特征。下面是动画演示: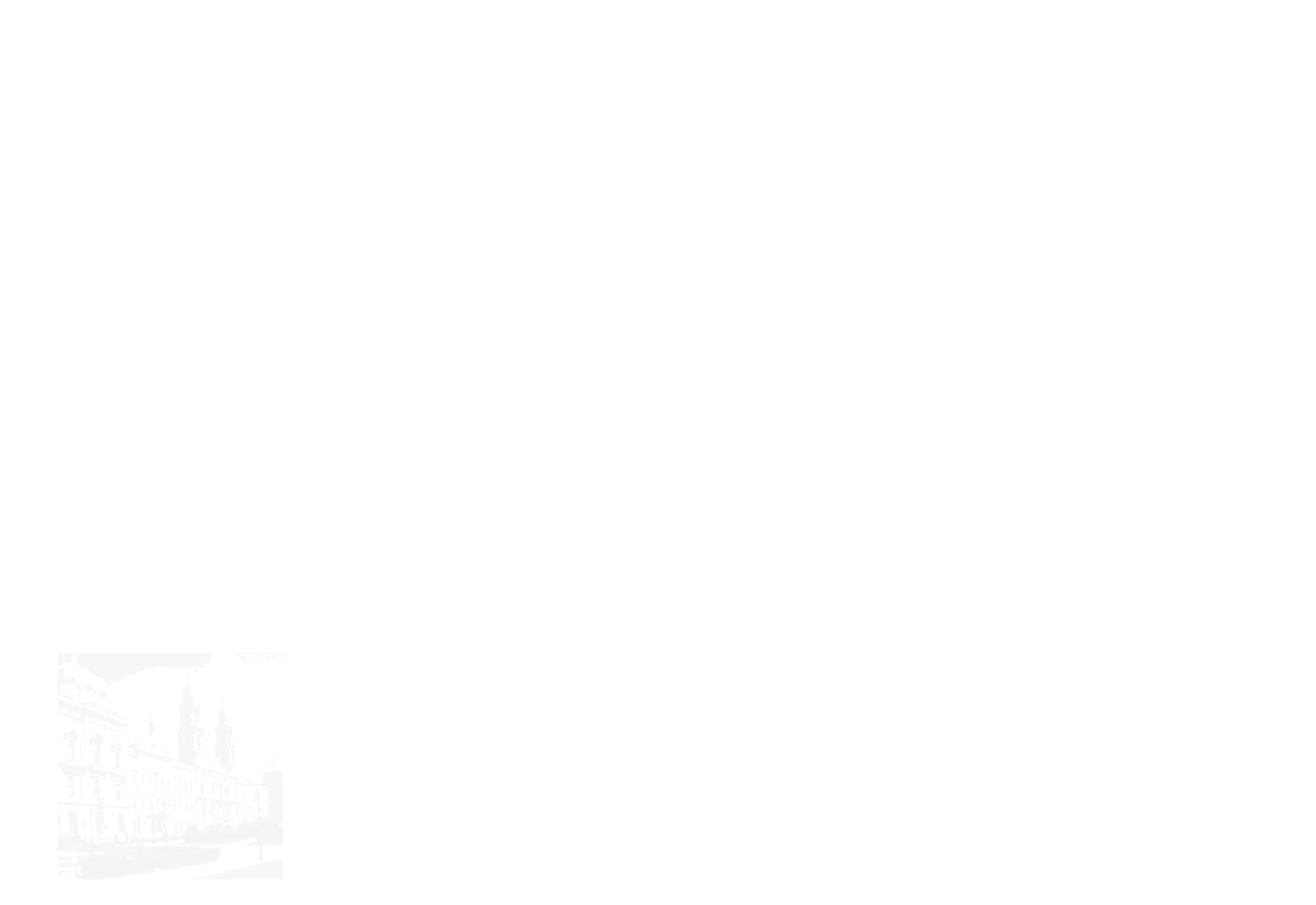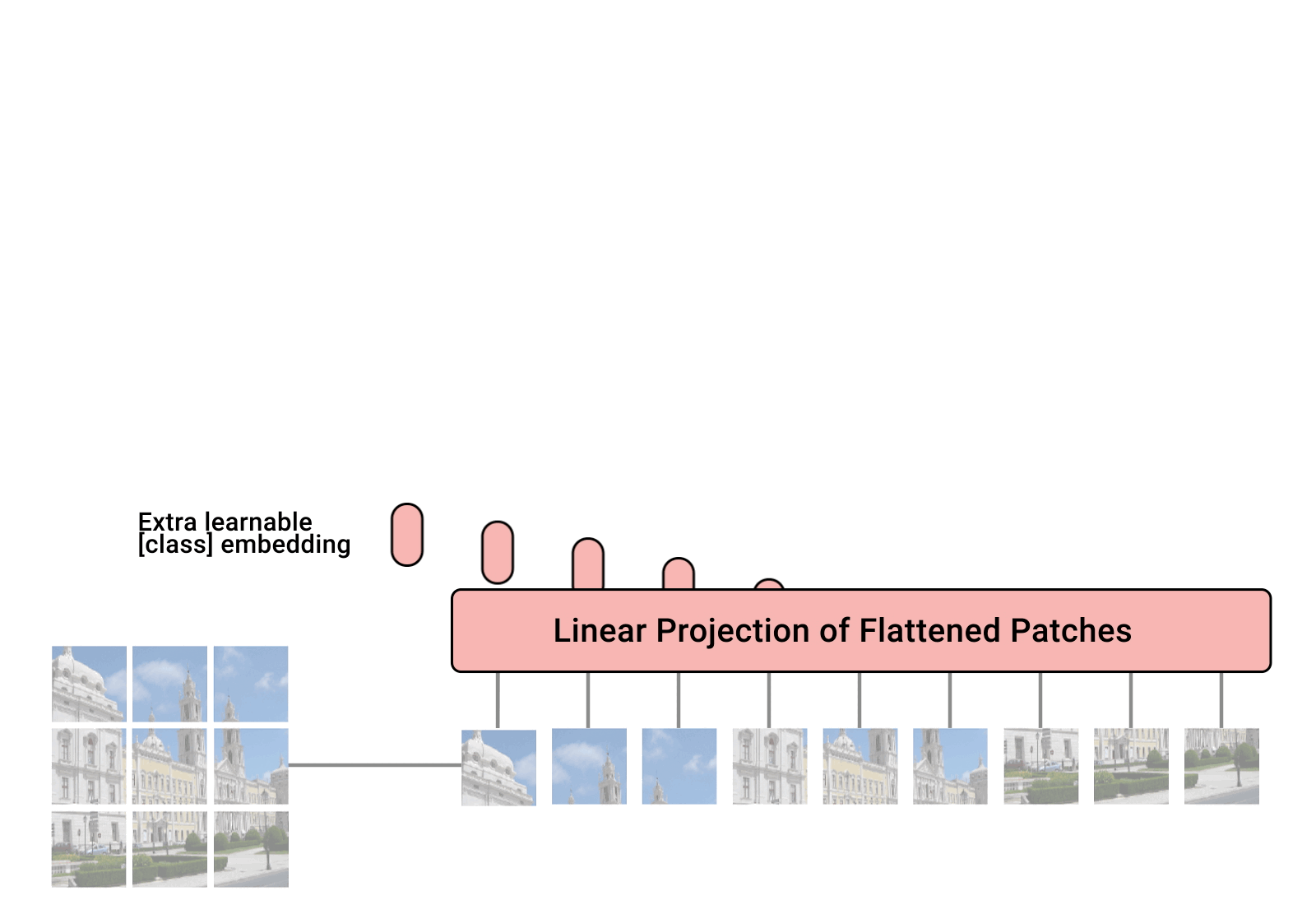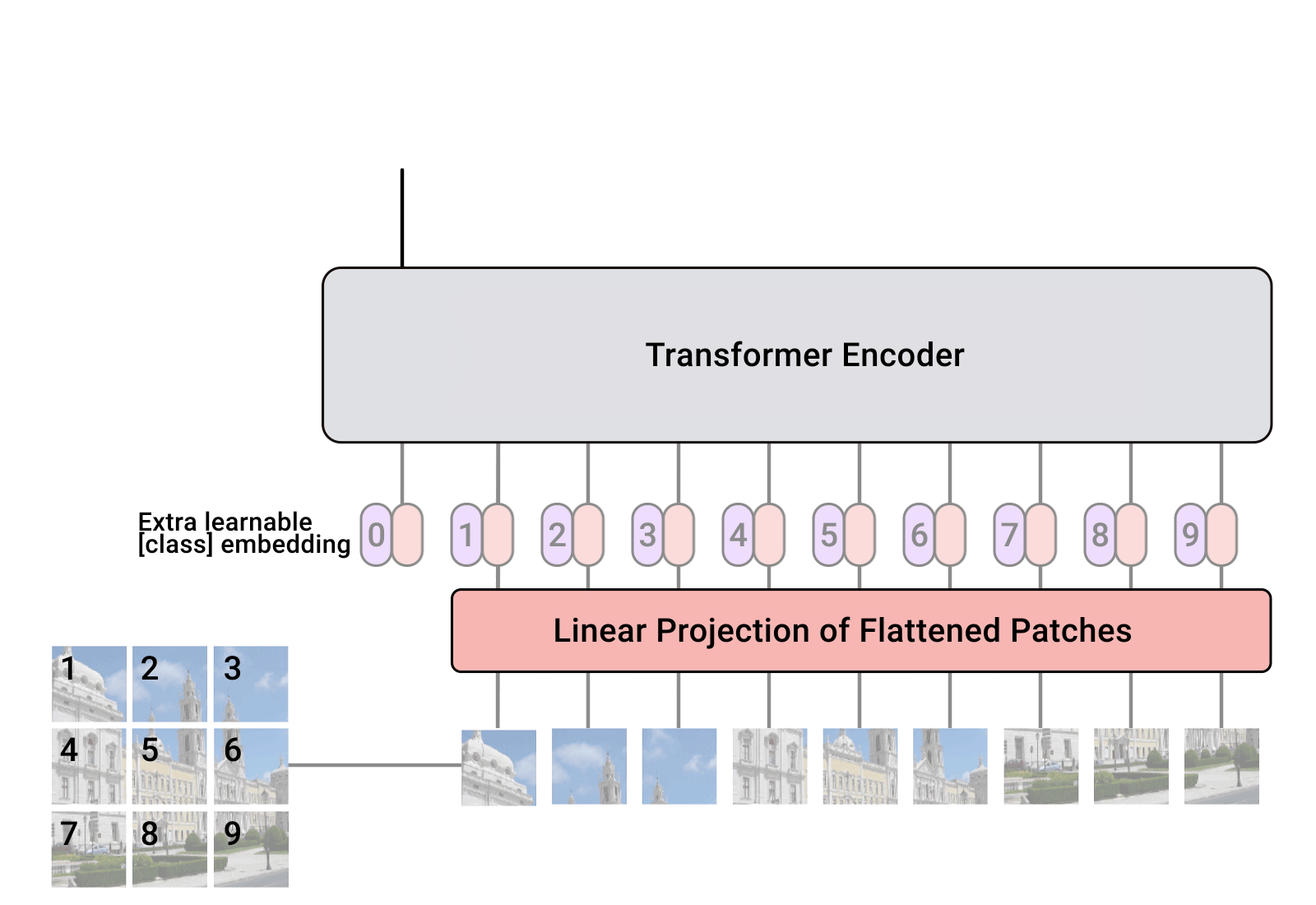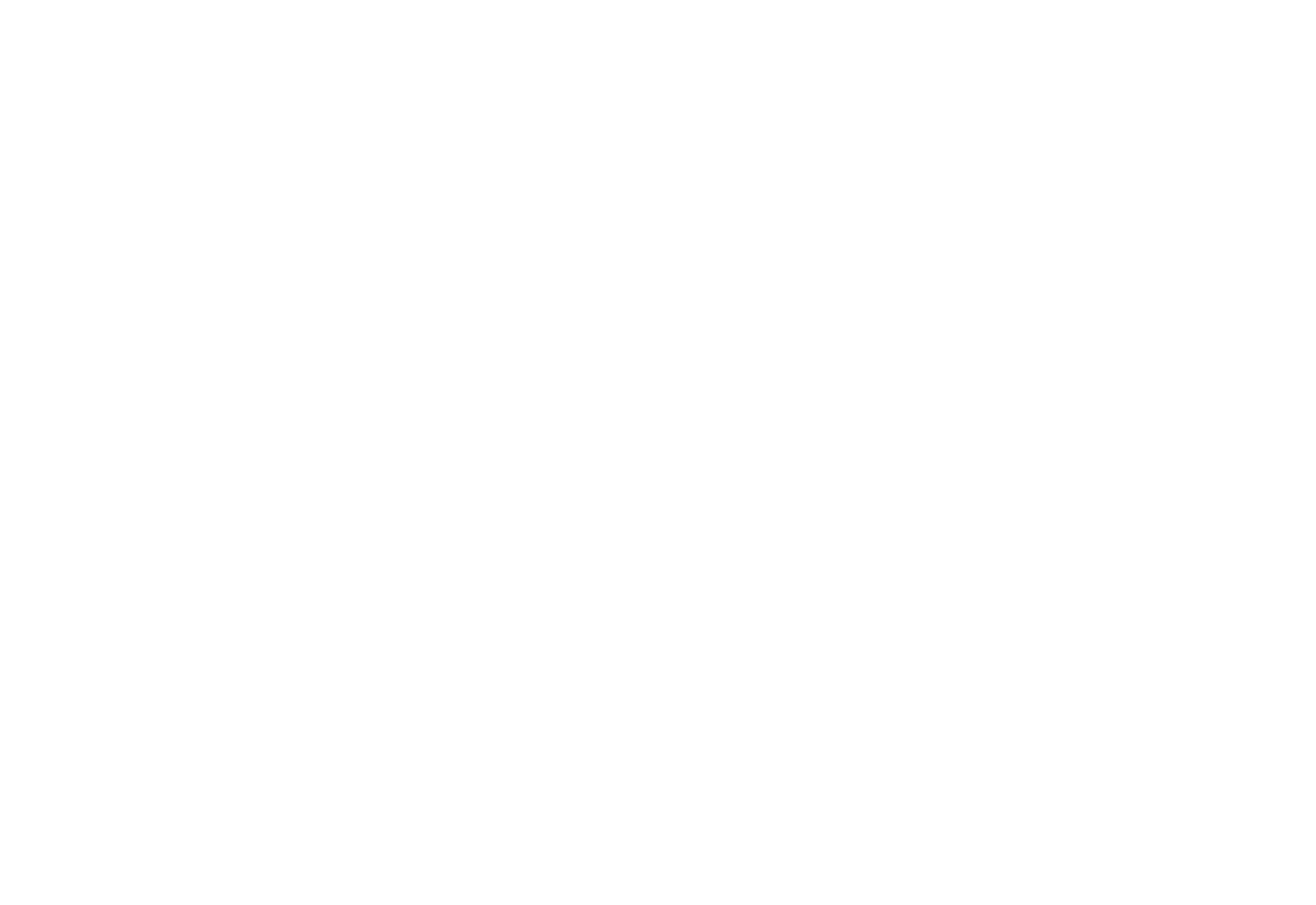
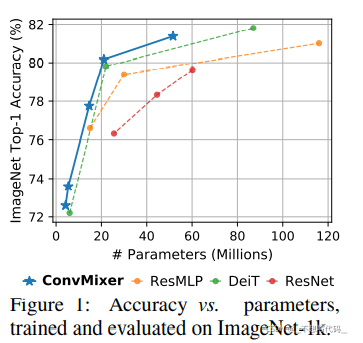
Conv Mixer 这篇文章提出的初衷是想去弄清楚,ViT系列模型表现优越,到底是图片分块的功劳 还是网络中Attention的功劳。于是作者就根据深度可分离卷积,在ViT 和 MLP Mixer 的启发中 设计了Conv Mixer。并且在表现上超越了一些ViT (某些ViT结构),MLP Mixer 和 ResNet。文章本身并没去追求模型的速度,和表现能力。
官方链接:
论文地址:https://openreview.net/pdf?id=TVHS5Y4dNvM
Github 地址:https://github.com/tmp-iclr/convmixer
官方给的代码有点难懂,所以这里我给它重构了一下。看起来通俗易懂
GitHub 地址(只含tf torch 模型代码):https://github.com/jiantenggei/ConvMixer
新版仓库(仅torch 可训练,eval top1 and top5):https://github.com/jiantenggei/torch-classification
一、什么是ConvMixer?
ConvMixer,取名上是根据MLP Mixer 来取名 。在思想上 与 ViT 和 MLP Mixer 一致,都是把,通过卷积映射成一个一个的特征块 输入到网络中。网络也不会通过下采样( 池化) 来改变输出的维度。整个网络结构通过传统的卷积来实现。
如下图所示:
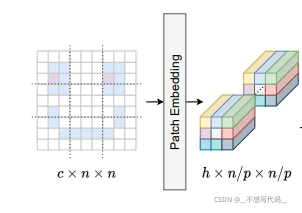
表面上Vit 和MLP-Mixer 不包含卷积,但大多数实现方式在 embedding时,都会采用卷积。
c代表原图片的通道,h代表hidden_dim 也就是隐藏层维度,n表示原图像的长宽,p代表patch_size。
1.网络结构图:
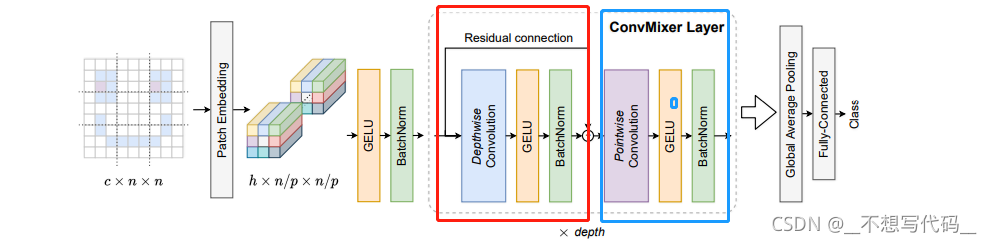
这就是ConvMixer的网络结构图,结构很简单。在ConvMixer Layer 中, 使用了深度可分离卷积,GELU 激活函数,逐点卷积。
论文中将图中红色部 称为 “channel wise mixing” 蓝色部分称为 "spatial mixing"
论文得到的结论是当深度可分离卷积部分的卷积核越大,模型的性能越好。
文章最后也认为,ViT 表现如此优越 是因为patch embedding (图片分块)的原因。
作者认为 patch embedding 操作就能完成神经网络的所有下采样过程,降低了图片的分辨率,增加了感受野,更容易找到远处的空间信息。从而模型表现良好
二、实现步骤
1.Pytorch实现
首先我们来定义 ConvMixer Layer 结构,代码如下所示:
class ConvMixerLayer(nn.Module):
def __init__(self,dim,kernel_size = 9):
super().__init__()
#残差结构
self.Resnet = nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding='same'),
nn.GELU(),
nn.BatchNorm2d(dim)
)
#逐点卷积
self.Conv_1x1 = nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
)
def forward(self,x):
x = x +self.Resnet(x)
x = self.Conv_1x1(x)
return x
实现过程非常简单,文章中的使用的是9x9的卷积核
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











